Адресация
Адрес, определяемый протоколом IP (Internetwork Protocol), состоит из четырех байтов, записываемых традиционно в десятичной системе счисления и разделяемых точкой. Адрес сетевого интерфейса eth0 из примера – 192.168.102.125. Второй сетевой интерфейс из примера, lo, – так называемая заглушка (loopback), которая используется для организации сетевых взаимодействий компьютера с самим собой: любой посланный в заглушку пакет немедленно обрабатывается как принятый оттуда. Заглушка обычно имеет адрес 127.0.0.1.
Отдельная среда передачи данных (локальная сеть) также имеет собственный адрес. Если представить IP-адрес в виде линейки из 32 битов, она строго разделяется на две части: столько-то битов слева отводится под адрес сети, а оставшиеся – под адрес абонента в этой сети. Для того чтобы определить размер адреса сети, используется сетевая маска – линейка из 32 битов, в которой на месте адреса сети стоят единицы, а на месте адреса компьютера – нули. При наложении маски на IP-адрес все единицы в нем, которым соответствуют нули в маске, превращаются в нули2). Таким образом вычисляется IP-адрес сети. В примере сетевая маска интерфейса eth0 равна 255.255.255.0, т. е. 24 единицы и 8 нулей. Тогда IP-адрес сети будет равен 192.168.102.0. Мефодий заметил, что если сетевая маска выровнена по границе байта, производить двоичные операции вообще не надо: так, в примере можно было просто сказать, что адрес сети занимает три байта, а адрес абонента – оставшийся один.
Заметим, что адрес сети может содержать значащие нули: например, в адресе 10.0.0.1 при сетевой маске 255.255.0.0 адрес сети занимает два байта, из которых второй – полностью нулевой. Чтобы не гадать, какие нули – значащие, а какие – отрезаны маской, к адресу сети принято приписывать уточнение вида /количество_единиц_в_маске. В приведенном случае адрес сети выглядел бы так: 10.0.0.0/16, а в предыдущем – 192.168.102.0/24.
IP-адрес, составленный из адреса сети, за которым следуют все единицы (в примере – 192.168.102.255), называется широковещательный адрес: любой принадлежащий сети 192.168.102.0 компьютер, получивший IP-пакет с адресом получателя 192.168.102.255, должен обработать его, как если бы в поле "получатель" стоял его собственный IP-адрес.
Когда компьютер с некоторым IP-адресом решает отправить пакет другому компьютеру, он выясняет, принадлежит ли адресат той же локальной сети, что и отправитель (т. е. подключены ли они к одной среде передачи данных). Делается это так: на IP-адрес получателя накладывается сетевая маска, и таким образом вычисляется адрес сети, которой принадлежит получатель. Если этот адрес совпадает с адресом сети отправителя, значит, оба находятся в одной локальной сети. Это, в свою очередь, означает, что аппаратный адрес (MAC) получателя должен быть отправителю известен.
MAC-адреса компьютеров локальной сети хранятся в специальной таблице ядра, называемой "таблица ARP". Просмотреть содержимое этой таблицы можно с помощью команды arp -a:
Пример 14.2. Просмотр таблицы ARP (html, txt)
Если говорить более точно, ARP-таблица отражает соответствие между IP- и MAC-адресами. Таблица эта динамическая: устаревшие соответствия из нее удаляются, так как компьютеру может быть назначен другой IP-адрес, интерфейс можно отключить от сети, заменить и т. д. Если вновь понадобится связаться с компьютером, чей MAC-адрес устарел, соответствие IP и MAC придется устанавливать по новой. В примере была использована команда ping, посылающая на указанный IP-адрес пакеты служебного протокола ICMP, на который адресат обязан ответить. Если ответа нет, значит, связь по каким-то причинам невозможна.
Устанавливать соответствие между адресами сетевого и интерфейсного уровня – дело протокола ARP (Address Resolution Protocol, "протокол преобразования адресов"). В случае преобразования IP в MAC он работает так: отправляется широковещательный Ethernet-фрейм типа "ARP-запрос", внутри которого – IP-адрес, что означает "Эй! У кого такой IP?". Каждый работающий компьютер обрабатывает этот фрейм и тот, чей IP-адрес совпадает с запрошенным, возвращает отправителю пустой фрейм типа "ARP-ответ", в поле "отправитель" которого указан искомый MAC-адрес. Это означает: "У меня. А что?". Тут ARP-таблица заполняется и первый компьютер готов к инкапсуляции IP-пакета.
