И, наконец, первый способ - описание
Если вы не знаете с чего начать, подсмотрите соответствующий набор в keymap. Или попробуйте "вычислить" его "вручную" через rules/model/layout. (Подробнее об этом можно прочитать в "Примеры: Где будем экспериментировать?")
Могу посоветовать
- для keycodes выбрать файл xfree86; - для types и compat подойдут файлы default ("по умолчанию") или complete ("полная"); - geometry, скорее всего, "pc", а количество кнопок задается названием блока в файле pc - pc(pc101), pc(pc102), pc(pc104). (Полный список "геометрий" в файле {XKBROOT}/geometry.dir.)
А вот на symbols обратите особое внимание. Файл symbols/ru описывает только "буквенные" клавиши. Если вы укажете только его, то у вас не будут работать все остальные кнопки (включая Enter, Shift/Ctrl/Alt, F1-F12 и т.д.).
Поэтому symbols должен состоять по крайней мере из двух файлов - en_US(pc101) (в скобках - тип клавиатуры) и, собственно, ru.
Полный список symbols в файле {XKBROOT}/symbols.dir.
Сюда же надо добавить и описание подходящего "переключателя рус/лат"
Описание всех возможных переключателей групп находится в файле {XKBROOT}/symbols/group.
Итак. Для первого метода список может выглядеть так -
XkbKeycodes "xfree86" XkbTypes "complete" XkbCompat "complete" XkbSymbols "en_US(pc101)+ru+group(caps_toggle)" XkbGeometry "pc(pc101)"
Если вам хочется дополнительные изменения "поведения" управляющих клавиш (то, что в третьем методе задается XkbOptions), то подсмотрите подходящую "добавку" в {XKBROOT}/rules/xfree86.lst и "приплюсуйте" ее в строчку XkbSymbols. Например,
XkbSymbols "en_US(pc101)+ru+group(shift_toggle)+ctrl(ctrl_ac)"
Иван Паскаль pascal@tsu.ru
И жили они долго и счастливо
Развитие индустрии сказалось и на Linux. Хотя и есть люди, которые ругают Linux (кстати, обоснованно) за шатание из стороны в сторону, постоянное переписывание уже готовых частей ядра, не достаточно быстрое добавление новых и необходимых, да мало ли за что... Юниксовая братия уже разделилась на 2 направления - BSD и SysV, которые различаются структурой ядра и методами межпроцессовых коммуникаций. Начинает оформляться течение, которое требует интеграции графической среды на уровень ядра, хотя бы на уровне модуля (к этим отщепенцам отношусь и я). И многое другое. Но в последние годы появилось новое идеологическое требование, которое - просто хорошо забытое старое.
Операционная система и программы должны минимально зависеть от архитектуры процессора. В идеале они не должны зависеть вообще.
А все-таки интересно, будет ли версия Microsoft Office для Linux?
Источник - LinuxBegin.ru
http://linuxbegin.ru
Адрес этой статьи:
http://linuxshop.ru/linuxbegin/article141.html
IE, Outlook, The Bat и все-все
Давайте себе представим такую ситуацию: дома была установлена Windows, ваши домашние ходили в Интернет, получали письма, отвечали на них, что-то там еще делали. Все было тихо и спокойно. Но в один прекрасный день вы решили попробовать что-то новое и поставили Linux. Настроили его, показали родным, но вашего энтузиазма никто не оценил 8-(. На восторженные рассказы о том, что эта операционная система может многое из того, что умеет Windows и за меньшие деньги. Вы слышите: «Да, конечно, – это интересно, а Internet Explorer там есть, а The Bat?» «Нет, – отвечаете вы, – но есть тоже неплохие браузеры: Konqueror, Galeon, Mozilla, Netscape и почтовых клиентов тоже много: KMail, Evolution, Balsa и т.д. и т.д.» В ответ: «Ага, а почему там нет The Bat?» (The Bat по праву можно считать культовым почтовым клиентом под Windows на территории СНГ). Да… Разговор немого со слепым. Не подумайте, что ситуация надумана – сам однажды попал в такую.
А теперь более серьезно. На мой взгляд, главное достоинство VMware, кроме возможности эмуляции ВМ, – это возможность «общения» guest-машины (виртуальной машины) с host-машиной (имеется ввиду ОС, из-под которой стартуют ВМ) при помощи виртуальных сетевых интерфейсов. В VMware существует три способа подключения к сети:
bridged networking – подключение к сети с использованием ethernet-адаптера host-машины; ip-адрес назначается из диапазона адресов, используемых в вашей локальной сети; при этом в сети видны две отдельные машины – host и guest. По умолчанию, для этого настраивается интерфейс vmnet0. host-only networking – подключение к виртуальной сети, где в качестве шлюза и DHCP-сервера для виртуальной сети выступает host-машина (можно, если хотите, не использовать DHCP, а назначить ip-адрес, самому взяв его из диапазона x.x.x.2-x.x.x.127, иначе вам будет автоматически присваиваться ip-адрес из диапазона x.x.x.128-x.x.x.254). По умолчанию, при первой настройке VMware Workstation для этих целей настраивается интерфейс vmnet1. Если вас это не устраивает, или вы хотите создать еще один, – запустите программу конфигурации VMware /usr/bin/vmware-config.pl, она предоставляет вам возможность сконфигурировать в общей сложности до ста (0-99) виртуальных интерфейсов. NAT device – (network address translation – трансляция сетевых адресов). По умолчанию используется интерфейс vmnet8. NAT чем-то похож на ip-маскарадинг. Вы можете использовать такое подключение для получения доступа к Интернет через host-машину (тоже самое можно проделать и с host-only подключением, но для этого надо установить proxy-сервер на host-машине и работать через него). Эта возможность появилась в VMware начиная с версии 3.0.
Для нашего случая подойдет третий вариант подключения к сети, как требующий меньших затрат. При настройке сети обратите внимание на диапазон адресов, в котором будет работать сетевой интерфейс. Скрипт конфигурации (vmware-config.pl) предлагает автоматически найти свободную подсеть. Как поступите – не имеет значение, но если вы забыли в каком адресном пространстве расположена виртуальная сеть, наберите команду: /sbin/ifconfig vmnet8 | grep inet
Увидите примерно следующее: inet addr:192.168.1.1 Bcast:192.168.1.255 Mask:255.255.255.0
Нужно помнить, что в случае с NAT адрес x.x.x.1 в подсети – это адрес host-машины. По адресу x.x.x.2 расположены шлюз и DHCP-сервер. Диапазон статических адресов x.x.x.3 – x.x.x.127, динамически назначаемых – x.x.x.128 – x.x.x.254. При настройке сетевого интерфейса Windows выберем первый свободный статический адрес x.x.x.3. Указываем адрес шлюза и настраиваем данные о DNS. В качестве DNS у нас будет фигурировать DNS провайдера. Если у вас на host-машине настроен DNS, то вы можете указывать при настройке guest-машины его данные.
Теперь подключитесь к своему провайдеру и попробуйте пропинговать какой-нибудь сайт «снаружи» находясь в ВМ. Например, SofTerra. Сперва попробуйте пинг на конкретный ip-адрес, потом на имя в Сети: ping 195.170.224.100 ping www.softerra.ru
Если не работает первый пинг, то вы неправильно указали ip-адрес шлюза или забыли его указать вообще. Если первый пинг проходит, а второй нет, то вы ошиблись при настройке данных о DNS. Если все работает, то вас можно поздравить с тем, что вы настроили свой собственный шлюз в Интернет. Все остальное по вкусу 8-).
Иерархия файловых систем
В предыдущей части статьи мы сознательно ограничивали рассмотрение только вопросами построения структуры каталогов и не касались (или почти не касались) вопроса о том, как разместить эти каталоги в различных файловых системах. Теперь давайте рассмотрим этот вопрос отдельно.
В тексте стандарта FHS довольно мало рекомендаций на этот счет. И относятся они в основном к корневой файловой системе. В соответствии со стандартом содержимое этой файловой системы должно быть достаточным для того, чтобы обеспечить загрузку операционной системы, а также восстановление или ремонт этой системы при возникновении различных проблем и сбоев.
Чтобы обеспечить процесс загрузки, в корневой файловой системе должна находиться информация для загрузчика и основные файлы, необходимые в процессе старта системы (например, ядро ОС). Здесь же должны размещаться файлы конфигурации и все, что необходимо для монтирования других файловых систем, включая такие утилиты, как mount.
Для того, чтобы обеспечить возможность восстановления системы после сбоев, в корневой файловой системе должны присутствовать все утилиты, необходимые опытному администратору для диагностирования проблем и реконструкции системы после любой аварийной ситуации.
Здесь же должны быть расположены и те утилиты, которые необходимы для восстановления данных с резервных копий (с дискет, магнитных лент и т.п.).
По нескольким причинам размер корневой файловой системы желательно сделать достаточно малым.
Иногда приходится монтировать корневую файловую систему с носителя очень малого объема.
Корневая файловая система обычно содержит файлы, специфичные для конкретной системы. К таким файлам относится, например, ядро системы, файл, в котором сохраняется имя хоста, другие конфигурационные файлы. Это все файлы, относящиеся к числу неразделяемых. Их немного по сравнению с общим числом файлов, поэтому для них не требуется больших объемов дискового пространства. Разделяемые файлы можно разместить на сетевых дисках. И это позволяет использовать в качестве рабочих станций в сети компьютеры с маленькими по объему локальными жесткими дисками.
Дефекты диска, на котором располагается корневая файловая система, обычно создают проблемы гораздо более серьезные, чем сбои в работе других файловых систем. А маленькая корневая файловая система менее подвержена разрушению в случае физических сбоев, и ее легче восстановить после сбоя.
В общем, из чтения текста стандарта можно сделать вывод о том, что в корневой файловой системе обязательно должны целиком (то есть со всем их содержимым) располагаться каталоги /bin, /dev, /etc, /lib, /sbin и, возможно, /root.
Каталог /boot в силу аппаратных ограничений может оказаться необходимым разместить на отдельном разделе диска, расположенном целиком в пределах первых 1024 цилиндров загрузочного диска. Еще одной причиной размещения этого каталога в отдельной файловой системе может оказаться использование файловой системы ReiserFS: ядро не всегда может загружаться из раздела с такой файловой системой [2].
Остальные подкаталоги корневого каталога (home, mnt, opt, tmp, usr, var) могут размещаться в других файловых системах (на других разделах или дисках). Более того, в стандарте явно постулируется, что в каталогах /usr, /opt и /var размещаются такие файлы, которые могут располагаться в других разделах диска или в других файловых системах. Разработчики стандарта советуют в том случае, когда /var не может быть размещен в отдельном разделе диска, переместить каталог /var из корневого раздела в раздел с каталогом /usr. (Иногда это делается с целью уменьшения размера корневого раздела или когда в корневом разделе остается слишком мало места). Однако, /var нельзя делать ссылкой на /usr потому что это затрудняет разделение /usr и /var и может привести к конфликту имен. Лучше уж сделать /var ссылкой на /usr/var.
Что касается каталога /home, то его размещение в отдельном разделе диска в стандарте прямо не оговаривается, но как бы молча подразумевается. Впрочем, такое решение легко обосновать и без ссылок на стандарт. Причем оно не зависит от того, идет ли речь о персональном компьютере или о файловом, предположим, сервере. В обоснование этого вывода можно привести следующие доводы. Рано или поздно, но систему придется переустанавливать или обновлять. Если раздел с программным обеспечением при этом практически безболезненно можно отформатировать (поскольку дистрибутив Linux содержит, как правило, обновленные версии практически всех пакетов ПО и все будет заново поставлено), то домашние каталоги пользователей из дистрибутива не обновишь. Представьте, что ваш домашний каталог администратор почистит без вашего ведома. Так что уж лучше каталог /home не трогать. Поэтому стоит разместить домашние каталоги пользователей в отдельной файловой системе и после переустановки ОС заново смонтировать ее в каталог /home.
Что касается каталога /usr, то, если исходить из приведенной в стандарте рекомендации минимизации корневого раздела, его, вслед за /home, надо выносить в отдельный раздел. Дело в том, что если исключить домашние каталоги пользователей, то именно этот каталог по объему составляет более 90% объема всех каталогов. Это и не удивительно - в нем установлено все программное обеспечение.
Пожалуй, это все, что можно извлечь из текста стандарта относительно разнесения каталогов по разным файловым системам. А уж решение о том, как именно разбить диск на разделы принимает администратор каждой конкретной системы самостоятельно (можно еще учесть рекомендации статей [2,3]).
В заключение хочется еще раз отметить, что речь в статье идет только о требованиях и рекомендациях стандарта FHS, причем стандарта, разработанного с ориентацией на операционные системы Linux и BSD. Даже конкретные дистрибутивы Linux далеко не во всем следуют этому стандарту. Например, в Red Hat Linux версий 7.3 и 8.0 каталог /etc/opt хотя и создан, но пуст, а конфигурационные каталоги пакетов размещаются непосредственно в /etc. Аналогичная ситуация с каталогом /opt - он тоже пуст, а все дополнительное ПО устанавливается, по-видимому, в /usr (по крайней мере то ПО, которое разворачивается из rpm-пакетов). Можно указать и другие отклонения от стандарта. Но все же в основном структура каталогов выдерживается в соответствии с FHS, и я надеюсь, что чем дальше, тем больше будет к нему приближаться. Так что знакомство с этим стандартом безусловно полезно всем пользователям Linux, а тем более разработчикам программного обеспечения для этой операционной системы.
II Файловые системы Linux Сухая теория
С даты в далеком прошлом, когда компьютерные системы впервые начали читать и писать на магнитные носители, гарантирование целостности файлов и (позднее) директорий на этих устройства стало настоящей занозой для системных администраторов. На системном уровне, все данные на компьютере существуют как блоки данных на неком устройстве хранения, организованных с помощью специальных структур данных в разделы (логические наборы на устройстве хранения), которые в свою очередь организованы в файлы, директории и неиспользуемое (свободное) пространство.
Файловые системы созданы на разделах диска для упрощения хранения и организации данных в форме файлов и директорий. Linux, как Unix система, использует иерархическую файловую систему составленную из файлов и директорий, которые соответственно содержат либо файлы либо каталоги. Файлы и директории в файловой системе Linux становятся доступным пользователю путем их монтирования (команда «mount»), которая обычно является частью процесса загрузки системы. Список файловых систем доступных для использования хранится в файле /etc/fstab (FileSystem TABle). Список файловых систем не смонтированных в данные момент системой хранится в файле /etc/mtab (Mount TABle).
В момент монтирования файловой системы в процессе загрузки, бит в заголовке («чистый бит» / «clean bit») стирается, это означает что файловая система используется, и что структуры данных используемые для управления размещением и организации файлов и директорий, в данной файловой системы могут быть изменены.
Файловая система расценивается как целостная если все блоки данных в ней либо используются, либо свободны; каждый размещенный блок данных занят одним и только одним файлом или директорией; все файлы и директории могут быть доступны после обработки серии других директорий в файловой системе. Когда система Linux намеренно прекращает работу используя команды оператора, все файловые системы размонтируются. Размонтирование файловой системы в процессе завершения работы устанавливает «чистый бит» в заголовок файловой системы, указывая на то, что файловая система была размонтирована должным образом и, тем самым, может рассматриваться как целостная.
Года отладки и переработки файловой системы и использование улучшенных алгоритмов для записи данных на диск в большой степени уменьшили повреждение данных вызываемых приложениями или самим ядром Linux, но устранение повреждения и потери данных в связи с отключением питания и другими системными проблемами до сих пор является сложной задачей. В случае аварийной остановки или простого отключения Linux системы без использования стандартных процедур остановки работы «чистый бит» в заголовке файловой системы не устанавливается. При следующей загрузке системы, процесс монтировки обнаруживает, что система не маркирована как «чистая», и физически проверяет ее целостность использую Linux/Unix утилиту проверки файловой системы 'fsck' (File System ChecK).
III Что такое журналируемая файловая система?
Запуск проверки системы (fsck) на больших файловых системах может занять много времени, что очень плохо, учитывая сегодняшние высоко скоростные системы. Причиной, по которой целостность отсутствует в файловой системе, может являться не корректное размонтирование, например в момент прекращения работы на диск велась запись. Приложения могли обновлять данные, содержащиеся в файлах и система могла обновлять мета-данные файловой системы, которые являются «данными о данных файловой системы», иными словами, информация о том какие блоки связаны с какими файлами, какие файлы размещены в каких директориях и тому подобное. Ошибки (отсутствие целостности) в файлах данных – это плохо, но куда хуже ошибки в мета-данных файловой системы, что может привести к потерям файлов и другим серьезным проблемам.
Для минимизации проблем связанных с целостностью и минимизации времени перезапуска системы, журналируемая файловая система хранит список изменений, которые она будут проводить с файловой системой перед фактической записью изменений. Эти записи хранятся в отдельной части файловой системы, называемой «журналом» или «логом». Как только эти записи журнала (лога) безопасно записаны, журналируемая файловая система вносит эти изменения в файловую систему и затем удаляет эти записи из «лога» (журнала регистраций). Записи журнала организованы в наборы связанных изменений файловой системы, что очень похоже на то, как изменения добавляемые в базу данных организованны в транзакции.
Журналируемая файловая система увеличивает вероятность целостности, потому что записи в лог-файл ведутся до проведения изменений файловой системы, и потому что файловая система хранит эти записи до тех пор, пока они не будут целиком и безопасно применены к файловой системе. При перезагрузке компьютера, который использует журналируемую файловую систему, программа монтирования может гарантировать целостность файловой системы простой проверкой лог-файла на наличие ожидаемых, но не произведенных изменений и записью их в файловую систему. В большинстве случаев, системе не нужно проводить проверку целостности файловой системы, а это означает, что компьютер использующий журналируемую файловую систему будет доступен для работы практически сразу после перезагрузки. Соответственно шансы потери данных в связи с проблемами в файловой системе значительно снижаются.
Существует несколько журналируемых файловых систем доступных для Linux. Наиболее известные из них: XFS, журналируемая файловая система разработанная Silicon Graphics, но сейчас выпущенная открытым кодом (open source); RaiserFS, журналируемая файловая система разработанная специально для Linux; JFS, журналируемая файловая система первоначально разработанная IBM, но сейчас выпущенная как открытый код; ext3 – файловая система разработанная доктором Стефаном Твиди (Stephan Tweedie) в Red Hat, и несколько других систем.
"Иксовая" setlocale()
Дело в том, что процедуры Xlib для того, чтобы узнать название "текущей locale" используют "третью форму" вызова "libc'ишной" setlocale().
Но, на тот случай, если в "системной" libc нет такой процедуры, в Xlib
существует "заглушка" - (вообще-то, она называется_Xsetlocale()), которая может вызываться вместо системной setlocale().
Для того, чтобы работала "заглушка", библиотека Xlib должна быть собрана с "опцией"
#define X_LOCALE
(при этом вызовы setlocale() автоматически заменяются на вызовы _Xsetlocale())
Надо заметить, что "иксовая" setlocale(), хотя и вызывается точно так же, как и "системная" (те же три формы вызова), имеет некоторые отличия во "второй форме" (наиболее популярном способе установки "текущей locale").
Категории (первый аргумент) могут быть только LC_ALL или LC_CTYPE. При этом название locale она пытается взять из переменных окружения LC_CTYPE и, если не получилось - LANG. На переменную окружения LC_ALL она внимания не обращает (даже если первый аргумент - "категория" LC_ALL).
Ну и, естественно, эта "заглушка" устанавливает только "иксовые" параметры locale, а не "libc'ишные".
Так вот. Проблемы могут возникнуть, если у вас в системе Xlib почему-то собрана с "опцией" X_LOCALE, хотя в libc соответствующая процедура имеется.
Тогда вызов setlocale() из libc запомнит название locale в своих внутренних переменных, а процедуры Xlib будут спрашивать "текущую locale" у своей "заглушки", которая, естественно, ее не знает.
Если уж у вас Xlib собрана с X_LOCALE, то и программы должны вызывать не "системную" setlocale(), а "иксовую".
Для этого перед вызовом setlocale() должно стоять
#define X_LOCALE #include <X11/Xlocale.h>
Если Xlib "нормальная" (то есть ориентруется на "системную" setlocale), то этих строчек не нужно. (Хотя, конечно, понадобится #include <locale.h>)
Именованные каналы
Канал - это простейшее, но очень удобное и широко применяемое средство обмена информацией между процессами. Все, что один процесс помещает в канал (буквально - в "трубу"), другой может оттуда прочитать. Если два процесса, обменивающиеся информацией, порождены одним и тем же родительским процессом (а так чаще всего и происходит), канал может быть неименованным. В противном случае требуется создать именованный канал, что можно сделать с помощью программы mkfifo. При этом собственно файл именованного канала участвует только в инициации обмена данными.
Индикаторы
Как известно, на клавиатуре кроме "кнопок" имеется несколько "лампочек"- индикаторов. Управление этими индикаторами тоже входит в обязанности XKB.
В XKB может существовать до 32 индикаторов.
Естественно, на клавиатуре отображаются только первые 3-4 из них. Эти индикаторы называются в XKB "физическими", а остальные - "виртуальными". Состояние виртуальных модификаторов может быть считано из XKB и отображаться на экране специальными программами (xkbvleds, mxkbledpanel).
Каждый индикатор может быть связан с компонентом "состояниея XKB" (модификатором, номером группы, "управляющим флагом") и, соответственно, состояние индикатора будет автоматически отражать состояние своего "компонента состояния XKB".
Причем, в XKB существуют специальные запросы, которыми прикладная программа может управлять состянием какого-нибудь индикатора ("зажигать"/"гасить" его). Заметьте, речь идет о том, что программа может просто включать/выключать "лампочку", а не менять состояние клавиатуры, которое "отслеживается" этой "лампочкой".
Поэтому, с каждым индикатором связан набор флагов, который определяет
можно ли прикладной программе управлять самим этим индикатором (или для его включения/выключения обязательно надо изменить "состояние клавиатуры"; "привязан" ли этот индикатор к "состоянию клавиатуры" или он включается/выключается только прикладными программами; и, наконец, будет ли такое включение/выключение иметь "обратную связь". То есть, можно настроить индикаторы так, что включение/выключение "лампочки" прикладной программой будет вызывать автоматически соответствующие изменения "состояния клавиатуры" (модификаторов, номера группы, управляющих флагов).
Индикаторы-переключатели
Несмотря на то, что XKB сам может поддерживать несколько (до четырех) различных раскладок и легко переключать их "на ходу", ему очень не хватает подходящей программы для удобной манипуляции раскладками и отображения текущего состояния ("лампочек" на клавиатуре явно недостаточно для индикации состояния, если раскладок больше двух).
Кроме того, большинство пользователей уже привыкло к "индикаторам-переключателям" (типа xrus), которые позволяют переключать раскладки не только с клавиатуры, но и "щелчком мыши" и, к тому же, отображать "текущий язык" иконкой на дисплее.
Что же из таких программ можно посоветовать для работы "в паре с XKB"?
Надо заметить, что популярные "переключалки" типа xruskb, xes, cyrx, kikbd
(кого я еще забыл упомянуть?) для этого плохо подходят.
Во-первых, они используют раскладки "в старом стиле", то есть не с кодами Cyrillic, а "западноевропейскими" буквами. А это вызывает проблемы у "правильных" программ при корректно установленной locale (подробнее об этом в "Почему руссификация через XKB не работает?").
А во-вторых, все они не используют возможности XKB для переключения раскладок, и "на каждое телодвижение" сами перезагружают раскладки в X-сервер.
"Настоящими" XKB-переключателями являются -
kkb - http://www.logic.ru/peter
http://linuxfan.com/~sparrow/software/
http://linux.piter-press.ru/fookb/
http://www.tsu.ru/~pascal/other/xxkb/
Не желая никого обидеть :-), все-таки выскажу некоторые замечания относительно этих программ (возможно - несколько запоздалые).
Информация о системе
pwd
Выводит на экран имя рабочей директории.
hostname
Выводит на экран имя локальной машины (машины, на которой вы работаете). Используйте netconf (как "root") для изменения этого имени.
whoami
Печатает ваше имя пользователя.
id имя_пользователя
Печатает пользовательский идентификатор (uid) и идентификатор группы (gid), а так же - эффективный идентификатор (если он отличается от реального) и дополнительные группы.
date
Выводит на экран текущее время операционной системы, время и часовой пояс. Для стандартного ISO-формата: date -Iseconds
Я могу установить дату и время 2000-12-31 23:57, используя команду: date 123123572000
или используя две команды (проще запомнить):
date --set 2000-12-31
date --set 23:57:00
Для установки аппаратных часов (BIOS) на системное время (Linux), я могу использовать команду (как "root"): setclock Международный (ISO 8601) стандартный формат для цифровых даты/времени имеет следующую форму: 2001-01-31 (по умолчанию в Linux). Вы можете быть более точными, если хотите, например: 2001-01-31 23:59:59.999-05:00 (представляет одну миллисекунду до 1 февраля 2001, во временной зоне на 5 часов после Гринвича (Universal Coordinated Time (UTC))) . Более "соответстует законам" следующее представление: 20010131T235959,999-0500. Стандарты можно изучить по адресу ftp://ftp.qsl.net/pub/g1smd/8601v03.pdf.time
Определяет количество времени, которое занимает выполнение другого процесса. Не перепутайте с командой date (см. предыдущий пункт). Например, я могу замерить время вывода списка файлов текущей директории: time ls. Или я могу проверить функцию time sleep 10. (Замерить время выполнения команды, вызывающей десятисекундную задержку).
clock
hwclock
(Две команды, используйте любую). Берет системные дату/время из аппаратных часов (реального времени, BIOS). Вы так же можете использовать эти команды для установки системных часов, но setclock может быть проще (см. выше на 2 команды). Пример: hwclock --systohc --utc устанавливает аппаратные часы (в UTC) из системных часов.
who
Определяет пользователей, зарегистрированных в системе.
w
Определяет пользователей, зарегистрированных в системе + смотрит, что они делают, используемое ими процессорное время, и т.д. Удобная команда для контроля безопасности.
rwho -a
(=remote who) Определяет пользователей, зарегистрированных на других компьютерах вашей сети. Сервис rwho должен быть включен для выполнения этой команды. Если нет - выполните setup (в RedHat) как "root" для разрешения "rwho".
finger имя_пользователя
Системная информация о пользователе. Попробуйте: finger root . Можно использовать finger для любого сетевого компьютера, который предоставляет службу finger во внешний мир. Например, я могу попробовать: finger@finger.kernel.org
last
Показывает список пользователей, входивших в вашу систему в последнее время. Действительно неплохая идея - проверять этот список в качестве меры предосторожности в вашей системе.
lastb
("=last bad") Показывает последние плохие (неудавшиеся) попытки входа в систему. Это не работает в моей системе, но в ней можно сделать так: touch /var/log/btmp "Весьма разумно, что /var/log/btmp отсутствует во многих разумных вариантах установки - это файл для всеобщего чтения, содержащий ошибки входа в систему. Поскольку одна из наиболее распространенных ошибок входа в систему состоит в печати пароля вместо имени пользователя, /var/log/btmp - просто подарок для хакера." (Спасибо Брюсу Ричардсону (Bruce Richardson)). Возможно, проблема может быть решена изменением прав доступа к файлу для того, чтобы только "root" мог использовать "lastb":
chmod o-r /var/log/btmphistory | more
Показывает последние (1000 или более) команд, выполненных в командной строке текущим пользователем. Выражение "| more" позволяет делать остановки после каждого заполнения экрана выводом команды. Для того, чтобы посмотреть, что другой пользователь делает в вашей системе, войдите как "root" и просмотрите "history". Она хранится в файле .bash_history в домашней директории пользователя (правда, пользователь так же может легко ее изменить).
uptime
Показывает количество времени, прошедшее с последней перезагрузки.
ps
(="print status(печатай состояние)" или "process status(состояние процессов)") Список процессов, выполняемых текущим пользователем.
ps axu | more
Показывает список всех процессов, исполняемых в данный момент, даже если они запущены не с текущего терминала, вместе с именами пользователей, запустивших эти процессы.
top
Показывает список процессов, выполняемых в системе в данный момент, отсортированный по использованию процессора (верхнюю часть списка). Нажмите <Ctrl>c, когда просмотрите. PID = идентификатор процесса(process identification).
USER=имя пользователя - владельца процесса (запустившего процесс).
PRI=приоритет(priority) процесса (чем больше число, тем ниже приоритет, нормально - 0, высший приоритет=-20, низший=20.
NI=уровень любезности(niceness level) (т.е., если процесс пытается быть любезным, уменьшая свой приоритет на указанное число). Чем больше число, тем больше любезность процесса (т.е., приоритет ниже).
SIZE=килобайты кода+данных+стека занимаемых программой.
RSS=килобайты физической (на микросхеме) памяти, занимаемой процессом.
SHARE=килобайты памяти, разделяемой с другими процессами.
STAT=состояние процесса: S-спит(sleeping), R-выполняется(running), T-приостановлен(stopped) или трассируется(traced), D-беспробудно спит(uniterruptable sleep), Z=зомби, не жив не мертв(zombie).
%CPU=процент использования процессора (с момента последнего обновления экрана).
%MEM=процент использования физической памяти.
TIME=общее время использования процессора (с момента старта).
COMMAND=командная строка, запустившая процесс (поосторожнее с паролями, и т.п., в командной строке, потому что все, кто наберет "top", смогут это увидеть!gtop
ktop
(в X терминале) Два графических варианта top. Мне нравится больше gtop (устанавливается с gnome). В KDE, ktop также доступен из "K"меню в "System"-"Task Manager".
uname -a
(= "Имя Юникс (Unix name)" с параметром "все(all)") Информация о вашем (локальном) сервере. Я могу также использовать guname (в терминале X-windows) для просмотра в более приятном виде.
XFree86 -version
Покажет версию X-windows, установленную в моей системе.
cat /etc/issue
Проверяет, какой дистрибутив вы используете. Вы можете поместить ваше собственное текстовое сообщение--оно будет показано при входе в систему. Но более правильно помещать такие сообщения в файл /etc/motd ("motd"="сообщение дня").
free
Информация о памяти (в килобайтах). "Shared(Разделяемая)" память - это память, которая может разделяться между процессами (например, исполняемый код можно "разделять"). "Buffered(Буферная)" и "cashed(Кэшируемая)" память - это память, хранящая наиболее часто используемые части наиболее часто используемых файлов -- она может сократиться, если процессы потребуют больше памяти.
df -h
(=disk free(Свободное место на диске)) Показывает информацию о всех файловых системах в форме, доступной для человека.
du / -bh | more
(=disk usage(использование диска)) Показывает дисковую память, занимаемую всеми поддиректории, начиная с "/" (корневой) директории (в доступной для человека форме).
cat /proc/cpuinfo
Информация о процессоре(Cpu info)--показывает содержимое файла cpuinfo. Заметьте, что все файлы в директории /proc -- это не настоящие файлы, а просто удобная форма доступа к системной информации.
cat /proc/interrupts
Список используемых прерываний. Может потребоваться для просмотра перед установкой нового оборудования.
cat /proc/version
Версия Linux и другая информация.
cat /proc/filesystems
Показывает список файловых систем, используемых в текущий момент.
cat /etc/printcap |more
Показывает установки принтеров.
lsmod
(= "список модулей(list modules)". Как "root". Используем /sbin/lsmod для просмотра в режиме обычного пользователя.) Показывает загруженные в текущее время модули ядра.
set|more
Показывет значения переменных окружения пользователя (всех). Обычно вывод занимает более одного экрана.
echo $PATH
Показывает содержимое переменной окружения "PATH". Эта команда может быть использована для просмотра других переменных окружения. Используйте set для просмотра всех значений (см. предыдущую команду).
dmesg | less
Печатает сообщения ядра (содержимое так называемого буфера ядра). Нажмите "q" для выхода из "less". Используйте less /var/log/dmesg чтобы увидеть, что "dmesg" поместил в этот файл при последней загрузке системы.
chage -l my_login_name
Посмотреть информацию о времени истечения моего пароля.
quota
Посмотреть мою дисковую квоту (предел использования диска).
sysctl -a |more
Показывает все конфигурируемые параметры ядра Linux.
runlevel
Показывает предыдущий и текущий уровни выполнения (runlevel). Вывод "N5" значит: "нет предыдущего уровня выполнения" и "5 текущий уровень выполнения". Для смены уровня выполнения используйте "init". Например, init 1 переводит систему в однопользовательский режим. Уровень выполнения - это режим операций в Linux. Уровень выполнения может быть изменен "на лету", используя команду init. Например, init 3 (как "root") переведет меня на уровень выполнения 3. Следующие уровни выполнения являются стандартными:
0 - Остановка системы(halt) (Не нужно ставить этот уровень по умолчанию :)
1 - Однопользовательский режим
2 - Многопользовательский режим, без NFS (То же что и 3, если у вас нет сети)
3 - Полностью многопользовательский режим
4 - не используется
5 - X11
6 - перезагрузка(reboot) (Не нужно ставить этот уровень по умолчанию :)
Уровень выполнения системы по умолчанию устанавливается в: /etc/inittab .sar
Просмотр информации о системной активности, представленной в файле (/var/log/sarxx, где xx - номер текущего дня). sar может показать много вариантов системной информации, включая статистику загруженности процессора, статистику ввода/вывода, и статистику сетевого траффика за текущий день и (обычно) за несколько предыдущих.
Инициализация при входе в систему графического рабочего стола
Если мы перезагрузим компьютер, то процесс init автоматически войдет в систему пользователем fred на первой виртуальной консоли и запустит командную оболочку -- шелл. Однако для запуска графического рабочего стола пользователь fred по-прежнему должен набрать команду startx сам, путем личного нажима на клавиши. Можно ли автоматизировать и это?
Если fred при входе в систему загружает оболочку /bin/bash, то первыми будут выполнятся команды, перечисленные в файле ~fred/.bash_profile. Вы можете добавить команду startx туда, но это вызовет проблемы, т.к. .bash_profile используется и в других ситуациях, таких, как вход в систему со второй виртуальной консоли или при открытии xterm. Вместо этого мы добавим в .bash_profile следующие строки:
if [ -z "$DISPLAY" ] && [ $(tty) == /dev/tty1 ]; then startx fi
При каждом новом заходе в систему с первой виртуальной консоли будет автоматически запускаться графический интерфейс. Окружающие операторы гарантируют, что сеансы, запускаемые из среды графического рабочего стола или из других виртуальных консолей, не будут немедленно запускать новую графическую Х-сессию. Пользователям /bin/sh следует добавить эти строки в ~fred/.profile, а пользователям tcsh нужно конвертировать их в эквивалентный скрипт для csh.
Если GUI уже запущен (через xdm, gdm, kdm и т.д.), то следует выполнить команду startx-:1. Она создаст вторую GUI-сессию. Если Вам нужна только один активный графический десктоп, то лучше отключить существующий экземпляр Xserver'а уменьшив уровень выполнения [run level] (в RedHat) или отключив [unlinking] конфигурационные файлы /etc/rc?.d/S99?dm (в Debian).
Init
6.1 Настройка
6.2 Упражнения
6.3 Дополнительные сведения
Итак, скрипт "уровня запуска", вызван процессом init и ищет в соответствующей директории скрипты начинающиеся на `S'. Пусть первым обнаруженным файлом окажется S10syslog. Порядок запуска скриптов определяется номерами. В нашем случае S10syslog оказался первым, поскольку не нашлось скриптов, начинающихся на S00 ... S09. На самом деле S10syslog
является ссылкой на /etc/init.d/syslog, который и является скриптом, отвечающим за запуск и остановку системного логгера. Поскольку ссылка начинается на `S', скрипт "уровня запуска" запустит syslog с параметром ``start''. Ссылки, названия которых начинаются на `K' (kill, убить) определяют порядок действий при останове системы или при переходе на другой "уровень запуска".
Для изменения списка подсистем, запускаемых по умолчанию, вы должны установить соответствующие ссылки в директории rcN.d, где N - "уровень запуска" по умолчанию, установленный в вашем inittab.
Последним важным действием init является запуск некоторого количества getty. Они прописываются как ``respawned'', что означает - если данный процесс будет остановлен, init запустит его снова. Большинство дистрибутивов используют шесть виртуальных терминалов. Вы можете захотеть уменьшить их количество для экономии памяти, или, наоборот, увеличить, что позволит запускать множество приложений одновременно и быстро переключаться между ними по мере надобности. Также может возникнуть потребность в запуске getty на текстовом терминале или при подключении по модему. В этом случае вам надо будет отредактировать файл inittab.
Initetc
Автор: Владимир Попов, popov_inm@yahoo.com
Опубликовано: 27.8.2002
© 2002, Издательский дом «КОМПЬЮТЕРРА» | http://www.computerra.ru/
Журнал «СОФТЕРРА» | http://www.softerra.ru/
Этот материал Вы всегда сможете найти по его постоянному адресу: http://www.softerra.ru/freeos/19771/
Упомянув в статье «Linux… на ноутбуке?» два стиля загрузки (BSD vs SysV), я не предполагал, что эта тема потребует дальнейшего обсуждения. Уже хотя бы потому, что подавляющее большинство популярных Linux-ов используют SysV-стиль. Однако «волна» новых дистрибутивов, появившихся в последнее время (весьма оперативно представленных читателям Softerra Алексеем Федорчуком), и возникающие при их инсталляции вопросы изменили моё отношение к этой теме. Окончательное же решение «взяться за перо» пришло после прочтения статьи уважаемого мной всё того же Алексея Федорчука «Из чего только сделаны Linux-ы». Эта статья, на мой взгляд, – один из немногих примеров материала, способствующего не разрешению конкретных трудностей, таких нередких при общении с Linux, а улучшению понимания работы системы в целом. Дело в том, что материалы такого рода, по моему скромному мнению, полезнее любых конкретных рекомендаций. Жаль, что «неофиты» Linux часто не обращают на них внимания.
Об этом – чуть подробнее. Опять же, по моему скромному мнению, инсталляция, да и эксплуатация Linux принципиально отличаются от таковых для ОС от MicroSoft (по крайней мере, для ОС семейства «9x»). При инсталляции последних подразумевается, что проводящий инсталляцию – пользователь рабочей станции (а то и отдельно стоящего компьютера), абсолютно не обременённый представлениями о локальных сетях, доменах, аппаратных средствах и т.д. и т.п. При инсталляции же Linux сплошь и рядом подразумевается, что её проводит администратор «средней» руки, как минимум. А как иначе, если сами собой подразумеваются установка сетевого программного обеспечения, терминального сервера, серверов http, ftp, SQL, nfs и т.д.? Что за Linux без этого? Можно, конечно, скрыть это всё как «умолчание», но беда в том, что и дальнейшая эксплуатация системы подразумевает некоторый уровень компетенции, что и не удивительно: администрировать приходится многопользовательский сервер, пусть даже используемый, в данном случае, в качестве рабочей станции.
Складывается ситуация, напоминающая «Уловку-22» Джозефа Хеллера. Напомню: 22- й параграф перечня показаний для демобилизации гласил, что всякий, отказывающийся от военной службы, уже достаточно разумен, чтобы быть признанным годным к ней. Или проще: если ты не хочешь служить, то значит – здоров и служить – должен, а если служить хочешь, то на сомнения в психической нормальности глаза можно закрыть – сам же напрашиваешься. В любом случае служить будешь. Так и с Linux: для того, чтобы узнать, нужно инсталлировать, но для того чтобы инсталлировать, нужно знать. В любом случае знать – нужно. По аналогии я бы назвал это «Уловкой от Linux».
Системы для конечного пользователя на основе Linux создавать, конечно, можно. Их эксплуатационные характеристики могут быть очень высоки, по крайней мере выше, чем у «свежеинсталлированных» win'9x. Но это отнюдь не означает, что такие системы «автоматически» получаются из дистрибутивов. Быть может, такие дистрибутивы ещё и появятся (необходимость их появления – уже другой вопрос), но в настоящее время большинство «устоявшихся» пользователей Linux, мне кажется, скорее специалисты, нежели «обычные пользователи». А специалист отличается от пользователя среди прочего ещё и тем, что способен искать решение, не имея конкретных рекомендаций. Их ему заменяют исследовательский азарт, ну, и знания, конечно. Знания, как правило, более общего порядка, нежели опции и местоположение того или иного конфигурационного файла. Администраторам NT-серверов хорошо знакомо раздражение, испытываемое при переходе на новую версию: сервер-то конфигурировать надо, будь он хоть NT, хоть UNIX, а найти необходимые настройки в бесконечно развивающемся «интуитивно понятном» интерфейсе бывает ох как непросто. В Linux ситуация ещё «веселее»: способы конфигурирования разнятся не только для разных дистрибутивов, но и от версии к версии. Особые решения могут потребоваться, если вы захотите использовать внедистрибутивное ПО. В общем, «чем дальше в лес, тем больше дров» – чем больше число дистрибутивов, их версий и, вообще, программных продуктов, тем труднее запастись конкретными рекомендациями на все случаи жизни. Тем ценнее, соответственно, и знания, помогающие самостоятельно разобраться во всех возникающих проблемах.
Исходя из всего этого, мне показалось полезным изложить своё представление об этих самых стилях загрузки. Во-первых, потому что именно в ходе загрузки задаются очень многие характеристики системы. Во-вторых, потому что именно способом загрузки дистрибутивы различаются, подчас, весьма существенно. И в-третьих, потому что надо же хоть на каком-то примере показать, что традиционный setup от RedHat, одноимённый – от Slackware, всеобъемлющий linuxconf и семейство drak-конфигураторов от Mandrake модифицируют одни и те же файлы. Разнообразие средств конфигурирования перестаёт радовать, когда их количество начинает превышать число конфигурационных файлов, для «завуалированного» редактирования которых они созданы. Более того, случается, что нужный результат можно получить только «вручную». Мне, например, пришлось однажды столкнуться с «мышами» NetScroll+, полноценную работу которых в консольном и графическом режимах удалось достичь, лишь определив РАЗНЫЕ типы мыши в /etc/sysconfig/mouse и /etc/X11/XF86Config. О настойчивых попытках запустить сетевые сервисы до активации pcmcia-устройств на ноутбуках я уже писал. Таковы были мотивы. Хочется верить, что результат кому-то пригодится. И прошу извинить за пространное вступление.
Итак, начнём с момента, когда аппаратный загрузчик уже запустил загрузчик внесистемный (GRUB, LILO), а этот последний, в свою очередь, загрузил в память ядро системы: в отсутствие основных средств ОС (они ещё попросту не загружены) компьютеру удалось «поднять себя за шнурки собственных ботинок». Ядро инициализировалось, выполнило ряд операций, связанных с распознаванием и конфигурированием устройств, и запускает процесс init – «прародитель» всех будущих процессов. init, по «способу существования» – типичный демон. Будучи запущен однажды, он находится в памяти вплоть до остановки системы, хоть, может, и «спит» большую часть времени. С точки зрения этого самого демона, система всегда находится в камом-то определённом состоянии. Состояния эти называются уровнями выполнения. Уровнями их, в своё время, назвали потому, что система обязана была проходить их последовательно, от низшего к высшему. В принципе, это и сейчас так, хотя объяснить, почему перезагрузка выполняется на шестом, высшем уровне, я не берусь. Это – теория. Практика же состоит в том, что до момента запуска init от нас ничего не зависело (генерацию ядра и опции, которые можно было передать ему при запуске из-под LILO или GRUB, мы здесь не рассматриваем), начиная же с него, поведение системы определяется файлами конфигурации, а значит, может контролироваться. Работу самого init, например, определяет /etc/inittab. С него и начнём. Для иллюстрации BSD-стиля использован файл Slackware, для иллюстрации SysV-стиля – RedHat.
inittab
| 1 | # 0 = halt # 1 = single user mode # 2 = unused # 3 = multiuser mode # 4 = X11 with KDM/GDM/XDM # 5 = unused # 6 = reboot |
# 0 – halt # 1 – Single user mode # 2 – Multiuser, without NFS # 3 – Full multiuser mode # 4 – unused # 5 – X11 # 6 – reboot |
| 2 | id:3:initdefault: | id:3:initdefault: |
| 3 | si:S:sysinit:/etc/rc.d/rc.S | si::sysinit:/etc/rc.d/rc.sysinit |
| 4 | l0:0:wait:/etc/rc.d/rc.0 su:1S:wait:/etc/rc.d/rc.K # rc:2345:wait:/etc/rc.d/rc.M # # l6:6:wait:/etc/rc.d/rc.6 |
l0:0:wait:/etc/rc.d/rc 0 l1:1:wait:/etc/rc.d/rc 1 l2:2:wait:/etc/rc.d/rc 2 l3:3:wait:/etc/rc.d/rc 3 l4:4:wait:/etc/rc.d/rc 4 l5:5:wait:/etc/rc.d/rc 5 l6:6:wait:/etc/rc.d/rc 6 |
| 5 | ca::ctrlaltdel:/sbin/shutdown -t5 -rf now pf::powerfail:/sbin/shutdown -f +5 pg:0123456:powerokwait:/sbin/shutdown -c |
ca::ctrlaltdel:/sbin/shutdown -t3 -r now pf::powerfail:/sbin/shutdown -f -h +2 pr:12345:powerokwait:/sbin/shutdown -c |
| 6 | c1:1235:respawn:/sbin/agetty 38400 tty1 c2:1235:respawn:/sbin/qlogin /dev/tty2 root ... |
1:2345:respawn:/sbin/mingetty tty1 2:2345:respawn:/sbin/mingetty tty2 ... |
| 7 | x1:4:wait:/etc/rc.d/rc.4 | x:5:respawn:/etc/X11/prefdm -nodaemon |
Вообще-то, на все основные конфигурационные файлы существуют man-страницы. Но в данном случае достаточно знать, что каждая строка файла (не считая комментариев, разумеется) имеет следующий формат:
идентификатор(метка) : уровни выполнения : действие : запускаемый процесс
Файл разбит на секции условно, исключительно для удобства нашего анализа. Первое, что обращает на себя внимание, – присвоение графическому режиму разных уровней выполнения (секция 1). Как ни странно, но за этим ничего не стоит и стили загрузки тут ни при чём. Просто данная привязка не регламентирована – очередной пример ничем не ограниченного разнообразия.
Вторая секция определяет уровень выполнения по умолчанию. Сменив цифру в позиции «уровни выполнения» с 3 (многопользовательский консольный режим) на 4 (для Slackware) или 5 (для RedHat), вы заставите систему стартовать сразу в графическом режиме. Позиция «действие», в данном случае, совершенно очевидна. Цифр может быть несколько; определяющей будет старшая. Пустое значение заставит init запросить уровень выполнения в ходе загрузки
Третья секция (действие – sysinit) запускает скрипт, выполняемый вне зависимости от запрошенного уровня. «S» (single user) в позиции «уровни выполнения» у Slackware и отсутствие значения в той же позиции у RedHat значения не имеют: в момент загрузки скрипт будет выполнен однократно в любом случае. А вот различие в именах скриптов примечательно: rc.S – первый из скриптов с именем, соответствующим соглашениям BSD-стиля – все они начинаются символами «rc.».
Активизировав виртуальную память (swap), смонтировав файловые системы, инициализировав Plug and Play устройства, загрузив модули ядра и выполнив ряд других операций, необходимых для работы на любом из уровней выполнения, init переходит к выполнению уровень-специфичных скриптов. Вызовы этих скриптов и составляют четвёртую секцию, и именно в них заключается главное отличие стилей загрузки. Для BSD-стиля, как мы видим, характерно наличие отдельного скрипта для каждого из уровней выполнения. Кроме rc.0 и rc.6, отвечающих, как нетрудно догадаться, соответственно за остановку и перезагрузку системы, скрипты rc.K и rc.M обеспечивают соответственно одно- и многопользовательский уровни выполнения. Совершенно иной алгоритм у загрузки SysV-стиля. Здесь на каждом из уровней требуется выполнение целого ряда скриптов, находящихся в подкаталогах rc0.d ... rc6.d. Подкаталоги эти содержат на самом деле лишь символические ссылки на реальные скрипты, находящиеся, в свою очередь, в подкаталоге init.d. Каждый из этих скриптов способен выполнять, как минимум, две операции – запуск и останов своего сервиса. Которая из операций будет вызвана, определяется первой буквой имени символической ссылки: «S» – для запускающих симлинков, «K» – для останавливающих. Цифры в имени определяют порядок запусков/остановов. Ух… Чем-то напоминает путь к «инфарктгенерирующей» игле Кощея Бессмертного. Но в гибкости этой системе не откажешь. Необходимость менять состав и имена симлинков случается крайне редко – обычно с этой задачей прекрасно справляется консольная ntsysv со всеми её графическими потомками. Однако случается. Как, например, в описанном случае включения на ноутбуке сетевой поддержки до инициализации pcmcia. Действие «wait» означает в данном случае необходимость для init ждать окончания запускаемого в данной строке процесса.
Строки пятой секции описывают реакцию системы на пропадание и появление питания (подразумевается сигнал от UPS и старт системы после такой остановки), и на Ctrl+Alt+Del – «салют из трёх пальцев», по выражению Патрика Фолькердинга (Patrick J. Volkerding) . По крайней мере один случай осмысленного редактирования этой строки мне известен. Заменив:
ca::ctrlaltdel:/sbin/shutdown -t3 -r now
на:
ca::ctrlaltdel:/sbin/shutdown -t3 -h now
мы заставим систему выключаться вместо перезагрузки в ответ на этот самый салют. Эффект, абсолютно бессмысленный с точки зрения «непуганых» обладателей отдельно стоящих десктопов, оказывается довольно изящным решением, когда речь идёт о корректном выключении сервера АСУТП в конце третьей смены техником Пупкиным, болезненно реагирующим на всякие login-ы с password-ами. Ну, а если сервер снабжён UPS-ом, то несложно обеспечить его корректное выключение даже рубильником.
Как вы, вероятно, догадываетесь, после выполнения скрипта из четвёртой секции система полностью готова к работе. Самое время запустить на одной или нескольких консолях (в зависимости от уровня выполнения) программу регистрации пользователя, предоставим ему, таким образом, возможность теперь уже самостоятельно общаться с системой. Что и делают строки шестой сессии. Действие respawn означает автоматический перезапуск процесса в случае его завершения. То есть: закончил сессию один пользователь – тут же появляется предложение регистрации для другого. Количество консолей определяется количеством таких строк. Какую именно программу использовать для входа пользователей в систему – дело вкуса. Во второй строке этой секции для Slackware фигурирует qlogin – скрипт, обеспечивающий, автоматическую регистрацию root на второй консоли: вопиющее нарушение правил безопасности! Но – удобно.
К седьмой секции я отнёс строки, связанные c автоматической загрузкой X11. Правый и левый скрипты не аналогичны – строка Slackware скорее должна была бы попасть в четвёртую секцию: в результате её выполнения загружается и X-сервер, и менеджер сессий, тогда как в RedHat строка из четвёртой сессии загрузит X-ы, а из седьмой – менеджер сессий. Результат, впрочем, в обоих случаях будет один и тот же.
На этом работа init приостанавливается – процесс засыпает. Поводом для «побудки» может быть «смерть» одного из запущенных процессов (действие respawn подразумевает перезапуск такого процесса), сигнал об ошибке питания (ищутся и обрабатываются строки с действиями powerfail и powerwait), «салют из трёх пальцев» (строка с ctrlaltdel) или запрос перехода на другой уровень выполнения. Таковым, в свою очередь, может быть команда выключения, перезагрузки или команда перехода в явном виде:
/sbin/init [ 0123456Ss ]
В некоторых системах имеется специальная команда «tell init»:
/sbin/telinit
Обычно это просто симлинк на init, зато очевидно, что требуется не запуск нового процесса, а передача параметра уже существующему. Запрос на изменение уровня выполнения заставляет init «перечитать» inittab, отправить всем процессам, несовместимым с запрошенным уровнем выполнения, сигнал-предупреждение SIGTERM (а если пяти секунд окажется недостаточно этим «бедолагам» для завершения, то и SIGKILL), после чего будут выполнены все строки, в поле «уровень выполнения» которых присутствует номер уровня, на который запрошен переход. И так далее. Если, конечно, запрошенный уровень не нулевой, т.е. последний для данной загрузки.
В принципе, это всё. Как именно задаются те или иные настройки системы в целом и отдельных сервисов в частности, всегда можно узнать проанализировав стартовые скрипты. Их, конечно, многовато, и требуются хотя бы минимальные представления о языке shell, на котором они преимущественно написаны, но, говорят, это вызывает затруднения только первые десять лет – потом привыкаешь. А если серьёзно, то без этих представлений все равно с Linux не поладить. Да и вряд ли потребуется редактировать многие скрипты. Возникла проблема – вооружайтесь grep, любимым редактором и ищите, начиная от rc.S или rc.sysinit, а если знаете точнее – тем лучше.
Несколько практических советов я всё же попытаюсь дать:
Найдите время хотя бы однажды просмотреть стартовый загрузочный скрипт (строка с действием sysinit в /etc/inittab) – именно в ходе его выполнения задаются основные настройки системы. Если Вам повезёт, то текст скрипта окажется достаточно информативным. Вышеупомянутый Патрик Волькердинг, например, умудряется цитировать в скриптах Slackware HOWTO. Для RedHat-совместимых систем рекомендуется изучить состав пакета initscripts. В его состав, кроме стандартных man-ов, входит файл sysconfig.txt – подробное описание того, откуда rc.sysinit берёт параметры конфигурации. Не стесняйтесь просматривать скрипты, запускающие отдельные сервисы: они, обычно, умеют выполнять не только запуск и останов «вверенных» им сервисов. Там вы увидите, какие опции составитель дистрибутива посчитал оптимальными для данного сервиса, куда записывается log и где ищутся конфигурационные файлы. Хорошо документированный скрипт может быть интереснее руководства. В том же пакете initscripts есть файл sysvinitfiles – руководство по написанию собственного скрипта инициализации. Даже если Вы не собираетесь писать такой скрипт, предлагаемая информация поможет проанализировать скрипты существующие. Как я уже говорил, многие конфигурационные файлы имеют собственные man-страницы, где может быть много полезного. Вы, вероятно, удивитесь, узнав, например, что XFree86 при запуске ищет свой конфигурационный XF86Config более чем в десятке каталогов. Причём последний может ещё и именоваться по-разному. Сведения, почерпнутые из скрипта, имеют «абсолютный» характер, из HOWTO, info, manual – «относительный». Без комментариев: понятно, что скрипт, собственно, и выполняется, а информация давненько, быть может, готовилась.
К моменту запуска виртуальных консолей все основные настройки системы уже «в силе», и я надеюсь, мне удалось убедить Вас, что посредством анализа скриптов загрузки всегда можно найти конфигурационные файлы, отвечающие за ту или иную опцию системы или сервиса. Иногда – трудно, но всегда – возможно в принципе. К сожалению, возможности конфигурирования системы на этом не исчерпываются. Само собой разумеется, что загрузка, в каком бы стиле она ни выполнялась, никак не касается конфигурации пользовательских приложений (в отличие от сервисов, симпатично по традиции именуемых обычно демонами). Здесь уже без документации не обойтись. Полезно помнить, что, как правило, приложение может иметь много конфигурационных файлов: основной – в каталоге /etc и пользовательские – в домашних каталогах пользователей. Что имена этих файлов формируются обычно из имени приложения и префиксов/суффиксов «rc», «conf» или «config». Что пользовательские конфигурационные файлы обычно «скрыты», поскольку начинаются с точки (dot). Но «как правило» не означает «всегда»: сложные приложения имеют иногда целые подкаталоги конфигурирующих файлов, каталоги эти (или файлы) могут находиться в /usr/share/приложение или где-нибудь ещё, да и названия их могут выглядеть «нестандартно» и т.д. и т.п.
Ещё одной категорией конфигурационных файлов, местоположение, да и само существование которых трудно «вычислить» чисто логическим путём, являются файлы, обращение к которым происходит только по необходимости. Это, прежде всего, файлы:
Регламентации доступа: host.conf, hosts, hosts.allow, hosts.deny. Администрирования: group, passwd, securetty, shadow. Используемые при работе в сети: resolv.conf, export, networks.
Эти файлы могут использоваться и ядром, и сервисами, и отдельными приложениями. Довольно часто сервисы, кроме параметров, принятых при старте от инициализирующего скрипта, используют и собственные конфигурационные файлы. Забавно то, что о первых забывают обычно чаще, чем о вторых. Одним словом, сюрпризов в сфере конфигурации программных продуктов, используемых в Linux, – более чем достаточно. Успехов Вам в их «разборке».
Телефон редакции: (095) 232-2261
E-mail редакции: inform@softerra.ru
По вопросам размещения рекламы обращаться к Алене Шагиной по телефону +7 (095) 232-2263 или электронной почте mailto:reclama@computerra.ru
Инсталляция
"Папа, я, когда вырасту, тоже стану рутом!"
Когда-то установка Linux была значительной проблемой, до того неприятной (особенно для новичков), что в одном форуме кто-то написал "надо чтобы перед установкой Linux проверял, есть ли на диске Windows, и если есть, то брал конфигурацию железа с нее". Последние версии ставятся проще, чем Windows 98. Устанавливать его можно с дискового раздела, по сети, по ftp, но я всегда пользовался только установкой с загрузочного CD-ROM, оставив первые варианты экстремалам. Выбор самого дистрибутива дело очень личное и может повлиять на всю вашу последующую жизнь. Каждый дистрибутив имеет свои особенности и недостатки. Для меня существенным недостатком является английский язык, поскольку я предпочитаю не приспосабливаться к компьютеру, а приспосабливать его под себя. Еще большим недостатком я считаю заботу обо мне со стороны неназываемой фирмы, в виде сокрытия настроек и информации. С другой стороны большим удобством является, когда приложение при удалении само вычищает диск от продуктов своей жизнедеятельности. Таким образом, я и связался с ASPLinux. Это совместимая с Red Hat Linux русская версия с некоторыми оригинальными добавлениями, вроде дополнительного загрузчика ASPloader. Также совместимость означает наличие в ASPLinux программы управления пакетами RPM (Redhat Packet Manager).
Предполагается, что вы приобрели лицензионную версию (например, купили в ларьке у метро или скачали из Интернета)! Затем принесли домой, и поставили диск в лоток. Перезагрузились и увидели много строчек на английском, в которых предлагается выбрать вариант установки. Самый простой - это установка в графическом режиме. Выберите язык, клавиатуру и мышь (они, в отличие от языка, сразу определяются правильно). Опция "Эмулировать 3х кнопочную мышь" не приведет к появлению третьей кнопки, но позволит интерпретировать одновременное нажатие на обе как нажатие на третью.
Затем вам предложат выбор варианта установки, советую выбрать "Выборочно". Другие варианты хуже установки Windows XP, та хоть диск без предупреждения не форматирует. После это можете разбить диск программами DiskDruid или fdisk (не путать с fdisk для DOS или Windows, это все разные программы). Если у вас достаточно большой диск, то советую в начале диска сделать небольшой раздел, примерно 20MB, который обозначить /boot. Это полезно, поскольку не каждый загрузчик умеет работать с большими дисками, да и соображения безопасности тоже не будут лишними. Основной раздел следует маркировать как /. Затем идет выбор файловой системы. Основная файловая система Linux называется Ext2fs, дополнительно можно использовать FAT и многие другие. Если вы не хотите отказываться то Windows, то можно использовать раздел FAT даже для постановки системы. Это лишит вас некоторых дополнительных возможностей, например системы привилегий для Ext2fs. В Linux для размещения данных подкачки используется специальный раздел с файловой системой Swapfs. Этот раздел рекомендуется сделать примерно в полтора раза больше оперативной памяти. После установки эти разделы будут автоматически смонтированы. Здесь же делаются первоначальные установки RAID.
Если еще не решились полностью разметить весь диск под ext2fs, а из сентиментальных соображений оставить какую-либо другую операционную систему, то следующим этапом идет конфигурирование системного загрузчика lilo (LInux LOader). Lilo можно ставить либо в MBR (Master Boot Record), либо в первый раздел диска. Советую использовать второй вариант, если вы сделали к тому моменту раздел /boot, как я писал выше. Тут же предлагается создать системную дискету. Не отказывайтесь! Начальная конфигурация сети проходит в том случае, если у вас есть сетевые устройства. Настройка их достаточно стандартна, вам предлагается выбрать IP-адрес, маску, адрес сети и широковещательный адрес в первой панели. И имя компьютера, адреса шлюза и серверов DNS во второй, для каждого из интерфейсов. Также для каждого интерфейса имеется две кнопки "Использовать DHCP" и "Активизировать при загрузке". DHCP нужно оставить только если ваша сеть его использует. Активизация интерфейса при загрузке означает, что его не нужно будет каждый раз включать вручную (некоторым это нравится).
Введите пароль для рута, введите пользователей. Настоятельно советую не использовать возможности рута постоянно, поскольку они не безграничны. Если вы снесете себе всю систему, то погибнет и рут. Заведите хоть одного простого юзера. И ни в коем случае не отключайте "shadow passwords" и "MD5 cryptography"!
Выбор установки - это выбор пакетов. Они распределены по группам, каждая из которых имеет достаточно красноречивое название. Кстати, правильный выбор необходимых пакетов ДЕЙСТВИТЕЛЬНО позволяет сэкономить место на диске. Если ваши требования ограничиваются только сервером сети, то следует подумать "А нужна ли мне графическая оболочка?". В этом случае, как правило, не нужна. С другой стороны средства кластеризации явно лишние для 99.9% всех компьютеров, особенно если на них нет сети. Но, по крайней мере, на один компьютер в локальной сети нужно установить Kernel Development и Development. Это потребуется при окончательном конфигурировании.
После выбора пакетов вам предложат сконфигурировать графическую оболочку. Выбор конфигурации в стандартном дистрибутиве небольшой, позднее придется ее перестроить, но об этом потом. А сейчас выберете графическую карту из списка доступных, не обольщайтесь его размером, в действительности там немного изначально сконфигурированных серверов. Если у вас не Savage или Rage, а что-нибудь посовременней, то выбор практически не отличается от стандартного SVGA. Выберите объем графической памяти. Кнопку "Проверить" нажимать не рекомендуется. Поскольку сама графическая среда полностью не загружена и не отконфигурирована, то эффект может быть абсолютно неожиданный, даже если все установки верны.
Некоторое время будут копироваться пакеты, затем компьютер перезагрузится. И у вас есть свой домашний пингвин! Он еще молод и необразован, а потому вам придется приложить к этому некоторые усилия. Только не пугайтесь, для доведения до ума Windows приходится работать вдвое больше. Сначала ищешь возможность включить настройку, и только затем начинаешь ее крутить.
Инструкция include
Понятно - что она означает - включить в этот блок описания из другого файла (блока). Причем, аргументом этой инструкции может быть не просто имя файла и блока, а, вообще говоря, просто строка, например
include "en_US(pc104)+ru"
Естественно, все "слова", соединенные плюсами, должны представлять собой имена существующих файлов и блоков в них, причем того же типа, что и блок, в котором встретилась эта инструкция.
Интернет
По мере накопления опыта у сисадмина меняется мировоззрение и ассоциации: говорим "интернет" - подразумеваем прокси-сервер, и наоборот. Прокси-серверов под "винду" также огромное множество. WinGate, WinRoute, WinProxy и т. д. В Windows98/Me также есть подобие прокси, именуемое "общий доступ в интернет".
В принципе, мои симпатии, опять же, склоняются к proxy-серверу WinGate фирмы Alt-N. Люблю его за функциональность. Но, дабы меня не обвинили в необъективности и рекламе, рассмотрим более простой чешский продукт WinProxy (http://www.winproxy.cz), который также может использоваться как простенький mail-server.
В принципе, не имеет значения, каким прокси-сервером пользоваться. Главное - что с ним делать. А задача у нас - облегчить трафик.
В окне сетевого мониторинга и через статистику определите, какие сайты "не по работе" чаще всего посещают пользователи (рис. 6). Это могут быть анекдоты, гороскопы и прочая ерунда. Также довольно сильно засоряют трафик полюбившиеся юзерам чаты. Запретив доступ к вышеуказанным ресурсам, вы, во-первых, основательно разгрузите трафик, а во-вторых, народ будет больше заниматься делом.
Рис. 6. Мониторинг посещаемых сайтов
Интерпретатор bash
В этой статье я рассмотрю оболочку bash, которая стандартна для большинства систем. Однако сам командный язык подробно разобран не будет из-за его объемности. Итак, начнем по порядку с регистрации пользователя. Как я уже отмечал, после успешной аутентификации пользователя, запускается программа-оболочка (в нашем случае это /bin/bash). При запуске оболочки выполняются некоторые действия. Эти действия определены в файле ~/.bash_profile (см. листинг 3).
Листинг 3. # .bash_profile # Get the aliases and functions if [ -f ~/.bashrc ]; then ~/.bashrc fi # User specific environment and startup programs PATH=$PATH:$HOME/bin BASH_ENV=$HOME/.bashrc USERNAME="user" HISTIGNORE=" [ ]*:&:bg:fg" export USERNAME BASH_ENV PATH HISTIGNORE clear
Файл .bash_profile представляет собой обыкновенный сценарий. Теперь разберемся, какие действия выполняет этот сценарий. В этом файле определяются переменные окружения и программы, которые должны запускаться автоматически. В листинге 3 сначала проверяется существование файла .bashrc и, если он существует, интерпретатор выполняет его. Файл .bashrc рассмотрим немного позже. Затем устанавливаются переменные окружения: PATH, BASH_ENV, USERNAME, HISTIGNORE. Первая задает путь для поиска программ, вторая определяет среду интерпретатора (файл .bashrc), третья устанавливает имя пользователя, а последняя относится к истории команд, введенных пользователем. Затем переменные экспортируются. Дело в том, что переменные локальны в рамках сценария. При экспорте переменных их значение будет доступно порожденным процессам. Например, создайте такие два сценария (см. листинги 4 и 5).
Листинг 4. #!/bin/bash MYVAR="My var" export MYVAR ./listing5
Листинг 5 #!/bin/bash echo "$MYVAR"
Запустите сценарий ./listing4. Он экспортирует переменную MYVAR и запустит сценарий listing5, которые выведет значение переменной MYVAR («My var») на экран. Теперь закомментируйте строку:
export MYVAR
в сценарии listing4 и запустите его снова. На экране значение переменной MYVAR не будет отображено.
Теперь вернемся к файлу .bashrc, а потом перейдем к командному языку оболочки bash.
Листинг 6 # .bashrc # User specific aliases and functions alias rm='rm -i' alias mv='mv -i' alias cp='cp -i' alias s='cd ..' alias d='ls' alias p='cd -' # Need for a xterm & co if we don't make a -ls [ -n $DISPLAY ] && { [ -f /etc/profile.d/color_ls.sh ] && source /etc/profile.d/color_ls.sh export XAUTHORITY=$HOME/.Xauthority } # Read first /etc/inputrc if the variable is not defined, and after the /etc/inputrc # include the ~/.inputrc [ -z $INPUTRC ] && export INPUTRC=/etc/inputrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi
Здесь задаются определенные установки. В основном данные установки необходимы для удобства пользователя. Например, определяются псевдонимы команд (alias).
Оболочка bash использует еще один командный файл – .bash_logout. В этом файле указываются действия, которые нужно выполнить при выходе из интерпретатора, то есть выхода из системы.
Использование fbset в реальной жизни
Котельников Руслан, 30.04.03
Frame buffer позволяет делать удивительные вещи с консолью. На первый взгляд данный модуль не является особенно необходимым и без этого можно прекрасно работать. Но как только вы станете интенсивно работать с консолью, то возникает необходимость иметь более, чем 25 строк и 80 столбцов. Каково, что простаивают мощности вашей новой видеокарты, ведь с консолью может справиться любая старая видеокарта с поддержкой vga. Что делать и как заставить Linux использовать все возможности? На помощь приходит frame buffer и дает нам возможность работать с консолью, как подобает.
Ну, хватит теории - перейдем к практике. Заставим все работать, предупреждаю сразу - возможно вам придется перекомпилировать ядро, но сейчас это не просто просто, а очень просто. Итак, в начале необходимо проверить, есть ли возможность у вас в ядре работать с frame buffer. Для этого вам необходимо зайти в каталог, где у вас
хранятся исходники ядра или предварительно установить их (обычно это /usr/src/linux-2.xx.xx) и дать команду:
make menuconfig
после нескольких секунд перед вами уже вся конфигурация компьютера. Заходите по пути Console drivers->frame buffer->ваш драйвер ставите звездочку напротив. Так же установите Video Mode Selection и VGA text console. Затем
даёте следующие команды:
make
make modules
И если не было ошибок, то
make install
make modules_install
В зависимости от дистрибутива вам этого достаточно или же придется делать все вручную, но это - тема отдельной статьи. После этого вам необходимо проверить, установлена ли программа fbset. Для этого просто дайте команду из-под root:
fbset
если у вас нет данной программы, то посмотрите на дисках вашего дистрибутива, скорее всего данная программа уже входит в дистрибутив.
Для того, чтобы узнать, какие режимы поддерживает ваша система, взгляните в файл
vi /etc/fb.modes
и вот теперь, наконец, можно насладиться всеми возможностями видеокарты:
fbset "800x600-60"
А можно смотреть видео из консоли без всяких старых и медленных svga:
mplayer video.avi -vo fbdev -bpp 32
Для сравнения - svga поддерживает только bpp 8. Дерзайте и используйте консоль, только она позволяет насладиться работой с консолью полностью.
Источник - LinuxBegin.ru
http://linuxbegin.ru/
Адрес этой статьи:
http://linuxshop.ru/linuxbegin/article296.html
Использование LILO
LInux LOader (LILO) - программа, предназначенная для загрузки Linux и других операционных систем.
Существуют другие загрузчики, например bootlin, bootact, bootstar, но они постепенно вытесняются LILO.
Помимо LILO Linux еще можно загрузить с помощью loadlin, GRUB (загрузчик в Linux Mandrake) или NTLoader.
Подробнее об использовании NTLoader и программы loadlin можно прочитать в моей статье "Многоосность"
LILO состоит из трех частей:
программа записи начального загрузчика lilo программа конфигурации liloconf файл конфигурации /etc/lilo.conf
Liloconf создает файл /etc/lilo.conf, который используется программой lilo для записи начального загрузчика.
Обычно LILO помещают в MBR (Master Boot Record). Но иногда LILO устанавливают на первый сектор того раздела, где установлен Linux. Второй способ обычно используется, если нужно обеспечить загрузку Linux:
с помощью другого загрузчика, например NTLoader на старых машинах без поддержки LBA
При загрузке компьютера LILO выдает подсказку
LILO
или
LILO boot:
После чего нужно ввести метку той операционной системы, которую нужно загрузить. Для загрузки Linux обычно следует ввести linux. Для просмотра всех доступных меток, нажмите Tab. Современные версии LILO обычно имеют удобное меню. Выбор меток осуществляется с помощью стрелок.
Иногда на экран только выдается подсказка
LILO
Чтобы выбрать ядро нужно нажать клавишу Shift, после чего появиться подсказка
LILO boot:
и только теперь можно нажать Tab... Если вы введете команду help, то получите список всех команд LILO.
Примечание: поведение LILO зависит от его настройки в файле /etc/lilo.conf.
При запуске Linux можно передать ядру дополнительные параметры, например mem=1024M - устанавливает объем ОЗУ равным 1024MB. Можно сформировать строку параметров и записать ее в lilo.conf - эта строка будет передана ядру при загрузке Linux.
С помощью LILO можно организовать загрузку других операционных систем (Windows, FreeBSD,..) и загрузку разных версий ядра одной ОС (имеется в виду Linux).
Пример конфигурационного файла /etc/lilo.conf
Операционная система: Linux Mandrake 7.2
LILO version: 21.5
# Глобальные опции
# Загрузочное устройство (MBR на /dev/hda) boot=/dev/hda
# "Карта" загрузки. # Если этот параметр пропущен, # используется файл /boot/map map=/boot/map
# Устанавливает заданный файл как новый загрузочный сектор. # По умолчанию используется /boot/boot.b install=/boot/boot.b
# compact - не используйте этот режим. Обычно он # используется при загрузке с дискеты
# Режим VGA: normal - 80x25, ext - 80x50 vga=normal
# Образ ядра по умолчанию. Если не задан, то используется # первый в списке default=linux
# Раскладка клавиатуры keytable=/boot/ru4.klt
# Включен режим LBA32. На некоторых дисках может вызвать проблемы # (Обычно проблемы возникают на старых компьютерах без поддержки # трансляции блоков (LBA) lba32
# Включает ввод приглашения без нажатия на какую-нибудь клавишу. # Автоматическая загрузка невозможна, если prompt установлен, # а timeout - нет prompt
# Задержка 5 секунд (в некоторых версиях используется delay) timeout=50
# Подсказка, которая выдается при загрузке message=/boot/message
# Цветовая схема menu-scheme=wb:bw:wb:bw
# Пароль (ко всем образам) # password=54321
# Пароль нужен для загрузки образа, если параметры задаются # в командной строке (для всех образов) # restricted
# Список образов. Максимум 16 вариантов
image=/boot/vmlinuz # ядро label=linux # метка (метки должны быть разными) root=/dev/hda5========== # корневая файловая система ======= append=" mem=64M"==== # объявление параметров ядра ======= vga=788======== ======= read-only====== ======== # монтирование корневой # файловой системы в режиме # "только чтение"
# Параметры vga, password, restricted могут быть как глобальными, # так и отдельными для каждого образа
# Т.е. вы можете закрыть паролем определенный образ
image=/boot/vmlinuz # image - для Linux-систем label=linux-nonfb root=/dev/hda5 append=" mem=64M" read-only image=/boot/vmlinuz label=failsafe root=/dev/hda5 append=" mem=64M failsafe" read-only other=/dev/hda1 # other - какая-нибудь другая система label=windows # для не Linux-систем параметр root # не указывается table=/dev/hda # определяет устройство, содержащее # таблицу разделов other=/dev/fd0 label=floppy unsafe # не давать доступ к boot сектору во время создания # карты диска. Запрещает проверку таблицы разделов. # Параметры table и unsafe несовместимы
Для того, чтобы изменения вступили в силу (если вы изменили файл конфигурации), нужно выполнить команду lilo
Использование locate
Данная утилита просто незаменима в случае если вам хотя бы приблизительно известно имя файла, который нужно найти. Отличительная особенность данной команды, скажем от того же find, в том что при работе она не сканирует по настоящему файловую систему, поиск идет в предварительно построенной базе, в которой хранится как-бы слепок с файловой системы. Такой слепок выполняется с помощью команды locate -u или updatedb, которая по настоящему перелопачивает ваши жесткие или сетевые диски, а имена всех найденных файлов записывает в базу. Естественно что данная процедура довольно ресурсоемкая, и может занимать довольно длительное время. Ее запуск обычно поручают crontab, который запускает updatedb с требуемой частотой. Частота обновления базы зависит от того насколько часто обновляется содержимое файловой системы, а также насколько важна актуальность данных. Так обычно обновление базы выполняется автоматически раз в неделю, или вручную, после того как вы или системный администратор установили новую партию свежего ПО. Отмечу, для того чтобы обновить базу, нужно иметь права суперпользователя.
Приведу простейший пример использования:
$ locate traceroute /usr/man/man8/traceroute.8.gz /usr/sbin/traceroute6 /usr/sbin/traceroute
$ locate mpg123 /usr/doc/mpg123-0.59r /usr/doc/mpg123-0.59r/BUGS /usr/doc/mpg123-0.59r/CHANGES /usr/doc/mpg123-0.59r/COPYING /usr/doc/mpg123-0.59r/INSTALL /usr/doc/mpg123-0.59r/JUKEBOX /usr/doc/mpg123-0.59r/README /usr/doc/mpg123-0.59r/TODO /usr/doc/mpg123-0.59r/mp3license /usr/man/man1/mpg123.1.gz /usr/bin/mpg123 $
Из приведенных примеров видно три существенных момента, касающихся поведения locate. Во-первых ищутся все файлы и каталоги в именах которых встречается подстрока заданная в качестве аргумента. Во-вторых файлы выводятся включая полный путь к ним. В-третьих заданная подстрока вообще может не входить в имя самого файла, а встречаться в его пути. Так во втором примере в список найденных файлов было полностью включено содержимое каталога mpg123-0.59r.
Иногда требуется более точный поиск, когда нужно ограничить то место куда может входить заданная подстрока. Скажем если нам нужно найти только файлы и каталоги в название которых входит mpg123. В данном случае можно использовать шаблоны ?аля bash? (помните *, ?, [...]) или более продвинутый вариант использующий регулярные выражения. Я предпочитаю последний, как более мощный и продвинутый.
Для того чтобы сообщить locate что вы хотите использовать регулярные выражения, нужно указать форму locate -r. Так в нашем случае запрос будет выглядеть следующим образом:
$ locate -r "mpg123[^/]*$" /usr/doc/mpg123-0.59r /usr/man/man1/mpg123.1.gz /usr/bin/mpg123 $
Строка mpg123[^/]*$ - просит locate найти те файлы в которых после подстроки mpg123 могут быть ноль или более символов, кроме символа /, после чего идет конец строки. Таким образом из результата поиска исключаются строки вида /usr/doc/mpg123-0.59r/BUGS.
Еще одна полезная возможность - это форма вызова locate -i. Параметр -i говорит о том что нужно произвести нечувствительный к регистру поиск:
$ locate "/etc/dir" /usr/local/share/emacs/21.1/etc/dired-ref.ps /usr/local/share/emacs/21.1/etc/dired-ref.tex $ locate -i "/etc/dir" /usr/local/share/emacs/21.1/etc/dired-ref.ps /usr/local/share/emacs/21.1/etc/dired-ref.tex /etc/DIR_COLORS $
Использование совместно с другими командами
Сам по себе locate не выполняет ничего кроме вывода имен нужных файлов. Однако вы не всегда можете удовлетворится лишь созерцанием имен и месторасположения найденных файлов. Здесь вам на помощь приходят любимые трубопроводы, конвейеры и прочие радости командной строки.
К примеру хотим получить кроме самих файлов еще и информацию о атрибутах этих файлов. В данном случае нам на помощь приходит подстановка команд:
$ locate crontab /usr/man/man1/crontab.1.gz /usr/man/man5/anacrontab.5.gz /usr/man/man5/crontab.5.gz /usr/bin/crontab /etc/anacrontab /etc/crontab $ ls -ld `!!` ls -ld `locate crontab` -rw-r--r-- 1 root root 370 Mar 3 2000 /etc/anacrontab -rw-r--r-- 1 root root 255 Aug 27 1999 /etc/crontab -rwsr-xr-x 1 root root 21816 Feb 3 2000 /usr/bin/crontab -rw-r--r-- 1 root root 1584 Feb 3 2000 /usr/man/man1/crontab.1.gz -rw-r--r-- 1 root root 669 Mar 3 2000 /usr/man/man5/anacrontab.5.gz -rw-r--r-- 1 root root 3495 Feb 3 2000 /usr/man/man5/crontab.5.gz $
В данном примере первой командой мы получили список интересующих нас файлов, а второй передали этот список команде ls -ld, в результате чего получили чудный список с требуемой информацией. Кто забыл чего делает `!!` читать тут Работаем с историей команд. Параметр -d сообщает ls что вместо содержимого каталогов, выводить их атрибуты.
Способ с подстановкой подходит в том случае если у нас не много файлов. В противном случае мы можем столкнутся с ограничением на длину строки параметров передаваемых ls -l. К примеру:
$ locate / | wc -l # <--- locate - выводит все файлы в системе # wc - подсчитывает их количество 70968 $ ls -ld `locate /` | wc -l bash: /bin/ls: Argument list too long 0 $
Как видим вариант не прошел. Поэтому если ожидается большое количество файлов на выходе, более предпочтительнее будет воспользоваться утилитой xargs которая просто читает свой входной поток, разбивает его на строки, а потом эти строки небольшими порциями скармливает программе переданной ей в качестве параметра. Чтобы было более понятно приведу простой пример в котором видно что делает xargs:
$ ls /usr/ X11R6 etc info man bin games kerberos sbin cvsroot i386-redhat-linux lib share dict i486-linux-libc5 libexec src doc include local tmp
$ ls /usr/ | xargs -n 5 echo X11R6 bin cvsroot dict doc etc games i386-redhat-linux i486-linux-libc5 include info kerberos lib libexec local man sbin share src tmp $
Здесь результат выполнения ls /usr/ направляется на вход xargs -n 5, который разбивает полученные строки по пять штук и передает их в качестве аргумента команде echo, как нетрудно догадаться число параметров задается с помощью параметра -n.
В нашем случае указывать количество параметров не требуется, так как оно в данном случае несущественно, главное чтобы ограничение на размер аргумента не было превышено, а эту задачу xargs решает без посторонней помощи:
$ locate / | xargs ls -ld | wc -l 70968 $
Как видим такой вариант в отличие от предыдущего сработал.
Использование загрузчика LILO
Приведем сценарий загрузки с использованием LILO.
Освободим часть дискового пространства и создадим на свободном месте раздел типа ext2 и раздел подкачки. Проведем процедуру инсталляции Linux, следуя рекомендациям из дистрибутива. При инсталляции установим LILO в MBR. (LILO можно расположить и в загрузочной записи раздела Linux, однако в таком случае в MBR должно быть нечто, способное его загрузить, скажем, стандартный загрузчик MS-DOS или Windows. Впрочем, необходимости применения такого варианта я не вижу). На следующем шаге нужно заставить LILO загружать операционную систему по выбору. LILO конфигурируется с помощью файла /etc/lilo.conf и команды /etc/lilo. Эта команда устанавливает (или переустанавливает) LILO. После того, как откорректирован файл /etc/lilo.conf, необходимо выполнить команду /etc/lilo, чтобы изменения вступили в силу. Эта команда устанавливает загрузчик системы, который будет активизирован во время следующей загрузки машины. Прежде, чем запускать /etc/lilo для модификации загрузочных процедур, следует выполнить эту команду с параметром -t. При этом будет выполнена вся процедура инсталляции загрузчика, кроме изменения map-файла, записи модифицированного загрузочного сектора и изменения таблицы разбиения диска, т.е. выполнен тест нового варианта. Если добавить опцию -v, это позволит убедиться в том, насколько сделанные изменения разумны.
Когда /sbin/lilo перезаписывает загрузочный сектор, он автоматически сохраняет старое содержимое в файле. Название файла по умолчанию - /boot/boot.NNNN, где NNNN соответствует номеру устройства, например, 0300 - это /dev/hda, 0800 - /dev/sda и т.д. Если такой файл уже существует, он не перезаписывается. Можно задать альтернативный файл для сохранения загрузочного сектора. Файл /boot/ boot.NNNN можно использовать для восстановления старого содержимого загрузочного сектора, если более простой метод его восстановления недоступен. Соответствующие команды таковы:
[root:~#] dd if=/boot/boot.0300 of=/dev/hda bs=446 count=1
или
[root:~#] dd if=/boot/boot.0800 of=/dev/sda bs=446 count=1
(bs равно 446, потому что восстанавливается только программа-загрузчик, не трогая таблицы разбиения диска).
Копию загрузочного сектора лучше иметь на дискете. В этом случае можно восстановить старую загрузочную запись MBR следующей командой (предполагается, что дискета смонтирована в каталог /mnt):
[root:~#] dd if=/mnt/MBR of=/dev/hda bs=446 count=1
Восстановить MBR при необходимости можно также командой /sbin/lilo с опцией -u. Надо только иметь в виду, что эта команда выполняется корректно при условии, что каталог LILO (а именно /boot) не изменялся со времени инсталляции.
Перезагрузить компьютер.
Исправление ошибок и дополнения
Если вы найдете какие-либо ошибки или пожелаете сделать какие-либо дополнения, я буду счастлив получить ваши патчи к коду. Особенно кстати будут автозаполнение параметров gcc и полная обработка параметров cvs. Еще одна огромная просьба – сделать код более портируемым без замедления работы. Патчи во всех этих областях приветствуются.
Исследуем дисковые структуры NTFS
Для исследования внутренних дисковых структур NTFS существует несколько общедоступных инструментов. Среди них - DiskEdit, встроенный инструмент тестирования NTFS, по недосмотру Microsoft оказавшийся на компакт-диске Windows NT 4.0 Service Pack 4 (SP4), одна из самых мощных известных мне программ просмотра NTFS. DiskEdit, окно которого представлено на Экране A, позволяет ознакомиться со структурами, образующими файлы и каталоги, а также с данными атрибутов и преобразовать пути файлов и каталогов во входные коды таблицы MFT. Документация по DiskEdit отсутствует, но я опубликовал учебное пособие в сборнике бесплатных бюллетеней Sysinternals Newsletter (http://www.sysinternals.com/newsletter.htm). Чтобы использовать DiskEdit вместе с Windows 2000, необходимо скопировать файлы ifsutil.dll, ulib.dll, untfs.dll и ufat.dll из каталога \winnt\system32 системы Windows NT в каталог, в котором нужно разместить DiskEdit.
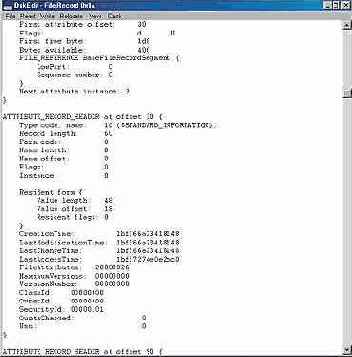 |
| Экран A. Утилита DiskEdit. |
Те, у кого нет компакт-диска с SP4, могут воспользоваться утилитой NTFS File Sector Information Utility (NFI), поставляемой Microsoft в составе пакета OEM Support Tools по адресу: http:\\support.microsoft.com/support/ kb/articles/q253/0/66.asp (помимо NFI в пакете OEM Support Tools имеются утилиты отладки и расширения отладчика ядра, с помощью которых администраторы и программисты могут анализировать аварийные дампы).
С помощью запускаемых из командной строки шаблонов NFI можно собрать информацию о конкретном файле или каталоге или обо всех файлах на томе, найти файл или каталог, в котором расположен данный логический сектор диска, а также отыскать файл или каталог, содержащий конкретный физический сектор. Например, команда
nfi C: 123
сообщает имя файла на томе C:, который содержится в 123 секторе тома. Чтобы исследовать структуры данных NTFS, можно воспользоваться этой же командой, не указывая номер сектора, и NFI выдаст подробную информацию об атрибутах всех файлов на диске. Можно ввести имя файла метаданных, описанных в статье, и просмотреть содержащиеся в них атрибуты. Например, если выполнить команду
nfi c:\$extend\$quota
на квотируемом томе, то будет видно, что файл $Quota содержит индексы с именами $O и $Q:
File 24 \$Extend\$Quota $STANDARD_INFORMATION (resident) $FILE_NAME (resident) $INDEX_ROOT $O (resident) $INDEX_ROOT $Q (resident)
Еще один источник информации о дисковой структуре NTFS - книга Гэри Неббета (издательство New Readers Publishing, 2000). В приложении приведены определения многих дисковых структур NTFS (в некоторых случаях отражены изменения, внесенные в Windows 2000) и содержится исходный текст Win32-программы, с помощью которой можно получить доступ к структурам данных в обход драйвера файловой системы NTFS и создать дамп содержимого тома.
назад
Врезки:
Рисунок 1. Индексация имен каталогов.
Статья является переводом текста Dru
Автор: Станислав Лапшанский, slapsh@kos-obl.kmtn.ru
Опубликовано: 01.06.2002
Оригинал: http://www.softerra.ru/freeos/18189/
Статья является переводом текста Dru Lavigne.
В этой статье, состоящей из двух частей, я хочу рассказать вам о процессах. В этой части мы узнаем, что такое процесс и как посмотреть информацию о ваших процессах. В следующей части мы посмотрим, как сделать что-нибудь полезное с этой информацией.
Как любая другая UNIX-система, FreeBSD является многозадачной, многопользовательской операционной системой. Это значит, что несколько пользователей могут выполнять несколько программ одновременно. Ядро системы отвечает за то, что каждая из этих программ гарантированно получит процессорное время, и что каждый пользователь увидит верные результаты, выданные этими программами.
Когда вы запускаете программу, она загружается в оперативную память, и после этого ее называют процессом, так как ее инструкции требуют обработки (процесса) процессором. Для того, что бы ядро могло разобраться какой пользователь запускал какие программы, каждому процессу присваивается идентификатор ID (иначе PID – process ID). Обычно PID ассоциируется с, и имеет такие же права, как пользователь, который запустил программу и как группа к которой принадлежит этот пользователь.
Не все программы запускаются пользователями, некоторые из них запускаются вашей FreeBSD во время старта системы и называются демонами. В свою очередь некоторые программы, или запускаются другими программами, или являются экземплярами самих себя. Первоначальную программу называют родительским процессом, а создаваемые им процессы – детьми.
Когда вы установили FreeBSD, для вас была создана файловая система процессов (procfs). Если вы напечатаете: $ more /etc/fstab
среди прочего, вы должны будете увидеть следующие строки: # Device Mountpoint FStype Options Dump Pass# proc /proc procfs rw 0 0
Когда вы просматриваете информацию о свободном пространстве на ваших дисках, вы можете заметить, что эта файловая система всегда заполнена на 100%: $ df
Filesystem Size Used Avail Capacity Mounted on procfs 4.0K 4.0K 0B 100% /proc
Это нормально, так как файловая система процессов не предназначена для хранения файлов, создаваемых пользователями. Эта файловая система используется командами ps и w для получения информации о запущенных процессах. Обратите внимание, что файловая система процессов смонтирована в каталоге /proc. Давайте поглядим на содержимое /proc используя команду ls с ключом «C» для сортировки вывода по столбцам и с ключом «F» для печати каталогов со слешем («/»): $ cd /proc $ ls -CF ./ 175/ 2072/ 301/ 315/ ../ 176/ 227/ 307/ 316/ 0/ 177/ 261/ 308/ 317/ 1/ 178/ 27/ 309/ 318/ 110/ 181/ 273/ 310/ 319/ 163/ 197/ 290/ 311/ 320/ 166/ 199/ 292/ 312/ 4/ 171/ 2/ 3/ 313/ 5/ 173/ 202/ 30/ 314/ curproc@
Заметьте, что каждая запись, кроме одной, это каталог с именем состоящим из цифр. Эти числа соответствуют идентификаторам PID запущенных процессов. Последняя запись, curproc, это символьная ссылка, поскольку она заканчивается знаком «@». Для того что бы понять на какой файл указывает эта ссылка, напечатайте: $ file curproc curproc: symbolic link to 2072
Это означает, что ссылка curproc указывает на какой-то процесс. Если вы напишете: $ man 5 procfs
вы сможете прочитать, что на самом деле curproc указывает на текущий процесс, который обращается к системе /proc. Таким образом моя команда ls имела идентификатор PID равный 2072.
Теперь давайте посмотрим какая информация хранится о каждом запущенном процессе, путем просмотра содержимого одного из этих каталогов: $ ls -CF 197 ./ ctl file@ mem regs ../ dbregs fpregs note rlimit cmdline etype map notepg status
Все записи – это обычные файлы, исключая символьную ссылку с именем file. Однако мы совершенно не представляем себе какие данные содержат эти файлы. Попробуем узнать: $ file * cmdline: empty ctl: empty dbregs: MS Windows COFF Unknown CPU etype: empty file: symbolic link to /usr/sbin/inetd fpregs: data map: empty mem: empty note: empty notepg: empty regs: data rlimit: empty status: empty
Пожалуй это не выглядит так, как если бы мы могли посмотреть эти файлы сами, поскольку они не содержат читабельного текста. Это создает ощущение, что эта файловая система хранит данные полезные для ядра системы. Однако, не смотря на то, что вы не сможете посмотреть данные напрямую, вы можете воспользоваться утилитами w и ps, которые знают как интерпретировать и показать информацию содержащуюся в этих файлах.
Начнем с команды w: $ whatis w w(1) - display who is logged in and what they are doing w(1) - показывает кто сейчас находится в системе и что они делают
$ w 10:43AM up 17:50, 4 users, load averages: 0.00, 0.00, 0.00 USER TTY FROM LOGIN@ IDLE WHAT genisis v0 - 9:46AM - w genisis v1 - Sat04PM 2:02 -csh (csh) genisis v2 - Sat08PM - -csh (csh) genisis v3 - Sat05PM 2:02 -csh (csh)
Первая строка показывает текущее системное время, затем время непрерывной работы вашей системы с последней перезагрузки, количество пользователей, в данный момент находящихся в системе и среднее количество заданий в очереди на обработку за 1, 5, 15 последних минут.
Оставшиеся строки показывают регистрационные имена пользователей, названия терминалов с которых зашли эти пользователи, время захода пользователей в систему, время прошедшее после последнего нажатия пользователем какой-нибудь клавиши и имя и параметры текущего пользовательского процесса.
Если мы воспользуемся командой w с ключом «d», то мы получим немного отличающийся вывод, поскольку w будет показывать все процессы которые пользователь выполняет с его терминала: w -d 10:55AM up 18:02, 4 users, load averages: 0.00, 0.00, 0.00 USER TTY FROM LOGIN@ IDLE WHAT 2100 -csh (csh) 2104 su (csh) 2235 w -d genisis v0 - 9:46AM - w -d 313 -csh (csh) genisis v1 - Sat04PM 2:14 -csh (csh) 314 -csh (csh) genisis v2 - Sat08PM - -csh (csh) 315 -csh (csh) genisis v3 - Sat05PM 2:14 -csh (csh)
Числа над названием терминала это идентификаторы PID процессов. Если вы прочитаете страницу руководства по команде w, то вы узнаете, что это отличная утилита для того что бы быстро посмотреть кто сейчас, и с каких терминалов, находится в системе и что они делают. Однако она не предназначена для детального выяснения информации о процессах, так как это работа утилиты ps. Если вы просто напишете: ps
вы получите базовую информацию о процессах, которые вы запустили, примерно вот так: PID TT STAT TIME COMMAND 2100 v0 Ss 0:00.13 -csh (csh) 2286 v0 R+ 0:00.00 ps 313 v1 Is+ 0:00.13 -csh (csh) 314 v2 Is+ 0:00.21 -csh (csh) 315 v3 Is 0:00.12 -csh (csh)
Если читать выдачу слева направо, то команда ps показывает PID, название и тип терминала, состояние, затраченное процессорное время (суммируя системное и пользовательское время) и ассоциированную команду, для процессов, которые запущены пользователем выполняющим команду ps.
«Состояние», это новый термин, который предоставляет различную информацию о запущенном процессе. При чтении столбца состояния (STAT), первая буква показывает текущий режим выполнения процесса. Возможные значения этой буквы: D – процесс находится в ожидании дисковой (или короче, непрерываемой) операции I – процесс в ожидающем режиме (процесс «спит» более 20 секунд) J – процесс в «тюрьме» (см. man 2 jail – прим. переводчика) R – процесс выполняется S – процесс «спит» менее 20 секунд T – процесс остановлен Z – мертвый (зомби) процесс
Итак у меня выполняется один процесс (сама команда ps), одна оболочка csh, которая ничего не делала последние 20 секунд и три оболочки, которые ничего не делают более 20 секунд. Символ «+» показывает что три моих процесса выполняются на переднем плане (foreground-процессы), «s» говорит о том, что четыре моих процесса являются начальными в сеансе. Не беспокойтесь, если некоторая информация о состоянии процесса не представляется вам важной, действительно, если вы не программист, то некоторая ее часть не будет вам нужна.
Имейте в виду, что команда ps без ключей, по умолчанию покажет вам только ваши процессы, для того что бы посмотреть процессы всех пользователей запущенные на вашем компьютере, используйте ключ «a»: ps -a PID TT STAT TIME COMMAND 2100 v0 Ss 0:00.18 -csh (csh) 2403 v0 R+ 0:00.00 ps -a 313 v1 Is+ 0:00.13 -csh (csh) 314 v2 Is+ 0:00.25 -csh (csh) 315 v3 Is+ 0:00.12 -csh (csh) 316 v4 Is+ 0:00.01 /usr/libexec/getty Pc ttyv4 317 v5 Is+ 0:00.01 /usr/libexec/getty Pc ttyv5 318 v6 Is+ 0:00.01 /usr/libexec/getty Pc ttyv6 319 v7 Is+ 0:00.01 /usr/libexec/getty Pc ttyv7
Вы можете решить, что более удобно видеть какие пользователи запустили какую команду, для этого воспользуйтесь ключом «u»: ps -au USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND genisis 2404 0.0 0.2 428 244 v0 R+ 12:26PM 0:00.00 ps -au root 273 0.0 0.4 620 448 con- I+ 4:53PM 0:00.02 /bin/sh /usr/loc root 292 0.0 0.4 624 452 con- I+ 4:53PM 0:00.01 /bin/sh /usr/loc genisis 313 0.0 0.8 1328 944 v1 Is+ 4:53PM 0:00.13 -csh (csh) genisis 314 0.0 0.8 1336 960 v2 Is+ 4:53PM 0:00.25 -csh (csh) genisis 315 0.0 0.8 1328 944 v3 Is+ 4:53PM 0:00.12 -csh (csh) root 316 0.0 0.5 920 628 v4 Is+ 4:53PM 0:00.01 /usr/libexec/get root 317 0.0 0.5 920 628 v5 Is+ 4:53PM 0:00.01 /usr/libexec/get root 318 0.0 0.5 920 628 v6 Is+ 4:53PM 0:00.01 /usr/libexec/get root 319 0.0 0.5 920 628 v7 Is+ 4:53PM 0:00.01 /usr/libexec/get genisis 2100 0.0 0.8 1336 960 v0 Ss 9:46AM 0:00.19 -csh (csh)
Мне показалось, что читать вывод команды ps проще, если я воспользуюсь ключом «с», который не выводит путь к командам, а показывает только имя: ps -auc USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND genisis 2414 0.0 0.2 428 244 v0 R+ 12:31PM 0:00.00 ps root 273 0.0 0.4 620 448 con- I+ 4:53PM 0:00.02 sh root 292 0.0 0.4 624 452 con- I+ 4:53PM 0:00.01 sh genisis 313 0.0 0.8 1328 944 v1 Is+ 4:53PM 0:00.13 csh genisis 314 0.0 0.8 1336 960 v2 Ss+ 4:53PM 0:00.26 csh genisis 315 0.0 0.8 1328 944 v3 Is+ 4:53PM 0:00.12 csh root 316 0.0 0.5 920 628 v4 Is+ 4:53PM 0:00.01 getty root 317 0.0 0.5 920 628 v5 Is+ 4:53PM 0:00.01 getty root 318 0.0 0.5 920 628 v6 Is+ 4:53PM 0:00.01 getty root 319 0.0 0.5 920 628 v7 Is+ 4:53PM 0:00.01 getty genisis 2100 0.0 0.8 1336 960 v0 Ss 9:46AM 0:00.21 csh
Однако, пока мы не видим все процессы, которые запущены на этой машине. Для того что бы посмотреть какие запущены демоны воспользуемся ключом «x». Вывод скорее всего будет длинным, поэтому перенаправим его команде more: ps -aucx | more USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND genisis 2417 0.0 0.2 428 244 v0 R+ 12:32PM 0:00.00 ps root 1 0.0 0.2 532 304 ?? ILs Sat11AM 0:00.06 init root 2 0.0 0.0 0 0 ?? DL Sat11AM 0:00.11 pagedaemon root 3 0.0 0.0 0 0 ?? DL Sat11AM 0:00.00 vmdaemon root 4 0.0 0.0 0 0 ?? DL Sat11AM 0:00.20 bufdaemon root 5 0.0 0.0 0 0 ?? DL Sat11AM 0:09.53 syncer root 27 0.0 2.0 70780 2540 ?? ILs Sat11AM 0:00.08 mount_mfs root 30 0.0 0.1 208 92 ?? Is Sat11AM 0:00.00 adjkerntz root 110 0.0 0.3 536 368 ?? Is 4:53PM 0:00.03 dhclient root 163 0.0 0.5 904 608 ?? Ss 4:53PM 0:00.53 syslogd daemon 166 0.0 0.4 916 556 ?? Is 4:53PM 0:00.01 portmap root 181 0.0 0.5 263052 576 ?? Is 4:53PM 0:00.00 rpc.statd root 197 0.0 0.6 1028 764 ?? Is 4:53PM 0:00.02 inetd root 199 0.0 0.6 956 700 ?? Is 4:53PM 0:00.64 cron root 202 0.0 1.0 1424 1216 ?? Is 4:53PM 0:00.66 sendmail root 227 0.0 0.4 876 488 ?? Is 4:53PM 0:00.34 moused root 273 0.0 0.4 620 448 con- I+ 4:53PM 0:00.02 sh root 292 0.0 0.4 624 452 con- I+ 4:53PM 0:00.01 sh genisis 313 0.0 0.8 1328 944 v1 Is+ 4:53PM 0:00.13 csh genisis 314 0.0 0.8 1336 960 v2 Ss+ 4:53PM 0:00.26 csh genisis 315 0.0 0.8 1328 944 v3 Is+ 4:53PM 0:00.12 csh root 316 0.0 0.5 920 628 v4 Is+ 4:53PM 0:00.01 getty root 317 0.0 0.5 920 628 v5 Is+ 4:53PM 0:00.01 getty root 318 0.0 0.5 920 628 v6 Is+ 4:53PM 0:00.01 getty root 319 0.0 0.5 920 628 v7 Is+ 4:53PM 0:00.01 getty genisis 2100 0.0 0.8 1336 960 v0 Ss 9:46AM 0:00.21 csh root 2239 0.0 3.6 5012 4512 ?? Ss 10:57AM 0:00.40 perl root 2240 0.0 3.6 5012 4512 ?? I 10:57AM 0:00.02 perl root 0 0.0 0.0 0 0 ?? DLs Sat11AM 0:00.06 swapper
Вот это да! Неудивительно, что ядру приходится давать каждому процессу свои идентификатор для того что бы отслеживать все что твориться в вашей FreeBSD. Если при многостраничном выводе вам трудно запомнить какой столбец что означает, воспользуйтесь ключом «h», для того что бы заставить команду ps переписывать заголовки столбцов при многостраничном выводе.
Вы могли заметить, что состав столбцов вывода расширился, когда мы добавили ключ «u», из вновь появившихся, наиболее интересны столбцы «%CPU» и «%MEM». Время от времени вам может понадобиться отсортировать вывод команды ps в порядке уменьшения использования памяти или процессора, а не по идентификаторам. Для сортировки по размеру используемой памяти применяется ключ «m», а по используемому процессорному времени – ключ «r». ps -m PID TT STAT TIME COMMAND 314 v2 Ss+ 0:00.28 -csh (csh) 2100 v0 Ss 0:00.27 -csh (csh) 313 v1 Is+ 0:00.14 -csh (csh) 315 v3 Is+ 0:00.12 -csh (csh) 2570 v0 R+ 0:00.00 ps -m
ps -r PID TT STAT TIME COMMAND 313 v1 Is+ 0:00.14 -csh (csh) 314 v2 Ss+ 0:00.28 -csh (csh) 315 v3 Is+ 0:00.12 -csh (csh) 2100 v0 Ss 0:00.27 -csh (csh) 2571 v0 R+ 0:00.00 ps -r
Ключи команды ps, которые я описал, на практике используются наиболее часто. Вы можете почитать руководство по команде ps для того, что бы узнать о остальных ключах, и после этого выбрать комбинацию ключей, которая бы наиболее соответствовала вашим потребностям.
Когда вы используете команду ps, вы можете увидеть процессы, о которых никогда раньше не слышали. В этом случае, для того что бы найти страницу руководства, способную пролить свет на тайну, используйте команду whatis. Например, являясь очень любопытным субъектом, я попробовал следующее: whatis init syncer adjkerntz inetd portmap rpc.statd init(8) - process control initialization (процесс контролирующий инициализацию) syncer(4) - filesystem synchronizer kernel process (процесс ядра синхронизирующий файловую систему) adjkerntz(8) - adjust local time CMOS clock to reflect time zone changes and keep current timezone offset for the kernel (настраивает часы компьютера согласно изменениям часового пояса, а так же хранит текущее смещение относительно часового пояса для ядра) inetd.conf(5), inetd(5) - internet super-server (интернет-суперсервер) portmap(8) - RPC program, version to DARPA port mapper (программа RPC, версия DARPA распределителя портов) rpc.statd(8) - host status monitoring daemon (демон мониторинга системы)
Это заставило меня на некоторое время заняться чтением. Это должно дать и вам много поводов для занятий перед следующей частью этой статьи, в которой мы посмотрим, что мы можем сделать с этими новыми знаниями.
Вниманию вебмастеров: использование данной статьи возможно только в соответствии
с правилами использования материалов сайта «Софтерра» (http://www.softerra.ru/site/rules/)
Станислав Лапшанский,
Автор: Станислав Лапшанский, slapsh@kos-obl.kmtn.ru
Опубликовано: 02.07.2002
Оригинал: http://www.softerra.ru/freeos/18735/
Некоторые из сигналов использовались пользователями столь часто, что получили свои клавиатурные сокращения. Для просмотра этих сокращений посмотрите четыре последние строки вывода команды stty -e: stty -e discard dsusp eof eol eol2 erase intr kill lnext ^O ^Y ^D <undef> <undef> ^H ^C ^U ^V min quit reprint start status stop susp time werase 1 ^\ ^R ^Q ^T ^S ^Z 0 ^W
Символ «^» означает что вы должны нажать клавишу «ctrl», а затем указанную за ним букву. Обратите внимание, что три сигнала были привязаны к управляющим последовательностям:
^C привязан к сигналу INT (сигнал 2) ^\ привязан к сигналу QUIT (сигнал 3) ^Z привязан к сигналу TSTP (сигнал 18, хотя здесь он называется susp)
Не путайте слово «kill» в выводе команды stty с сигналом KILL (сигнал 9). Комбинация ^U удаляет строку, а не шлет сигнал номер 9. Для того что бы в этом убедиться, напечатайте в командной оболочке длинную строку, а затем нажмите ^U.
Но как послать сигнал, который не имеет соответствующей комбинации клавиш? Используйте для этого команду kill. whatis kill kill(1) - terminate or signal a process (уничтожение или сигнализация процессу) kill(2) - send signal to a process (послать сигнал процессу)
Есть пара способов использования команды kill. Если вы просто напечатаете: kill PID
то по умолчанию процессу с идентификатором PID будет послан сигнал TERM. Если вы хотите послать какой-нибудь другой сигнал, то в команде укажите его название или номер: kill -название_сигнала PID
или kill -номер_сигнала PID
Таким образом команды kill PID
kill -TERM PID
kill -15 PID
эквивалентны. Не забывайте, что в UNIX имеет значение регистр набранных команд, если вы напечатаете: kill -term PID
то получите следующее сообщение об ошибке: term: Unknown signal; kill -l lists all signals.
Итак теперь мы знаем о каждом из 31 возможных сообщений, а так же можем посылать их различным процессам. Давайте рассмотрим причины, по которым вам может потребоваться послать процессу сигнал. Когда вы прорабатываете какой-нибудь вопрос используя FreeBSD Handbook или другое руководство, их авторы часто обучают как и что менять в тех или иных конфигурационных файлах, а затем говорят вам о необходимости послать сигнал HUP. Дело в том, что большинство процессов прочитывают свои конфигурационные файлы только при первоначальном запуске. Сигнал HUP говорит процессу, что он должен прекратить выполнение. После того как процесс перезапустится, он перечитает конфигурационные файлы и внесенные в них изменения вступят в силу. Аналогичным образом, когда вы выходите командой logout из терминала, сигнал HUP рассылается всем процессам, которые были запущены на этом терминале. Это значит, что все процессы которые выполнялись на этом терминале будут остановлены.
Иногда вы можете запустить процесс и захотеть его остановки, до того, как он завершится в штатном режиме. Например в приливе вдохновения вы можете решить, что вам необходимо посмотреть имена всех файлов в вашей системе. Это можно сделать написав следующее: find / -print | more
Однако, вероятнее всего вы быстро утомитесь нажимать пробел и поймете, что на самом деле вам вовсе не хочется в данный момент просматривать список всех ваших файлов. Другими словами вам захочется подать прерывающий сигнал. Один из путей сделать это, нажать на терминале «Ctrl+C»: ^C
То, что на вашем терминале появится приглашение интерпретатора команд, свидетельствует о том, что посланный вами сигнал INT сработал.
Опять выполните ту же самую команду find, но в этот раз пошлите сигнал 3, нажав на клавиатуре «Ctrl+\»: ^
Теперь, перед тем, как вы получите приглашение интерпретатора команд, вы увидите следующее сообщение: Quit (core dumped) Выход (сохранен «посмертный» дамп памяти)
Если вы воспользуйтесь комбинацией Alt+F1, что бы посмотреть сообщения системной консоли, там вы увидите сообщение примерно следующего содержания: Nov 19 13:50:09 genisis /kernel: pid 806 (find), uid 1001: exited on signal 3 Nov 19 13:50:09 genisis /kernel: pid 807 (more), uid 1001: exited on signal 3 (core dumped)
Если теперь вы вернетесь на предыдущий терминал и посмотрите список файлов в каталоге, среди прочего вы обязательно найдете файл more.core. Обычно вам никогда не потребуется посылать процессу сигнал номер 3, если конечно вы не программист, который знает как использовать отладчик ядра. Я включил этот пример в статью для того что бы показать разницу между сигналами 2 и 3. Удаляйте core-файлы без опаски.
Межпроцессное взаимодействие (в оригинале используется термин «межпроцессные коммуникации» – прим. переводчика) практически ни чем не отличается от любых других видов коммуникаций: вы или какой-нибудь процесс можете послать сигнал в надежде на определенный результат, однако процесс получающий этот сигнал распоряжается с ним «на свое усмотрение». Помните, что процессы – это всего лишь запущенные программы. Большинство программ используют процедуры «обработки сигналов», применяемые для того, что бы решать что и как надо делать с поступившими сигналами в данный момент времени. Обычно, если вы посылаете процессу какой-нибудь из сигналов останавливающих выполнение программы, процедура обработки сигналов этого процесса пытается корректно закрыть все используемые программой файлы для предотвращения потери данных после останова. В некоторых случаях обработчик сигналов может просто проигнорировать поступивший процессу сигнал и отклонить запрос на останов программы (обычно так поступают зависшие программы, которые на момент поступления сигнала уже не работают должным образом – прим. переводчика).
Однако (к счастью – прим. переводчика), некоторые сигналы не могут быть проигнорированы программой. Это например девятый и семнадцатый сигналы. Представим, что вы хотите остановить процесс который вы некоторое время назад запустили. Воспользовавшись связкой команды ps и grep, вы узнали PID процесса, а затем при помощи команды kill послали ему сигнал TERM, а затем решили проверить остановлен ли процесс повторив команду ps: ps | grep processname
kill PID
ps | grep processname
Однако при повторе команды ps вы опять обнаружили этот процесс в списке, а это значит, что по каким-то причинам сигнал TERM был проигнорирован. Любая из этих двух команд исправит ситуацию: kill -9 PID
или
kill -KILL PID
Если вы теперь повторите команду ps, то вы должны будете получить пустой список, что свидетельствует об успешном останове процесса.
Вы можете спросить: «Почему бы всегда не посылать процессам сигнал 9, если он не может быть игнорирован?». Дело в том, что сигнал 9 на самом деле просто «убивает» процесс, не давая ему времени на корректное сохранение всех обработанных данных, что означает, что при применении сигнала 9 могут быть потеряны данные (никогда не применяйте сигнал номер 9 без крайней на то необходимости – прим. переводчика). Намного лучше попробовать для начала послать процессу какой-нибудь другой сигнал останова, а сигнал номер 9 иметь «про запас» для процессов упрямо игнорирующих другие сигналы. Не забывайте так же, что если вы работаете от имени обычного пользователя, то вы сможете посылать сигналы только процессам, владельцем которых являетесь. Суперпользователь root может посылать сигналы любым процессам.
Может возникнуть ситуация, когда вам захочется остановить все принадлежащие вам процессы. Результаты этого действия будут отличаться в зависимости от того находитесь ли вы в системе как обычный или как суперпользователь.
Продемонстрируем это. Войдите в систему на другом терминале и введите команду ps: ps PID TT STAT TIME COMMAND 316 v0 Ss 0:00.39 -csh (csh) 957 v0 R+ 0:00.00 ps 317 v1 Is+ 0:00.20 -csh (csh) 915 v2 Is 0:00.12 -csh (csh) 941 v2 I+ 0:00.09 lynx 942 v2 Z+ 0:00.00 (lynx) 913 v3 Is 0:00.12 -csh (csh) 946 v3 I+ 0:00.01 /bin/sh /usr/X11R6/bin/startx 951 v3 I+ 0:00.04 xinit /home/genisis/.xinitrc -- 955 v3 S 0:03.00 xfce
В этом примере я вошел в систему с терминалов 0, 1, 2, 3. Я запустил команду ps с консоли (терминал 0 по совместительству выполняет роль системной консоли – прим. переводчика), на первом терминале запущена оболочка командного процессора, на втором – запущен браузер lynx и на третьем у меня запущен сеанс X Window. И так я являюсь владельцем 10 процессов. Если в команде kill я воспользуюсь идентификатором процесса (PID) равным -1, я отправлю указанный в команде сигнал всем принадлежащим мне процессам. так попробуем послать сигнал TERM таким образом: kill -1
А теперь проверим результаты, воспользовавшись командой ps: ps PID TT STAT TIME COMMAND 316 v0 Ss 0:00.41 -csh (csh) 969 v0 R+ 0:00.00 ps 317 v1 Ss+ 0:00.21 -csh (csh) 915 v2 Is+ 0:00.12 -csh (csh) 913 v3 Is+ 0:00.12 -csh (csh)
Обратите внимание – мы остановили шесть процессов, однако четыре оставшиеся проигнорировали сигнал TERM. Давайте будем более агрессивными: kill -KILL -1
ps PID TT STAT TIME COMMAND 317 v1 Ss 0:00.22 -csh (csh) 995 v1 R+ 0:00.00 ps
Если вы «пройдетесь» по тем четырем терминалам, на которых выполнялись ваши программы, то на трех из них вы увидите приглашение войти в систему. Последняя команда kill уничтожила все процессы, за исключением своего родительского процесса, т.е. командного интерпретатора C shell, в котором вы набрали команду kill (так произошло потому, что структура процессов в UNIX древовидна и каждый процесс должен иметь своего родителя – прим. переводчика).
Обратите внимание, что если вы допустите ошибку при наборе команды и напишете: kill 1
вместо kill -1
то вы получите сообщение об ошибке: 1: Operation not permitted 1: Действие запрещено
Дело в том, что -1 это специальный идентификатор процесса, который обозначает «все процессы», а 1 это идентификатор процесса с именем init. Только суперпользователь может останавливать процесс init. К тому же суперпользователь должен останавливать процесс init только при условии того, что он знает что делает.
Теперь давайте поглядим что произойдет, если мы повторим то же упражнение, но только от имени суперпользователя. Для начала на моем тестовом компьютере (где выполняются следующие программы: apache, mysql, squid, nfs и т.п.) я выполню команду ps: ps -acux USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND genisis 1050 0.0 0.2 428 244 v0 R+ 4:08PM 0:00.00 ps root 1 0.0 0.2 532 304 ?? ILs 5:10AM 0:00.04 init root 2 0.0 0.0 0 0 ?? DL 5:10AM 0:00.03 pagedaemon root 3 0.0 0.0 0 0 ?? DL 5:10AM 0:00.00 vmdaemon root 4 0.0 0.0 0 0 ?? DL 5:10AM 0:00.04 bufdaemon root 5 0.0 0.0 0 0 ?? DL 5:10AM 0:02.62 syncer root 27 0.0 2.0 70780 2540 ?? ILs 5:10AM 0:00.08 mount_mfs root 30 0.0 0.1 208 92 ?? Is 5:10AM 0:00.00 adjkerntz root 110 0.0 0.3 536 368 ?? Ss 10:10AM 0:00.22 dhclient root 163 0.0 0.5 904 608 ?? Ss 10:10AM 0:00.19 syslogd daemon 166 0.0 0.4 916 556 ?? Is 10:10AM 0:00.01 portmap root 171 0.0 0.3 504 320 ?? Is 10:10AM 0:00.00 mountd root 173 0.0 0.1 360 172 ?? Is 10:10AM 0:00.01 nfsd root 175 0.0 0.1 352 164 ?? I 10:10AM 0:00.00 nfsd root 176 0.0 0.1 352 164 ?? I 10:10AM 0:00.00 nfsd root 177 0.0 0.1 352 164 ?? I 10:10AM 0:00.00 nfsd root 178 0.0 0.1 352 164 ?? I 10:10AM 0:00.00 nfsd root 181 0.0 0.5 263052 576 ?? Is 10:10AM 0:00.00 rpc.statd root 197 0.0 0.6 1028 764 ?? Is 10:10AM 0:00.02 inetd root 199 0.0 0.6 956 700 ?? Ss 10:10AM 0:00.19 cron root 202 0.0 1.0 1424 1216 ?? Is 10:10AM 0:00.20 sendmail root 227 0.0 0.4 876 488 ?? Is 10:10AM 0:00.00 moused root 261 0.0 1.4 2068 1704 ?? Ss 10:10AM 0:00.98 httpd root 275 0.0 0.4 620 448 con- I+ 10:10AM 0:00.02 sh root 293 0.0 0.4 624 452 con- I+ 10:10AM 0:00.01 sh mysql 303 0.0 1.4 10896 1796 con- S+ 10:10AM 0:00.43 mysqld nobody 305 0.0 4.7 6580 5928 con- S+ 10:10AM 0:05.42 squid nobody 308 0.0 1.4 2092 1704 ?? I 10:10AM 0:00.00 httpd nobody 309 0.0 1.4 2092 1704 ?? I 10:10AM 0:00.00 httpd nobody 310 0.0 1.4 2092 1704 ?? I 10:10AM 0:00.00 httpd nobody 311 0.0 1.4 2092 1704 ?? I 10:10AM 0:00.00 httpd nobody 312 0.0 1.4 2092 1704 ?? I 10:10AM 0:00.00 httpd genisis 317 0.0 0.8 1336 960 v1 Is+ 10:10AM 0:00.24 csh root 320 0.0 0.5 920 628 v4 Is+ 10:10AM 0:00.02 getty root 321 0.0 0.5 920 628 v5 Is+ 10:10AM 0:00.01 getty root 322 0.0 0.5 920 628 v6 Is+ 10:10AM 0:00.01 getty root 323 0.0 0.5 920 628 v7 Is+ 10:10AM 0:00.01 getty nobody 324 0.0 0.3 832 348 ?? Is 10:10AM 0:00.01 unlinkd root 992 0.0 0.5 920 628 v2 Is+ 3:46PM 0:00.01 getty root 993 0.0 0.5 920 628 v3 Is+ 3:46PM 0:00.01 getty genisis 994 0.0 0.8 1336 956 v0 Ss 3:46PM 0:00.14 csh root 0 0.0 0.0 0 0 ?? DLs 5:10AM 0:00.02 swapper
Теперь я пошлю сигнал KILL специальному идентификатору -1 от имени суперпользователя: $ su Password:
# kill -9 -1
Эта команда произвела на меня большее впечатление чем предыдущая, поскольку я был выкинут из командного интерпретатора в котором только что набрал команду kill. После того, как я опять вошел в систему, я определил масштаб разрушений следующим образом: ps -acux USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND genisis 1070 0.0 0.2 396 244 v0 R+ 4:11PM 0:00.00 ps root 1 0.0 0.2 532 304 ?? ILs 5:10AM 0:00.05 init root 2 0.0 0.0 0 0 ?? DL 5:10AM 0:00.03 pagedaemon root 3 0.0 0.0 0 0 ?? DL 5:10AM 0:00.00 vmdaemon root 4 0.0 0.0 0 0 ?? DL 5:10AM 0:00.05 bufdaemon root 5 0.0 0.0 0 0 ?? DL 5:10AM 0:02.65 syncer root 1059 0.0 0.5 920 628 v3 Is+ 4:10PM 0:00.01 getty root 1060 0.0 0.5 920 628 v2 Is+ 4:10PM 0:00.01 getty root 1061 0.0 0.5 920 628 v7 Is+ 4:10PM 0:00.01 getty root 1062 0.0 0.5 920 628 v6 Is+ 4:10PM 0:00.01 getty root 1063 0.0 0.5 920 628 v5 Is+ 4:10PM 0:00.01 getty genisis 1064 0.0 0.8 1336 956 v0 Ss 4:10PM 0:00.12 csh root 1065 0.0 0.5 920 628 v4 Is+ 4:10PM 0:00.01 getty root 1066 0.0 0.5 920 628 v1 Is+ 4:10PM 0:00.01 getty root 0 0.0 0.0 0 0 ?? DLs 5:10AM 0:00.02 swapper
Когда суперпользователь посылает сигнал идентификатору -1, он рассылается всем процессам за исключением системных. Если этим сигналом будет KILL, то вы наслушаетесь жалоб от простых пользователей, у которых будут потеряны все открытые ими, но не сохраненные файлы данных.
Это является одной из причин, по которой только суперпользователь может выполнять команды reboot и halt. Когда одна из этих команд запускается на выполнение, то всем процессам рассылается сигнал TERM, для того что бы дать им шанс для сохранения данных, поскольку за сигналом TERM, через некоторое время, следует сигнал KILL, который посылается для того что бы гарантированно уничтожить все процессы.
В следующей статье я продолжу эту тему, заострив внимание на процессах init и getty.
Исследуем процессы Часть Демон init
Автор: Станислав Лапшанский, slapsh@kos-obl.kmtn.ru
Опубликовано: 09.07.2002
Оригинал: http://www.softerra.ru/freeos/18852/
Статья является переводом текста Dru Lavigne, опубликованного по адресу: http://www.onlamp.com/pub/a/bsd/2000/11/28/FreeBSD_Basics.html
В последних двух частях этой статьи (см. «Исследуем процессы». Часть 1 и 2), мы узнали как получать список запущенных процессов, и как ими управлять. Сегодня мы посмотрим как на самом деле были запущены все эти процессы.
При загрузке FreeBSD происходит масса интересных вещей. Я не буду здесь всех их детально описывать, поскольку существует FreeBSD Handbook, в которой работа по тщательному описанию процесса загрузки уже проделана.
Вероятно вы замечали, что в процессе загрузки ядро FreeBSD выясняет список доступного оборудования и выводит его на системную консоль. Когда сведения об оборудовании собраны, ядро запускает два процесса: процесс 0 (swapper) и процесс 1 (init).
init это демон, который отвечает за процесс инициализации системы. Без него ни один процесс не сможет запуститься. Во время загрузки init выполняет две важные задачи: во-первых он запускает стартовые сценарии rc, а затем инициализирует терминалы, для того что бы в систему могли войти пользователи. Давайте пройдемся по функциям демона init, начав с rc: whatis rc rc(8) - command scripts for auto-reboot and daemon startup rc(8) - сценарий для авто-перезагрузки и запуска демонов
На самом деле эти сценарии находятся в каталоге /etc/rc. Обычно конфигурационным файлам, соответствуют страницы раздела номер 5 интерактивного руководства, в котором вы можете найти описания того, как правильно менять конфигурационные файлы. Однако, если вы напечатаете: man 5 rc
То вы получите следующее сообщение: No entry for rc in section 5 of the manual В разделе номер 5 руководства, сведений о rc не найдено
Кажется немного странным, что сведения о конфигурационных файлах находятся в восьмом разделе руководства, который обычно содержит сведения о командах причастных к обслуживанию системы или системным операциям, в общем это раздел о демонах. Давайте поглядим повнимательнее на файл /etc/rc и посмотрим что у него внутри: more /etc/rc # System startup script run by init on autoboot # or after single-user. # Output and error are redirected to console by init, # and the console is the controlling terminal. # Note that almost all of the user-configurable behavior # is no longer in # this file, but rather in /etc/defaults/rc.conf. # Please check that file first before contemplating any changes # here. If you do need to change this file for some reason, we # would like to know about it. # Сценарий начальной загрузки системы, запускаемый # процессом init в процессе загрузки или после # однопользовательского режима. # Результаты работы и ошибки передаются на системную # консоль при помощи процесса init, в тоже время консоль это # управляющий терминал. # Обратите внимание – практически все что захочет # конфигурировать пользователь вынесено из этого файла и # находится в /etc/defaults/rc.conf. Пожалуйста посмотрите # него до того, как задумаете вносить исправления в этот файл. # Если вы знаете причину по которой вам необходимо внести # в этот файл изменения, то сообщите ее нам.
Выглядит так как будто мы не должны возиться с этим файлом самостоятельно. Судя по всему здесь должны находиться очень важные вещи для правильной загрузки нашей системы. Для того что бы понять что на самом деле происходит во время этой фазы загрузки, давайте выборочно посмотрим на некоторые важные куски этого файла. Заметьте, что все сообщения и ошибки выдаваемые сценарием rc процесс init переправляет на терминал. (Мои комментарии будут отмечены табуляцией, строки прижатые влево взяты из файла /etc/rc). Первым делом сценарий rc устанавливает переменную PATH, для того что бы иметь возможность находить исполняемые файлы в вашей FreeBSD.
PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/sbin
Затем rc получает содержимое файлов /etc/defaults/rc.conf и /etc/rc.conf:
# If there is a global system configuration file, suck it in. # Если это глобальный конфигурационный файл, то применить его if [ -f /etc/defaults/rc.conf ]; then . /etc/defaults/rc.conf elif [ -f /etc/rc.conf ]; then . /etc/rc.conf fi
Затем делается проверка целостности файловых систем. Если вы некорректно завершили работу вашей FreeBSD, то вы будете оповещены об этом на данном этапе загрузки системы.
echo Automatic boot in progress... fsck -p
(На самом деле все немного сложнее, поскольку запуск fsck можно запретить командами в файле rc.conf – прим. переводчика.) Будем подразумевать что fsck не встретил проблем при проверке файловых систем. Затем rc смонтирует файловые системы.
# Mount everything except nfs filesystems. # Смонтировать все исключая nfs. mount -a -t nonfs
Перед тем, как запустится первый демон, ваши CMOS часы должны быть соответствующим образом отрегулированы, для того, что бы их могли понимать часы ядра.
adjkerntz -i
Содержимое некоторых подкаталогов каталога /var должно быть очищено от посторонних файлов, после чего загрузочные сообщения помещаются в файл dmesg.boot:
clean_var() { if [ ! -f /var/run/clean_var ]; then rm -rf /var/run/* find /var/spool/lock ! -type d -delete rm -rf /var/spool/uucp/.Temp/* # Keep a copy of the boot messages around dmesg >/var/run/dmesg.boot
Затем rc читает содержимое следующих файлов:
/etc/rc.sysctl /etc/rc.serial /etc/rc.pccard /etc/rc.network /etc/rc.network6
После этого rc сбрасывает настройки прав доступа терминала
# Whack the pty perms back into shape. chflags 0 /dev/tty[pqrsPQRS]* chmod 666 /dev/tty[pqrsPQRS]* chown root:wheel /dev/tty[pqrsPQRS]*
А затем он подчищает беспорядок и очищает каталог /tmp:
# Clean up left-over files # Удаление ненужных файлов
...
# Clearing /tmp at boot-time seems to have a long tradition. It doesn't # help in any way for long-living systems, and it might accidentally # clobber files you would rather like to have preserved after a crash # (if not using mfs /tmp anyway). # See also the example of another cleanup policy in /etc/periodic/daily. # Очистка каталога /tmp во время загрузки, кажется имеет давние традиции. # Она никогда не помогает в случае редко перегружаемых систем. При # перезагрузке из-за системного сбоя вы можете потерять нужные файлы, # оказавшиеся в каталоге /tmp.
...
# Remove X lock files, since they will prevent you from restarting X11 # after a system crash. # Удаление блокировочных файлов XWindow, поскольку они # могут помешать их перезапуску после аварийной перезагрузки
...
Теперь все подготовлено к запуску некоторых демонов первыми запускаются syslogd и named:
# Start system logging and name service. # Named needs to start before syslogd # if you don't have a /etc/resolv.conf. # Запуск службы журналлирования и сервера имен # Сервер имен должен быть запущен перед службой # журналлирования, если у вас нет файла resolv.conf
Затем стартуют inetd, cron, lpd, sendmail, sshd и usbd:
# Now start up miscellaneous daemons that don't belong anywhere else # Теперь запускаются разные демоны, которые нигде больше не указаны
После этого rc корректирует файл motd, а так же выполняет "uname -m" которая выдаст вам архитектуру вашего процессора
(Тут /etc/rc кончается.)
Поскольку мы достигли конца /etc/rc, работа сценария rc закончена. Подведем краткий итог тому, что здесь произошло: init вызывает сценарий rc который читает несколько конфигурационных файлов, для того что бы правильно смонтировать файловые системы и подготовить среду для старта системных демонов. Теперь ваша система загружена и работает, однако в данный момент еще не существует среды в которой пользователь будет «общаться» с операционной системой. С этого момента начинается второй этап работы процедуры init.
Теперь прочитывается конфигурационный файл /etc/ttys. Файл /etc/ttys содержит важную информацию о терминалах – какие из них (и каким образом – прим. переводчика) должны быть проинициализированы. В отличие от /etc/rc, этот файл может быть отредактирован суперпользователем, если в этом есть необходимость.
Для правильного понимания содержимого этого файла, мы должны уяснить, что в FreeBSD существует три типа терминалов. Название виртуального терминала начинается с последовательности "ttyv", за которой следует число или буква, это терминалы которые доступны пользователю непосредственно сидящему за компьютером с FreeBSD. По-умолчанию первый из них, "ttyv0", выполняет функции системной консоли. Последовательные, или «телефонные» терминалы называются с "ttyd" и заканчиваются числом. Эти терминалы предназначены для пользователей, которые получают доступ к вашей FreeBSD удаленно при помощи модема. Последним типом терминалов являются псевдотерминалы (сетевые терминалы), их название начинается на "ttyp", заканчиваясь числом или буквой. Такие терминалы используются для работы пользователей получающих доступ к FreeBSD по сети (например для работы telnet сессии – прим. переводчика).
Если мы посмотрим файл /etc/ttys: more /etc/ttys
то мы увидим, что он состоит из трех частей, по количеству типов терминалов. Каждая часть состоит из четырех столбцов, сведения о которых собраны в таблице:
| name | Название терминального устройства в системе |
| getty | Программа которую надо запустить на терминале, чаще всего это getty. Другие примеры: xdm, который запускает систему XWindow, и none, означающий, что на терминале не надо запускать никаких программ. |
| type | Для виртуальных терминалов, корректный тип cons25 (для русскоязычных пользователей – cons25r – прим. переводчика). Другие типы: для псевдотерминала это network, для портов, обслуживающих входящие модемные вызовы – dialup. Если предугадать тип терминала к которому хочет подключиться пользователь нельзя, в столбец типа пишут unknown. |
| status | Может иметь только два значения – on или off. Если значение "on", то init запускает программу указанную в столбце getty. Если добавлен параметр secure, то на этом терминале разрешен вход суперпользователя. Для его предотвращения используйте слово insecure. |
Если во время загрузки запуск команды fsck выявил неустранимые ошибки файловой системы, то init запустит операционную систему в однопользовательском режиме, для того что бы суперпользователь мог заняться решением проблемы. Если вы изменили настройку системной консоли со значения «по-умолчанию» secure на insecure, то перед переходом в однопользовательский режим, init потребует от вас ввода пароля суперпользователя. ttyv0 "/usr/libexec/getty Pc" cons25 on secure # Virtual terminals ttyv1 "/usr/libexec/getty Pc" cons25 on secure ttyv2 "/usr/libexec/getty Pc" cons25 on secure ttyv3 "/usr/libexec/getty Pc" cons25 on secure ttyv4 "/usr/libexec/getty Pc" cons25 on secure ttyv5 "/usr/libexec/getty Pc" cons25 on secure ttyv6 "/usr/libexec/getty Pc" cons25 on secure ttyv7 "/usr/libexec/getty Pc" cons25 on secure ttyv8 "/usr/X11R6/bin/xdm -nodaemon" xterm off secure
Заметьте – на моей FreeBSD имеется восемь виртуальных терминалов в добавок к консоли. Я имею доступ к каждому из них, по нажатию клавиши "Alt" и одной из функциональных клавиш. Например "Alt+F1" дает доступ к системной консоли, "Alt+F2" – к терминалу "ttyv1", "Alt+F3" – к "ttyv2", и т.д. Если я запущу сессию XWindow, она будет доступна по нажатию "Atl+F8". Если я поменяю параметр off на on для терминала ttyv8, то при старте системы вместо консоли я получу XWindow-сессию, хотя я по прежнему сохраню возможность переключения между терминалами по Alt комбинации (тут автор немного ошибся – из сессии XWindow в текстовый терминал можно перейти только по комбинации Ctrl+Alt+F<номер терминала> – прим. переводчика). Все терминалы на моей машины отмечены признаком "secure", поэтому на любом из них я сразу могу зайти в систему от имени суперпользователя. Какое количество виртуальных терминалов создано по-умолчанию на вашей машине зависит от версии FreeBSD. Если вы хотите создать себе несколько дополнительных виртуальных терминалов, посмотрите эту ссылку: http://www.freebsd.org/FAQ/x.html#VIRTUAL-CONSOLE.
Теперь переместимся ниже, в раздел терминалов обслуживающих входящие звонки на модемы (раздел dial-up терминалов). # Serial terminals # The 'dialup' keyword identifies dialin lines to login, fingerd etc. ttyd0 "/usr/libexec/getty std.9600" dialup off secure ttyd1 "/usr/libexec/getty std.9600" dialup off secure ttyd2 "/usr/libexec/getty std.9600" dialup off secure ttyd3 "/usr/libexec/getty std.9600" dialup off secure
Как мы видим, на моей машине четыре dial-up терминала, однако все они находятся в состоянии off. Если я захочу, что бы пользователи входили в мою систему используя модем, то мне придется хотя бы один из этих терминалов переключить в состояние on. Так же мне пришлось бы решать – должны ли эти пользователи иметь возможность входить в систему от имени суперпользователя, и если нет, то я должен буду изменить признак secure на insecure. Вы так же наверняка заметили, что в строках, описывающих dial-up терминалы столбец getty включает в себя число 9600. Это число определяет скорость передачи данных порта в 9600 бит/сек. Поскольку большинство современных модемов могут использовать гораздо более высокие скорости передачи данных, я, вероятно буду вынужден сменить это число на большее, например на 57600. И, наконец, я должен буду прочитать раздел FreeBSD Handbook, который детально описывает настройку сервиса приема входящих звонков (смотрите например по ссылке: http://www.freebsd.org/handbook/dialup.html).
Последний раздел файла /etc/ttys посвящен описанию сетевых или псевдо терминалов. В этом файле содержится описание очень большого их количества, 255, если быть точным. В диапазоне от: # Pseudo terminals ttyp0 none network
до: ttySv none network
Ни один из них по-умолчанию не активирован.
Даже если вы стали суперпользователем для того что бы отредактировать файл /etc/ttys, вы все равно не должны забывать послать процессу init сигнал HUP, для того что бы он воспринял внесенные изменения. Для того что бы сделать это, напишите: kill -1 1
где -1 это числовое обозначение сигнала HUP, а 1 – номер процесса init.
Теперь давайте выясним, что это за программа getty, которая присутствует в файле /etc/ttys. Описание взятое из страницы руководства (man 8 getty) дает нам полную картину: DESCRIPTION
The getty program is called by init(8) to open and initialize the tty line, read a login name, and invoke login(1).
ОПИСАНИЕ Программа getty вызывается процессом init для того что бы открыть и инициализировать терминальный канал, прочитать имя пользователя и вызвать программу login.
Таким образом init читает /etc/ttys и запускает программу getty на каждом терминале указанном в конфигурационном файле. Задачей getty является постоянный мониторинг терминала на наличие попыток войти в систему. Если кто-нибудь это делает, getty запускает программу login, для того что бы проверить имя пользователя и пароль (getty считывает имя пользователя, а пароль считывает login – прим. переводчика). Если проверка прошла успешно, то login запускает указанный в профиле пользователя интерпретатор команд и помещает пользователя в его домашний каталог. Как только пользователю становится доступен интерпретатор команд, он может взаимодействовать с операционной системой. Теперь только интерпретатор команд разбирает команды пользователя, а так же обеспечивает запуск необходимых программ.
Когда пользователь покидает свой интерпретатор команд, init немедленно запускает новую копию getty, которая продолжает отслеживать попытки входа в систему.
Попробуем связать воедино весь этот процесс, глядя на вывод команды ps в свежее загруженной, установленной по-умолчанию FreeBSD 4.1. Я использовал ключи -ax для того что бы включить в вывод системных демонов: ps -ax PID TT STAT TIME COMMAND 0 ?? DLs 0:00.01 (swapper) 1 ?? ILs 0:00.16 /sbin/init -- 2 ?? DL 0:00.02 (pagedaemon) 3 ?? DL 0:00.00 (vmdaemon) 4 ?? DL 0:00.02 (bufdaemon) 5 ?? DL 0:01.02 (syncer) 1056 ?? Is 0:00.00 adjkerntz -i 1187 ?? Ss 0:00.08 syslogd -s 1206 ?? Is 0:00.05 inetd -wW 1208 ?? Is 0:00.11 cron 1622 ?? Ss 0:00.02 sendmail: accepting connections on port 25 (sendmail) 1621 v0 Ss 0:00.12 -csh (csh) 1701 v0 R+ 0:00.00 ps -ax 1699 v1 Is+ 0:00.01 /usr/libexec/getty Pc ttyv1 1619 v2 Is+ 0:00.01 /usr/libexec/getty Pc ttyv2 1618 v3 Is+ 0:00.01 /usr/libexec/getty Pc ttyv3 1617 v4 Is+ 0:00.01 /usr/libexec/getty Pc ttyv4 1616 v5 Is+ 0:00.01 /usr/libexec/getty Pc ttyv5 1615 v6 Is+ 0:00.01 /usr/libexec/getty Pc ttyv6 1614 v7 Is+ 0:00.01 /usr/libexec/getty Pc ttyv7
Теперь вы должны узнать большинство этих процессов: swapper имеет PID=0, а init – PID=1. Процессы adjkerntz, syslogd, inetd, cron и sendmail были успешно запущены сценарием rc. Что бы выполнить команду ps, мне был необходим интерпретатор команд, в моем случае это был C-shell, запущенный на ttyv0. Процессы getty ожидают входа пользователей на виртуальных терминалах 1-7. На виртуальном терминале номер 8 getty не запущен, поскольку этот терминал отключен в файле /etc/ttys.
В трех частях этой статьи нам удалось достаточно глубоко забраться во внутренности FreeBSD. (Что бы разбудить интерес к собственным исследованиям – прим. переводчика).
Вниманию вебмастеров: использование данной статьи возможно только в соответствии
с правилами использования материалов сайта «Софтерра» (http://www.softerra.ru/site/rules/)
Источники
Загрузите, или просто изучите все о ядре Linux
в архивах Linux Kernel Archives.
Документация о ядре расположена в директории "Documentation", где установлены исходники ядра.
Узнайте больше о виртуальной файловой системе /proc из Linux Gazette.
Прочтите man sysctl(8) и sysctl.conf(8).
Много документации на сайте Linux Documentation Project.
Для разрешения проблем с оборудованием, прочтите "Linux hardware stability guide, Part 1" (developerWorks, March 2001) и "Linux hardware stability guide, Part 2" (developerWorks, July 2001).
"Understanding Linux configuration files" (developerWorks, December 2001) дает обзор файлов и параметров допуска системных приложений, демонов и т.д.
"Configuring and compiling the kernel" (developerWorks, May 2002) проведет вас шаг за шагом через основы компилирования ядра из исходников.
Источник - LinuxBegin.ru
http://linuxbegin.ru
Адрес этой статьи:
http://linuxshop.ru/linuxbegin/article338.html
Источники и ссылки
Э.Немет, Г.Снайдер, С.Сибасс, Т.Хейн. "UNIX: руководство системного администратора", пер. с англ. С.М.Тимачева, К., BHV, 1999 г., глава 10.
Michael S. Keller, "Take Command: cron: Job Scheduler", LinuxJournal, September 01, 1999
man cron(8), crontab(1), crontab(5), anacron(1), anacrontab(5), syslog(3), at(1), atrun(1), at.deny(5), at.allow(5), atd(8).
man sync(8), sync(2).
Историческая справка
В старых традиционных системах Unix-компьютер был закрыт в отдельной в комнате, а пользователи получали доступ к системе через терминалы в другой комнате. Терминалы были подключены к последовательным портам. Во время первого включения системы она печатала (до появления терминалов с ЭЛТ, действительно, печатала) некую идентификационную информацию, а затем приглашение "login:". Всякий, кто хотел воспользоваться компьютером, подходил к одному из этих терминалов, набирал свое регистрационное имя, затем свой пароль и после этого получал приглашение оболочки и становился "зарегистрированным".
Сегодня на виртуальных терминалах Linux вы видите то же самое, хотя это не ощущается, если только не думать об истории.
История стандарта FHS
Процесс создания стандарта на структуру каталогов файловой системы начался в августе 1993 года с попытки упорядочить структуру файлов и каталогов операционной системы Linux. Стандарт FSSTND, ориентированный только на систему Linux, был выпущен 14 февраля 1994 года. Последующие редакции были выпущены 9 октября 1994 и 28 марта 1995 года.
В начале 1995 года с участием сообщества разработчиков системы BSD была поставлена цель создания более общей версии FSSTND, предназначенной не только для Linux, но и для других UNIX-подобных операционных систем. В результате объединенных усилий разработка стандарта сосредоточилась на вопросах, которые являются общими для всех UNIX-подобных систем. В качестве признания расширения сферы охвата действия стандарта его название было изменено на Filesystem Hierarchy Standard или, для краткости, FHS.
Добровольцы, которые активно участвовали в создании стандарта, перечислены в конце настоящего документа. Этот стандарт представляет собой общую точку зрения перечисленных и других участников разработки.
Previous: Список рассылки FHS
Next: Чем мы руководствовались
Up: Оглавление
Translated by troff2html v1.5 on 29 March 2002 by Daniel Quinlan
Итак Что же делать, если "нужно что-то большее"?
Ну, первый круг проблем, на самом деле - не проблема :-).
Если не сочинять нереальные ситуации (например, одна группа только читает, вторая - только выполняет, третья - только пишет, четвертая - только пишет и выполняет и т.п.), то оказывается, что в реальных ситуациях может возникнуть необходимость в одной дополнительной группе (кроме владельца, обычной группы и "всех остальных").
Например, "все остальные" не должны иметь никакого доступа к файлу, но при этом должна быть группа, которым файл доступен на чтение и группа, которым файл доступен также для записи.
Другой разновидностью задачи может быть исполняемый файл, который целая группа может модифицировать (то есть иметь право на запись), другая группа может исполнять, но не изменять и, опять же, "все остальные" не должны иметь никаких прав на этот файл.
Итак это все?
Ну почти.
Это почти все, но я был бы невнимателен, еслибы не поговорил немного о буфере обмена.
'Windows'/'OS2' имеют 256 буферов обмена как и 'Amiga'. В 'X' есть тоже самое - плюс. Под 'X' существуют те же, статические, 256 буферов обмена плюс то что называется 'Primary Selection' (Основное выделение). Это текст, который выделен на данный момент. 'Secondary Selection' (Вторичное выделение) относиться к обычным 256 буферам. В общем, все что выделено на данный момент, может быть 'вставлено' нажатием средней клавиши мыши. Очень приятно.
К сожалению, вещи могут стать более запутанными и вы полностью во власти тулкита, относительно того как это будет работать. Я заметил, что под KDE2x что-то крадет фокус выделения. Я пытался выключать klipper, но это не дало результата. На практике, это делает скрипты 'clipmanip' бесполезными, т.к. фокус 'крадут' до того как вы сможете вставить обработанное содержимое буфера обмена.
Не бойтесь отважные души! Мы можем выиграть в этой игре. Если мы не может найти общее решение, мы должны просто немного доработать вещи, обходным путем. Нам не сможет помешать небольшое различие в формате буфера обмена. Исключая 'clipmanip -n' мы кажется потерпели поражение, но не стоит пока списывать нас со счетов...
Обратимся за помощью к нашему Верному Редактору. Я конечно осознаю, что предлагать конкретный это почти тоже что выбирать за вас ваше нижнее бельё, но все таки выслушайте меня.
Мы можем использовать теже идеи, но 'защитить их от атаки' десктопа, делая все внутри нашего редактора. Все что нам нужно это 'дружелюбный редактор'. Как говорят 'geeks' 'emacs' это круто, т.к. он написан на lisp и может быть расширен при помощи скриптов на lisp. Теперь, мы, кто врядли может претендовать на звание Geeks, можем использовать Glimmer от Chris Phelps.
Glimmer на самом деле не написан на python (это C++), но он настолько плотно интегрирован, что вряд ли кто либо заметит это. Я думаю проект Scintilla и wxwindows позволяют создать полностью написанное на python решение хоть сегодня. Я использовал оба из них и могу сказать, что они просто изумительны. Вы можете написать на скрипте, все что захотите. Все что вам нужно, это написать скрипт на python и положить его в '/home/yourname/.glimmer/scripts', и он будет добавлен в меню 'Scripts'. Основываясь на том, что было у меня в дистрибутиве, я предлагаю эквиваленты вышеописанных скриптов для glimmer здесь. Они все похожи сами на себя и им легко следовать. Я многое изучил с тех пор как написал их, но я мужественно, скрепя зубы, оставляю их в том виде, в котором они были в то время. (Я изучил python пару месяцев назад, python/wxwindows это самая большая радость, которая у меня была за годы написания скриптов).
Т.к. вы находитесь здесь уже долго, я дам вам еще одну вещь: baudline. Это приложение невероятно мощно, для всего, чего мы простые смертные не применяли-бы его, я практически не упоминал его. Baudline это Король свободно доступных аудио инструментов. Я послал свои благодарности автору, но я был немного обеспокоен на счет того, что он может не одобрить использование Baudline в моих руках: для ответа по телефону. Я был не прав. С того времени, Erik Olson, добавил непосредственную поддержку для rmd и mp3. Если вам нужно редактировать/анализировать звук, можете больше не искать.
Я надеюсь, что хотя бы вызвал у вас интерес к некоторым из этих утилит. Исключая WordNet, все они небольшого размера. Получите удовольствие !
Примечание
1 Если у Jerry Pournelle есть авторское право на это слово, извиняюсь прямо сейчас.
Итак Примеры изменения конфигурации XKB
Новый тип для клавиши Enter.
Добавляем новую "старую" раскладку клавиатуры.
"Вариации на тему" переключатели "рус/лат" (и еще раз - "рус").
Еще несколько "переключателей".
Иван Паскаль pascal@tsu.ru
IV Файловая система ext
Файловая система ext3 – это журналируемая версия Linux файловой системы ext2. Файловая система ext3 имеет одно значительно преимущество перед другими журналируемыми файловыми системами – она полностью совместима с файловой системой ext2. Это делает возможным использование всех существующих приложений разработанных для манипуляции и настройки файловой системы ext2.
Файловая система ext3 поддерживается ядрами Linux версии 2.4.16 и более поздними, и должна быть активизирована использованием диалога конфигурации файловых систем (Filesystems Configuration) при сборке ядра. В Linux дистрибутивы, такие как Red Hat 7.2 и SuSE 7.3 уже включена встроенная поддержка файловой системы ext3. Вы можете использовать файловую систему ext3 только в том случае, когда поддержка ext3 встроена в ваше ядро и у вас есть последние версии утилит «mount» и «e2fsprogs».
В большинстве случаев перевод файловых систем из одного формата в другой влечет за собой резервное копирование всех содержащихся данных, переформатирование разделов или логических томов, содержащих файловую систему, и затем восстановление всех данных на эту файловую систему. В связи с совместимостью файловых систем ext2 и ext3, все эти действия можно не проводить, и перевод может быть сделать с помощью одной команды (запущенной с полномочиями root):
# /sbin/tune2fs -j <имя-раздела >
Например, перевод файловой системы ext2 расположенной на разделе /dev/hda5 в файловую систему ext3 может быть осуществлен с помощью следующей комманды:
# /sbin/tune2fs -j /dev/hda5
Опция '-j' команды 'tune2fs' создает журнал ext3 на существующей ext2 файловой системе. После перевода файловой системы ext2 в ext3, вы так же должны внести изменения в записи файла /etc/fstab, для указания что теперь раздел является файловой системой 'ext3'. Так же вы можете использовать авто определение типа раздела (опция «auto»), но все же рекомендуется явно указывать тип файловой системы. Следующий пример файл /etc/fstab показывает изменения до и после перевода файловой системы для раздела /dev/hda5:
До:
/dev/hda5 /opt ext2 defaults 1 2
После:
/dev/hda5 /opt ext3 defaults 1 0
Последнее поле в /etc/fstab указывает этап в загрузке, во время которого целостность файловой системы должна быть проверена с помощью утилиты «fsck». При использовании файловой системы ext3, вы можете установить это значение в «0», как показано на предыдущем примере. Это означает что программа 'fsck' никогда не будет проверять целостность файловой системе, в связи с тем что целостность файловой системы гарантируется путем отката в журнале.
Перевод корневой файловой системы в ext3 требует особого подхода, и лучше всего его проводить в режиме одного пользователя (single user mode) после создания RAM диска поддерживающего файловую систему ext3.
Ivan Kanis, ivank@julivacomПеревод: Александр Саввин, savvin@mailru
v1.0, 2001-01-15
Вэтом документе описывается как с помощью GRUM установить Windows 98, Windows 2000, DOS и Linux.
Избранные горячие клавиши Linux и разумные команды
<Ctrl><Alt><F1>
Переключиться на первый текстовый терминал. Под Linux вы получаете несколько (6 - стандартное количество) одновременно открытых терминалов. Это - клавиатурная комбинация, которая значит: "нажмите вместе клавиши <ctrl> и <alt> и держите их. Потом нажмите <F1>. И после этого отпустите все клавиши."
<Ctrl><Alt><Fn> (n=1..6)
Переключение на текстовый терминал с номером n. (Nого же можно добиться использованием команды chvt n. "chvt" - значит "сменить виртуальный терминал (change virtual terminal)"). В текстовом терминале (не в X-терминале) вы можете так же использовать <Alt><Fn> (Клавиша <Ctrl> здесь не нужна).
tty
Даст вам имя того терминала, в котором вы напечатаете эту команду. Если же вы предпочитаете получить номер терминала вместо его имени, вы можете использовать fgconsole (="активная консоль(foreground console)").
<Ctrl><Alt><F7>
Переключиться на первый графический терминал (точнее, на седьмой терминал, где он обычно находится)
<Ctrl><Alt><Fn> (n=7..12)
Переключиться на графический терминал №n (если графический терминал выполняется в позиции n-1). По умолчанию, первый X-сервер выполняется на терминале под номером 7. По умолчанию, ничто не выполняется на терминалах с 8 по 12--Вы можете использовать их как X-терминалы.
<Tab>
(В текстовом или X-терминале) Автозавершение команд, если есть только одна возможность, иначе - показывает все существующие возможности. В более новых системах может потребоваться нажать <Tab><Tab>. ЭТО ВЕЛИКОЛЕПНАЯ КОМБИНАЦИЯ, она сохранит вам массу времени.
<ArrowUp>
(В текстовом или X-терминале) просмотр и редактирование истории команд. Нажмите <Enter> для выполнения команды из истории. Используйте <ArrowDown> для обратного просмотра.
<Shift><PgUp>
Просмотр истории вывода на терминал. Это работает даже в строке "login", так что вы сможете посмотреть сообщения загрузки. Величина/использование вашей видеопамяти определяет то, насколько глубоко вы можете просмотреть историю. <Shift><PgDown> Просмотр в обратном направлении.
<Ctrl><Alt><+>
(в X-windows) Сменить разрешение X-сервера на следующее (если вы установили X-сервер более чем на одно разрешение). Для нескольких разрешений для своей стандартной SVGA карты, я использую следующие строки в файле /etc/X11/XF86Config: (Первое разрешение устанавливается по умолчанию, наибольшее определяет размер "виртуального экрана"):
Modes "1024x768" "800x600" "640x480" "512x384" "480x300" "400x300" "1152x864"Z
Конечно же, сначала я сконфигурировал X-сервер, используя Xconfigurator, xf86config, или вручную - редактированием файла /etc/X11/XF86Config, и теперь он поддерживает такие значения разрешения (в основном - благодаря раскомментированию строк, относящихся к моей видеокарте, и определению частот синхронизации для поддержки моего монитора). XFdrake (конфигурационная утилита Mandrake) выполняется из графической оболочки. Так же смотрите команды xvidtune и xvidgen.
<Ctrl><Alt><->
(в X-windows) Выбрать предыдущее разрешение X-сервера.
<Ctrl><Alt><Esc>
(в X-windows, KDE) Закрыть окно, по которому будет произведен щелчок мыши (указатель мыши превращается в символ смерти). Обычно результат сравним с командой xkill, набранной в X-терминале. Полезно, когда программа в X-window не хочет закрываться сама (зависла, что ли?).
<Ctrl><Alt><BkSpc>
(in X-windows) Закрыть текущий сервер X-windows. Используйте, когда сервер X-windows не хочет закрываться по-хорошему.
<Ctrl><Alt><Del>
(в текстовом терминале) Закрыть систему и перезагрузиться. Это нормальная команда завершения работы системы из текстового режима. Руки прочь от кнопки "reset"!
<Ctrl>c
Убивает текущий процесс (работает в маленьких программах текстового режима).
<Ctrl>d
(Нажимается в начале пустой строки в режиме ввода команд) Выход из текущего терминала. См. так же следующие команды.
<Ctrl>d
Послать [Конец файла(End-Of-File)] текущему процессу. Не нажимайте дважды! (см. предыдущюю команду).
<Ctrl>s
Приостановить поток вывода терминала.
<Ctrl>q
Возобновить поток вывода терминала. Попробуйте, если ваш терминал мистическим образом перестал отвечать. См. предыдущую команду.
<Ctrl>z
Послать текущий процесс в фоновый режим.
exit
Выход из системы. Команда logout дает тот же эффект. (Если вы запустили вторую оболочку командной строки, например, используя bash, эта команда даст вам возможность покинуть ее, не выходя из первой. В этом случае, второе использование exit будет означать выход из системы.)
reset
Восстанавливает перекошенный терминал (терминал показывает забавные символы) в состояние по умолчанию. Используйте, если случайно посмотрели двоичный файл командой "cat". Вы можете не увидеть этой команды, но она все равно сработает.
<Средняя кнопка мыши>
Вставляет текст, выделенный в данный момент в другом месте. Это - обыкновенный способ выполнения операции "копировать-вставить (copy-paste)" в Linux. Такая же, как операция "копировать-вставить" в системе меню. (Это может не сработать в некоторых старых приложениях. Это работает в текстовом терминале, если вы разрешили сервис "gpm" в программе установки. Кроме того, это работает в большинстве диалоговых окон, и т.п. -- это действительно удобно!) Лучше всего выполнять эту операцию с 3-кнопочной мышью, приспособленной для Linux (Logitech или похожей), или используя "эмуляцию 3-х кнопочной мыши (3-mouse button emulation)". <СредняяКнопкаМыши> нормально эмулируется на 2-х кнопочной мыши одновременным нажатием обоих клавиш.
~
(знак "тильда") Моя домашняя директория (/home/мое_имя_пользователя). Например, команда cd ~/my_dir сменит мою рабочую директорию на субдиректорию "my_dir" в моей рабочей директории. Набрать "cd" без параметров - это то же самое, что набрать "cd ~". Я держу все мои файлы в моей домашней директории.
.
(точка) текущая директория. К примеру, ./my_program попробует выполнить программу "my_program" в вашей текущей директории.
..
(Две точки) Директория, родительская для текущей. Например, команда cd .. переместит мою текущую директорию на один уровень вверх.
Несколько дополнительных горячих клавиш для KDE или подобной графической среды (полезных, но необязательных)
<Alt><Tab> Прогулка по окнам. Для прогулки в обратную сторону: <Alt><Shift><Tab>
<Ctrl><Tab> Прогулка по рабочим столам. В обратном направлении: <Ctrl><Shift><Tab>
<Ctrl><Esc> Показать таблицу активных процессов. Позволяет убить запущенный процесс, или послать ему другой сигнал.
<Alt><F1> Вызвать K-menu ("Эквивалент меню "Пуск(Start)" MS Windows).
<Alt><F12> Эмулировать мышь "стрелками" клавиатуры.
<Alt><LeftMouseButton> Перенести окно. Обычно окно передвигают, перетаскивая его заголовок. С помощью этого сочетания клавиш можно передвигать окно за любую его часть.
<Alt><PrintScreen> Сделать снимок текущего окна в буфер обмена.
<Ctrl><Alt><PrintScreen> Сделать снимок текущего рабочего стола в буфер обмена.
<Ctrl><Alt><l> Запереть рабочий стол.
<Ctrl><Alt><d> Спрятать/показать рабочий стол (неплохо для того, чтобы убрать пасьянс, когда входит начальник).
<Alt><SysRq><Командная_клавиша>
(Необязательные.) Это - ключевые комбинации, относящиеся к уровню ядра Linux (низший уровнь). Это значит, что шансы использовать эти комбинации представляются в любое время. Эти комбинации используются в отладочных целях и только в случае необходимости, так что для начала можно попробовать другие, более безопасные средства. Клавиша <SysRq> так же известна, как <PrintScreen>. Комбинации могут быть разрешены/запрещены установкой соответствуюшего параметра ядра в "1" или "0", например : echo "1" > /proc/sys/kernel/sysrq
<Alt><SysRq><k> Убить все процессы (включая X), которые выполняются на текущей виртуальной консоли. Эта комбинация известна как "надежная клавиша доступа (secure access key, SAK)".
<Alt><SysRq><e> Послать сигнал TERM всем процессам, кроме init, что должно привести к их завершению.
<Alt><SysRq><i> Послать сигнал KILL всем исполняемым процессам, кроме init. Эта комбинация может преуспеть в уничтожении всех процессов более, чем предыдущая, но многие из процессов могут закончиться ненормально.
<Alt><SysRq><l> Послать сигнал KILL всем процессам, включая init. Система перестанет функционировать.
<Alt><SysRq><s> Выполнить аварийную синхронизацию (запись кэша на диск) для всех смонтированных файловых систем. Это может предотвратить потерю данных.
<Alt><SysRq><u> Перемонтировать все файловые системы в режиме "только для чтения". Эта комбинация действует так же, как предыдущая, с одной важной особенностью: если операция пройдет успешно, fsck не будет проверять все файловые системы при следующей перезагрузке системы.
<Alt><SysRq><r> Отключить режим непосредственной передачи данных (raw mode) с клавиатуры. Это может пригодиться, если Ваша сессия X-Windows зависнет. После ввода этой команды вам, возможно, удастся нажать <CTRL><ALT><DEL>.
<Alt><SysRq><b> Перезагрузиться немедленно, без синхронизации и демонтирования дисков. Это чревато ошибками файловой системы.
<Alt><SysRq><o> Выключает систему (Если сконфигурировано и поддерживается).
<Alt><SysRq><p> Выдает на консоль дамп содержимого текущих регистров и флагов.
<Alt><SysRq><t> Выдает на консоль список текущих задач и их информацию.
<Alt><SysRq><m> Выдает на консоль информацию о памяти.
<Alt>SysRq><цифра> Цифра от '0' до '9'. Устанавливает уровень протокола(log) консоли, указывающий, какие сообщения ядра будут печататься на вашей консоли. Например, '0' позволяет выводить только сообщения об опасности, такие как PANIC или OOPS.
<Alt><SysRq><h> Выводит справку. Кроме того, любая другая комбинация <Alt><SysRq><клавиша> выведет ту же справку.
Изменение атрибутов и цветов
(влияет только на те символы, которые будут выводиться после этой команды)
| Esc[nm | установить атрибуты |
| n = 0 | сброс всех атрибутов, цвет фона и символов устанавливается в "базовый" (смотри Esc=nF и Esc=nG ниже) |
| n = 1 | повышенная яркость |
| n = 4 | подчеркнутые символы (не все видеокарты это могут) |
| n = 5 | мигание |
| n = 7 | "реверс" (темные буквы на белом фоне) |
| n = 30+n1 | установить цвет фона n1 |
| n = 40+n1 | установить цвет символов n1 |
| Escn1;n2;...m | установить сразу несколько атрибутов |
| Esc[x или Esc[0x | сбросить все атрибуты и цвета, в том числе "базовые" |
| Esc[1;nx | n = цвет фона |
| Esc[2;nx | n = цвет символов |
| Esc[3;nx | n = (цвет фона)*16 + цвет символов |
| Esc[5;nx | n = цвет фона для "реверса" |
| Esc[6;nx | n = цвет символов для "реверса" |
| Esc[7;nx | n = (цвет фона)*16 + цвет символов, для "реверса" |
| Esc[=nF | n = цвет фона и "базовый" цвет фона |
| Esc[=nG | n = цвет символов и "базовый" цвет символов |
| Esc[=nH | n = цвет фона для "реверса" (то же, что и Esc[5;nx) |
| Esc[=nI | n = цвет символов для "реверса" (то же, что и Esc[6;nx) |
| Esc[=nA | n = цвет "бордюра" (по краям экрана). |
Изменение цветов
Во-первых, надо заметить, что syscons позволяет задавать две пары цветов (символ/фон) - для символов с "нормальными" атрибутами и для символов с атрибутом "реверс" (светлый фон, темный символ).
Для установки цветов "нормального" режима никаких ключей не нужно. Команда выглядит просто
vidcontrol "цвет символа" "цвет фона"
например
vidcontrol white black
Для цветов "реверсного" атрибута используется ключ -r (от слова reverse), например
vidcontrol -r black white
Вы можете также поменять цвет "бордюра" (полоски по краям экрана), с помощью ключа -b (border), например
vidcontrol -b gray
Список названий цветов можно посмотреть с помощью команды vidcontrol show
Однако, хочу заметить, что если вы используете какие-нибудь "коммандеры" (Deco, Midnight Commander и т.п.), то установки цветов, скорее всего работать не будут. Эти программы любят перекрашивать экран по своему усмотрению и при первой же "перерисовке" своих панелей "собьют" все ваши цвета.
Изменение набора модификаторов (modifiers)
Как я уже сказал, набор модификаторов распределен по трем переменным - base modifiers, latched modifiers и locked modifiers.
Соответственно действия для их изменения:
SetMods - меняет base modifiers, LatchMods - меняет latched modifiers, LockMods - меняет locked modifiers.
Основной аргумент у всех трех действий - modifiers (другое имя - mods). А его значение - название виртуального или реального модификатора. Если одно действие меняет сразу несколько модификаторов, их можно перечислить через знак "+". Например
SetMods(mods=Shift+Control);
Вместо названия модификатора можно указать специальное значение UseModMapMods (или просто ModMapMods). Это будет означать, что сами модификаторы надо взять из списка виртуальных модификаторов, связаных с этой клавишей (modmap и vmodmap).
Надо также заметить, что эти три действия отличаются не только тем, какую переменную они меняют. Они по разному работают в момент нажатия и в момент отпускания клавиши. Вспомните как отличается работа клавиш Shift и CapsLock. Первая должна действовать только пока ее удерживают в нажатом состоянии, то есть при ее нажатии модификатор Shift должен появиться, а при отпускании - автоматически исчезнуть. А вот CapsLock должна действовать долговременно - при первом нажатии ее модификатор должен стать активным и оставаться в таком состоянии даже после того как вы отпустите клавишу. А вот по повторному нажатию/отпусканию - убраться.
Так вот. Первые два действия предназначены для модификаторов типа Shift. То есть когда клавиша с таким действием нажимается, модификатор, указанный в аргументе добавляется в соответсвующую переменную (base или latched), а при отпускании клавиши то же действие выполняет обратную операцию - убирает модификатор.
А вот действие LockMods при первом исполнении только добавляет модификатор в locked modifiers, но не удаляет его при отпускании клавиши, а вот если модификатор уже установлен (то есть это уже повторное нажатие то же клавши), то при нажатии клавиши модификатор наоборот - убирается из locked modifiers.
Обратите внимание, что на самом деле совсем необязательно, чтобы вы использовали для модификатора Shift действие типа SetMods, а для модификатора Lock - LockMods. Вы можете "залокировать" Shift или наоборот - делать Lock
активным только на время удержания клавши. Но это уже зависит от того, что вы собственно хотите этим добится. :-)
Также поведение первых двух действий могут слегка изменяться с помощью двух флагов - clearLocks и latchToLock.
Поэтому полное описание всех деталей этих действий выглядит так
| SetMods | Добавляет модификаторы в base modifiers |
Убирает свои модификаторы из base modifiers если clearLocks=yes и между нажатием и отпусканием этой клавиши вы не нажимали другие клавиши, то эти же модификаторы вычищаются и из locked modifiers |
| LatchMods | Добавляет модификаторы в latched modifiers |
Убирает свои модификаторы из latched modifiers если clearLocks=yes и между нажатием и отпусканием этой клавиши вы не нажимали другие клавиши, то эти же модификаторы вычищаются и из locked modifiers если latchToLock=yes, то те же модификаторы запоминаются в locked modifiers |
| LockMods |
Добавляет модификаторы в base modifiers если этих модификаторов нет в locked modifiers, то добавляет их туда, в противном случае наоборот - убирает |
Убирает свои модификаторы из base modifiers locked modifiers не меняется. |
Изменение номер группы
Так же как и набор модификаторов, номер группы "размазан" по трем переменным - base group, latched group и locked group. Для получения реального или действующего номера группы значения этих переменных складываются. Если получившаяся сумма выходит за допустимые границы (количество групп реально существующих в раскладке клавиатуры) она
Изменение параметров работающего ядра
Linux имеет отличный способ изменять параметры ядра во время работы системы и без необходимости перезагрузки. Это делается при помощи виртуальной файловой системы /proc. Linux Gazette дает один из простейших и легчайших объяснений /proc, которые я когда-либо видел. (см. Источники.)
Вкратце, файловая система /proc дает вам возможность заглянуть в работающее ядро, что может быть полезно для мониторинга производительности, проверки системной информации, конфигурирования системы и изменения конфигурации. Эта файловая система называется виртуальной, потому что это в действительности не файловая система. Это карта, создаваемая ядром и присоединяемая к вашей обычной файловой системе, чтобы обеспечить доступ. Тот факт, что мы можем разными способами внести изменения в ядро во время работы системы дает системному администратору огромную мощь и гибкость при изменении параметров.
Но может быть слишком много власти это плохо? Иногда. Если вы собираетесь внести изменения в файловую систему /proc, вы должны быть уверены, что вы знаете, что вы делаете и какой эффект произведут на систему ваши действия. Это очень полезная техника, но одно неверное движение может вызвать неожиданные последствия. Если вы не уверены и новичок в таких делах, попрактикуйтесь на машине с меньшей важностью для ваших дел.
Изменение последовательностей, которые выдают клавиши fkey
Программа kbdkontrol позволяет изменит последовательность кодов, связанных с "функциональными клавишами". Для этого предназначен ключ -f (function key)
kbdcontrol -f "номер fkey'я" "строка"
Поскольку эта команда (точнее, этот ключ) "связывает" только одну конкретную "функциональную клавишу" с соответствующей последовательностью кодов, то для изменения нескольких fkey, можно несколько раз использовать ключ -f
в одной строке, например
kbdcontrol -f 1 ^[[M -f 2 ^[[N
Замечу, что обычно последовательности, "навешиваемые" на fkey'и начинаются с кода Esc (27). Если вы попытаетесь ввести этот код в командной строке, у вас, скорее всего, ничего не получится. Система попытается сразу обработать этот код, а не ждать пока вы введете все команду.
Поэтому выполнять такую "перезагрузку" кодов лучше всего из какого-нибудь командного файла. Только не забудьте, что вы должны вписать в команду именно код 27, а не два знака - "^" и "[" (а уж как он будет выглядеть, зависит от вашего редактора).
Существует также ключ (-F), с который "сбрасывает" все последовательности в их "стандартное" значение. То есть, устанавливает те последовательности, котрые были "зашиты" в syscons при сборке.
Изменение размера буфера терминала
По-моему, было бы логично, чтобы это изменение делала программа vidcontrol. Но так уж определил автор - размер буфера терминала
делается программой kbdcontrol с ключем -h (history buffer)
kbdcontrol -h "размер буфера в строках"
Заметьте, что если указать размер буфера меньше чем размер самого экрана, то просто не будет никакого буфера. То есть, все выводимые строчки будут нормально отображаться на экране, но запоминать syscons ничего не будет.
Извлечение значений переменных
[khim@localhost tmp]$ VAR1=1234567890 [khim@localhost tmp]$ VAR2=0987654321 [khim@localhost tmp]$ echo "$VAR1 $VAR2 XXX${VAR1}XXX ZZZ${VAR2}ZZZ" 1234567890 0987654321 XXX1234567890XXX ZZZ0987654321ZZZ [khim@localhost khim]$
$ X или ${X} — просто извлечь значение из переменной X (фигурные скобки необходимы тогда, когда после имени переменной следует буква или цифра).
[khim@localhost khim]$ ptr=VAR1 [khim@localhost khim]$ echo ${!ptr} 1234567890 [khim@localhost khim]$ ptr=VAR2 [khim@localhost khim]$ echo ${!ptr} 0987654321 [khim@localhost khim]$
${!X} — извлечь значение из переменной, имя которой хранится в переменной X. Вместе с массивами этого достаточно для создания и обработки весьма нетривиальных структур данных.
[khim@localhost tmp]$ echo "${#VAR1}" 10 [khim@localhost tmp]$ echo "${VAR1:${#VAR1}-3}" 890 [khim@localhost tmp]$
${#X} — получить длину строки X; эту операцию удобно комбинировать с извлечением подстроки.
[khim@localhost tmp]$ echo ${VAR4:?can not proceed without VAR4} ; echo Ok bash: VAR4: can not proceed without VAR4 [khim@localhost tmp]$
${X:?выражение} — извлечь значение переменной, а если она не определена, остановить выполнение скрипта.
[khim@localhost tmp]$ echo "${VAR1:-ABCDEF} ${VAR3:-ABCDEF}" 1234567890 ABCDEF [khim@localhost tmp]$ echo "${VAR1:-ABCDEF} ${VAR3:-FEDCBA}" 1234567890 FEDCBA [khim@localhost tmp]$
${X:-выражение} — условное извлечение: если переменная определена (как VAR1), используется ее значение, иначе — заданное альтернативное выражение (как в случае с VAR3).
[khim@localhost tmp]$ echo "${VAR1:=ABCDEF} ${VAR3:= ABCDEF}" 1234567890 ABCDEF [khim@localhost tmp]$ echo "${VAR1: =ABCDEF} ${VAR3:=FEDCBA}" 1234567890 ABCDEF [khim@localhost tmp]$
${X:=выражение} — то же, но альтернативное выражение становится на будущее значением переменной.
[khim@localhost tmp]$ echo "${VAR1:5} ${VAR2:5:3}" 67890 543 [khim@localhost tmp]$
${X:N1[:N2]} — извлечь из переменной X подстроку, начинающуюся с N1-го символа (и заканчивающуюся N2-м).
[khim@localhost tmp]$ echo "${VAR1#*[37]} ${VAR2#*[37]} ${VAR3#*[37]}" 4567890 654321 ABCDEF [khim@localhost tmp]$ echo "${VAR1##*[37]} ${VAR2##*[37]} ${VAR3##*[37]}" 890 21 ABCDEF [khim@localhost tmp]$ echo "${VAR1%[37]*} ${VAR2%[37]*} ${VAR3%[37]*}" 123456 0987654 ABCDEF [khim@localhost tmp]$ echo "${VAR1%%[37]*} ${VAR2%%[37]*} ${VAR3%%[37]*}" 12 098 ABCDEF [khim@localhost tmp]$
${X#шаблон}, ${X##шаблон}, S{X%шаблон}, S{X%%шаблон} — извлечь строку, удалив из нее часть, соответствующую шаблону. Шаблон строится по тем же правилам, что и для имен файлов, т. е. ‘*[37]’ — это любая последовательность символов, а затем либо ‘3’, либо ‘7’, а ‘[37]*’ — это ‘3’ или ‘7’, а затем любая последовательность символов. Операции ‘#’ и ‘%’ удаляют минимальную возможную подстроку, ‘##’ и ‘%%’ — максимальную, причем ‘#’ и ‘##’ — с начала строки, а ‘%’ и ‘%%’ — с конца.
[khim@localhost tmp]$ CDPATH=/bin [khim@localhost tmp]$ CDPATH=/newpath$ {CDPATH:+:$CDPATH} [khim@localhost tmp]$ echo ${CDPATH} /newpath:/bin [khim@localhost tmp]$ unset CDPATH [khim@localhost tmp]$ CDPATH=/newpath$ {CDPATH:+:$CDPATH} [khim@localhost tmp]$ echo ${CDPATH} /newpath [khim@localhost tmp]$
${X:+выражение} — операция, обратная условному извлечению. Может показаться мистической, но используется не так уж редко.
[khim@localhost tmp]$ echo "${VAR1/[123]/x} ${VAR2/ [123]/x} ${VAR3/[123]/x}" x234567890 0987654x21 ABCDEF [khim@localhost tmp]$ echo "${VAR1//[123]/x} ${VAR2// [123]/x} ${VAR3//[123]/x}" xxx4567890 0987654xxx ABCDEF [khim@localhost tmp]$
${X/шаблон/выражение}, ${X//шаблон/выражение} — извлечь строку, заменив в ней часть, соответствующую шаблону, заданным выражением (поиск с заменой). Операция ‘/’ выполняет замену однократно, а ‘//’ повторяет ее до победного конца.
Источник - LinuxBegin.ru
http://linuxbegin.ru/
Адрес этой статьи:
http://linuxshop.ru/linuxbegin/article200.html
Я составил справочник соответствия
Основным недостатком использования расширений имени файла является как раз то, что тип файла определяется по имени файла
Достаточно нелогично, что операция переименования влияет на атрибут, обозначающий тип содержимого - это провоцирует ошибки пользователей, вызванные опечатками при наборе на клавиатуре. Из-за такой ошибки файл может пропасть из списков, составляемых по типу файла, или, хуже того, появитьсмя в другом списке и вызвать проблемы в работе программ, полагающихся на расширение файла. Фактически раз переименование файла .koi.html
в .win.txt не переводит файл из кодировки KOI8-r в Win1251 и из HTML-формата в простой текст, это является нарушением целостности данных; такие вещи допустимы в экстремальных случаях (когда администратор вынужден "лезть под капот" и вручную исправлять сбой), но недопустимо предоставлять любой программе, а тем более любому юзеру возможность без труда менять расширение имени файла без соответствующего изменения содержимого! Часто одно и то же расширение используется для совершенно различных типов файлов. Примером может служить .doc, обозначающий как просто документацию, так и файлы несовместимых между собой версий MS-Word для DOS, Windows'3.x (версии до шестой) и Windows'9x/NT (начиная с седьмой, именуемые также по году выпуска).
В Unix запускаемые файлы имеют специальный атрибут. Вообще говоря, транслировать этот атрибут другим операционным системам, даже Unix'ам и даже другим версиям того же Unix'а (особенно если отличаются первые цифры версий) довольно опасно - Unix-совместимость гарантирована только на уровне исходного кода и требует перекомпиляции. Формат двоичных запускаемых файлов никогда не бывает текстовым#, поэтому его нельзя перепутать с со скриптами - интерпретируемыми программами. Чтобы скрипт интерпретировался именно нужным интерпретатором, в его начало помещаетя строка
#!/путь/shell [ключи]
которая определчяет тип скрипта (наиболее распространенные - sh, csh и прочие варианты командной оболочки, а также perl; особо одаренные, бывает, используют awk). Серьезный недостаток этого метода в том, что интерпретатор может находиться не в том месте, где его ожидал автор скрипта, или начинаются проблемы с версией интерпретатора, явно указанной в имени файла.
Acorn и Macintosh (Apple) используют специальное поле, в котором записывается в числовом виде тип файла. Чтобы разные авторы форматов файлов не вступали в противоречие друг с другом, используя одно и то же число для обозначения разных форматов, обе фирмы ведут учет используемых типов и если программист хочет, чтобы его программа беспроблемно использовалась широкими слоями юзеров, он должен зарегестрировать придуманный им тип данных, получив для него идентификатор. /* Аналогично Acorn распределяет системные вызовы SWI.*/
Macintosh имеет сструктуру типа ACL в NTFS, но хранит там не права доступа, а информацию о типе данных; Acorn использует два четырехбайтных поля, использовавшиеся в 8-битных машинах для информации об адресе загрузки и адресе запуска программы.
Сетевой протокол HTTP использует свой способ сообщить клиенту тип передаваемых данных (я сознательно говорю "тип данных", а не "тип файла" - передаваемые данные могут не содержаться в файле, а формироваться непосредственно по запросу). Способ называется MIME и используется во многих других местах, в частности, в электронной почте. Формат MIME довольно прост: в начале идет заголовок, состоящий из строк
имя_параметра: значение [атрибуты]
затем пустая строка и собственно данные. В HTTP обязательно (а для другие могут обойтись и без этого) должна присутствовать строка
Content-Type: тип/подтип
определяющая тип данных. Если тип - text, то в атрибутах часто передается кодировка, особенно если документ составлен на языке, использующем не латиницу, а собственный алфавит. Многие почтовые программы прямо жить не могут без
MIME-Version: 1.0 Особо мне хочется отметить вариант
Content-Type: multipart/подтип; boundary="строка" где подтип - alternative
(части содержат одно и то же в разных форматах)
или mixed (совокупность данных разного формата), а "строка" обычно что-нибудь типа "----=_NextPart_000_0037_01BE808E.D9AC1F40" - уникальная для данного документа последовательность символов, не встречающаяся нигде, кроме разделителей. Разделителями являются
--строка
а в конце всего идет
--строка-- Каждый из разделов сам оформлен в формате MIME, разве что не требует "MIME-Version:", так что может в свою очередь содержать multipart данные.
Остался непроясненным вопрос о том, откуда составитель MIME-документа узнает о том, к какому типу относятся включенные в документ данные.
Если документ составляет программа в ответ на запрос (например, CGI-скрипт), то тип данных должен быть известен программисту - должен же он знать, что посылает! Если данные берутся из файловой системы (как это делают Web-сервер или почтовая программа при составлении Attachment), то информация о типе данных обычно берется из файловой системы. Наиболее распространенными являются системы на базе Unix и Windows'9x/NT - они обычно ориентируются на расширение имени файла (например, Apache использует файл ".../conf/mime-types", в котором записано соответсвтие Content-Type: каждому известному ему расширению).
"Я здесь все мели знаю"
Большинство пользователей просто не представляют себе всех тех возможностей, которыми обладают команды и утилиты Unix, используют лишь малую их толику. Попробуем рассказать, что могут еще дать пользователям знакомые утилиты. (Автор сознательно не приводит полного "разбора" примеров — дабы у читателя появилось желание заглянуть в документацию.)
Сколько раз в день вы вызываете команду grep для поиска? Если вам действительно приходится делать в Unix что-то реальное, это случается по несколько раз в день. Большинство ограничивается самым тривиальным способом: ее использования — grep foo * – вывести все строки со словом foo. Однако у grep куда как больше возможностей, а для вышеуказанного поиска лучше подходит fgrep. Команда позволяет найти все строки с одним из нескольких слов, найти строки с повторами и т.п. Однако, для того чтобы воспользоваться этими возможностями, следует познакомиться с механизмом регулярных выражений. Примеры:
grep (one\|two) files
– найти строки, в которых встречаются цепочки one или two
grep (^[Bb]egin\|^[Ee]nd) files
– найти строки, начинающиеся с Begin, begin, End или end.
Если вас интересует наличие шестисимвольных "полиндромов" из букв, то есть комбинаций вида abccba, можно попробовать поискать их следующим образом:
grep (\([a-zA-z]\)\([a-zA-z]\)\ ([a-zA-Z]\)\3\2\1) files
Увы, это решение не совсем точное. Так, семи- или восьмибуквенная строка с 6 буквами в требуемом порядке будет считаться полиндромом, что, конечно, не так. Попробуйте подправить решение самостоятельно.
Рассмотрим другой вариант повтора. Предположим, нас интересуют строки, в которых некоторая цепочка (one или two) повторяется дважды:
grep (\(one\|two\).*\1) files
Заметим, что строки вида: oneѕtwo и twoѕone не сопоставляются.
Ядреная бомба
Первое, что следует сделать, это перекомпилировать ядро. Тут требуется знать точную конфигурацию вашего компьютера, очень желательно иметь свежие драйвера. Последнее требование возникает из-за чрезвычайно быстрого прогресса в графике и звуке. Драйвера для видеокарт nVIDIA можно найти на их сайте. Много различных драйверов для других продуктов пишется простыми энтузиастами, большая их коллекция расположена по адресу http://www.linux.org. Немного в стороне этого стоят "мягкие" модемы. Эти дешевые уроды построены на принципе, что все должен делать центральный процессор. Другим следствием их дешевизны является экономия на программистах, для некоторых моделей (особенно OEM) крайне сложно достать драйвера даже для Windows. Внешние модемы драйвера вообще не требуют. Часто бывает полезно скачать последнюю версию ядра с официального сайта http://www.kernel.org.
Скачивая новое ядро, всегда следует помнить о соглашении нумерации, которое используется разработчиками. Каждое ядро (кроме самых первых) имеет номер из 3 (трех) частей.
Первая часть - число (не цифра!) 2, оно означает, что ядро может быть модульным и не-i386-совместимым. Все современные ядра такие.
Второе число - это номер версии, четные числа обозначают стабильные и рабочие ядра, нечетные - это разрабатываемые версии. Нечетные версии не следует ставить для рабочих компьютеров.
Третье и последнее число - это номер релиза версии. Для четных (стабильных) версий оно связано с количеством встроенных драйверов. Для нечетных - со степенью их стабильности и работоспособности. Так, что не следует брать самое последнее ядро. Например версию 2.5.10 (последняя не момент написания) следует брать только для из-за поддержки USB 2.0, записи на NTFS, или обладателям процессоров AMD Hammer. Но простым ядром дело не всегда заканчивается, к ядру часто идут дополнительные патчи сторонних разработчиков с разнообразными драйверами устройств, неподдерживаемых стандартным ядром. Иногда имеет смысл установить и их. Но это уже для специалистов, новичкам с этим связываться не следует.
Когда скачаете новое ядро (предположим, версии 2.4.4), поместите его каталог linux-2.4.4 в каталог /usr/src, а затем ОБЯЗАТЕЛЬНО сделайте символический линк: ln -s /usr/src/linux-2.4.4 /usr/src/linux
Если вы не сделаете этого, то модули правильно не установятся. Зайдите в директорию /usr/src/linux и выполните одну из команд make config, make menuconfig или make xconfig. Команда make config морально устарела и полностью заменяема последними двумя. Первые две работают в текстовом режиме на обычной консоли, третья, более удобная, требует графической оболочки. Хотя результат работы всех трех одинаков.
Вам предложат набор всевозможных опций, которые можно включить в ядро. Я буду описывать их лишь в приложении к конкретным задачам, которые ставятся перед обычным компьютером на процессоре Intel или AMD. Обладателям других процессоров вряд ли требуются мои пояснения.
Самое главное, что следует помнить при выборе компонент ядра это то, что не все они приводят к работоспособности ядра на вашем компьютере. Часто они приводят к тому, что он после установки нового ядра просто не запустится. В большинстве пунктов имеется три варианта ответа Y, M, N. Если с Y и N все ясно, то M означает не "may be", а "module". Ядерный модуль это подгружаемая часть ядра, он запускается только в том случае, когда требуется его присутствие. Некоторые драйвера, например поставляемые производителем, являются модулями изначально и не могут быть вкомпилированны собственно в ядро. Другие, например драйвер корневого диска, не должны выбираться как модуль ни в коем случае.
Linux Navigator. Стр 3. Опции ядра

 |
Содержание: |  |
Linux Navigator. Консоль
Linux Navigator. Инсталляция
Linux Navigator. Опции ядра
Linux Navigator. Администрирование
Linux Navigator. Файловая система 1. Монтирование.
Linux Navigator. Файловая система 2.
Linux Navigator. Настройки сети.

Ядро
Ядреная бомба
Первое, что следует сделать, это перекомпилировать ядро. Тут требуется знать точную конфигурацию вашего компьютера, очень желательно иметь свежие драйвера. Последнее требование возникает из-за чрезвычайно быстрого прогресса в графике и звуке. Драйвера для видеокарт nVIDIA можно найти на их сайте. Много различных драйверов для других продуктов пишется простыми энтузиастами, большая их коллекция расположена по адресу http://www.linux.org. Немного в стороне этого стоят "мягкие" модемы. Эти дешевые уроды построены на принципе, что все должен делать центральный процессор. Другим следствием их дешевизны является экономия на программистах, для некоторых моделей (особенно OEM) крайне сложно достать драйвера даже для Windows. Внешние модемы драйвера вообще не требуют. Часто бывает полезно скачать последнюю версию ядра с официального сайта http://www.kernel.org.
Скачивая новое ядро, всегда следует помнить о соглашении нумерации, которое используется разработчиками. Каждое ядро (кроме самых первых) имеет номер из 3 (трех) частей.
Первая часть - число (не цифра!) 2, оно означает, что ядро может быть модульным и не-i386-совместимым. Все современные ядра такие.
Второе число - это номер версии, четные числа обозначают стабильные и рабочие ядра, нечетные - это разрабатываемые версии. Нечетные версии не следует ставить для рабочих компьютеров.
Третье и последнее число - это номер релиза версии. Для четных (стабильных) версий оно связано с количеством встроенных драйверов. Для нечетных - со степенью их стабильности и работоспособности. Так, что не следует брать самое последнее ядро. Например версию 2.5.10 (последняя не момент написания) следует брать только для из-за поддержки USB 2.0, записи на NTFS, или обладателям процессоров AMD Hammer. Но простым ядром дело не всегда заканчивается, к ядру часто идут дополнительные патчи сторонних разработчиков с разнообразными драйверами устройств, неподдерживаемых стандартным ядром. Иногда имеет смысл установить и их. Но это уже для специалистов, новичкам с этим связываться не следует.
Когда скачаете новое ядро (предположим, версии 2.4.4), поместите его каталог linux-2.4.4 в каталог /usr/src, а затем ОБЯЗАТЕЛЬНО сделайте символический линк:
ln -s /usr/src/linux-2.4.4 /usr/src/linux
Если вы не сделаете этого, то модули правильно не установятся. Зайдите в директорию /usr/src/linux и выполните одну из команд make config, make menuconfig или make xconfig. Команда make config морально устарела и полностью заменяема последними двумя. Первые две работают в текстовом режиме на обычной консоли, третья, более удобная, требует графической оболочки. Хотя результат работы всех трех одинаков.
Вам предложат набор всевозможных опций, которые можно включить в ядро. Я буду описывать их лишь в приложении к конкретным задачам, которые ставятся перед обычным компьютером на процессоре Intel или AMD. Обладателям других процессоров вряд ли требуются мои пояснения.
Самое главное, что следует помнить при выборе компонент ядра это то, что не все они приводят к работоспособности ядра на вашем компьютере. Часто они приводят к тому, что он после установки нового ядра просто не запустится. В большинстве пунктов имеется три варианта ответа Y, M, N. Если с Y и N все ясно, то M означает не "may be", а "module". Ядерный модуль это подгружаемая часть ядра, он запускается только в том случае, когда требуется его присутствие. Некоторые драйвера, например поставляемые производителем, являются модулями изначально и не могут быть вкомпилированны собственно в ядро. Другие, например драйвер корневого диска, не должны выбираться как модуль ни в коем случае.