Аппаратный и интерфейсный уровни
Итак, на аппаратном уровне возможна какая угодно среда передачи данных – с точки зрения Linux, сеть начинается в месте подключения к этой среде, то есть на сетевом интерфейсе. Список сетевых интерфейсов и их настроек в системе можно посмотреть с помощью команды ifconfig (от interface configuration):
Пример 14.1. Запуск ifconfig (html, txt)
Утилитой ifconfig пользуется, в основном, сама система или администратор; некоторые данные ifconfig получает, обращаясь с системным вызовом ioctl() к открытому сетевому сокету, а некоторые считывает из /proc. Название сетевого интерфейса состоит из его типа и порядкового номера (каким по счету его распознало ядро). Все сетевые интерфейсы Ethernet в Linux называются ethномер, начиная с eth0. Параметр MTU (Maximum Transfer Unit) определяет наибольший размер фрейма.
Большинство других параметров относятся к сетевому уровню, но как минимум еще один – HWaddr – относится к уровню интерфейсному.
Сетевой интерфейс. Точка взаимодействия утилит Linux с реализацией TCP/IP в ядре системы. Как правило, имеет уникальный сетевой адрес. Интерфейсу может соответствовать некоторое сетевое оборудование (например, карта Ethernet), в этом случае определен также и его интерфейсный адрес.
HWaddr (от HardWare address, аппаратный адрес) – это уникальный внутри среды передачи данных идентификатор сетевого устройства. В Ethernet аппаратный адрес называется MAC-address (от Media Access Control, управление доступом к среде), он состоит из шести байтов, которые принято записывать в шестнадцатиричной системе исчисления и разделять двоеточиями. Каждая Ethernet-карта имеет собственный уникальный MAC-address (в примере – 00:0C:29:56:C1:36), поэтому его легко использовать для определения отправителя и получателя в рамках одной Ethernet-среды. Если идентификатор получателя неизвестен, используется аппаратный широковещательный адрес, FF:FF:FF:FF:FF:FF. Сетевая карта, получив широковещательный фрейм или фрейм, MAC-адрес получателя в котором совпадает с ее MAC-адресом, обязана отправить его на обработку системе.
Термин "Media Access Control" имеет отношение к алгоритму, с помощью которого решается задача очередности передачи. Алгоритм базируется на трех принципах:
Прослушивание среды. Каждое устройство умеет определять, идет ли в данное время передача данных по среде. Если среда свободна, устройство имеет право само передавать данные.Обнаружение коллизий. Если решение о начале передачи данных одновременно приняли несколько устройств, в среде возникнет коллизия, и распознать, где чьи были данные, становится невозможно. Зато устройства всегда замечают произошедшую коллизию, и передают данные повторно.Случайное время ожидания перед повтором. Если бы после коллизии все устройства начали одновременно повторять передачу данных, случилась бы новая коллизия. Поэтому каждое устройство выжидает некоторое случайное время, и только после этого повторяет передачу. Если повторная коллизия все-таки возникает, устройство ждет вдвое дольше1). так происходит до тех пор, пока не будет превышено допустимое время ожидания, после чего системе сообщается об ошибке.
Приведенный алгоритм имеет два недостатка. Во-первых, уже на интерфейсном уровне время передачи одного пакета может быть любым, так как неопределенное промедление с передачей предусмотрено протоколом. Во-вторых, сеть Ethernet считается хорошо загруженной, если на протяжении некоторого промежутка времени в среднем треть этого времени было потрачена на передачу данных, а две трети времени среда была свободна. Сеть Ethernet, нагруженная наполовину, работает очень медленно и с большим числом коллизий, а сеть, нагруженная на две трети, считается неработающей. Это – плата за отсутствие синхронизации работы всех устройств в сети.
Клиент-серверная модель
С точки зрения прикладного уровня, порт – это идентификатор сервиса, предоставляемого системой. В самом деле, практически любой акт передачи данных выглядит, как если бы некий клиент, которому эти данные нужны, запрашивал их у сервера, который может их предоставить1). Отношения между программами, которые связываются по сети друг с другом, почти всегда асимметричны: одной что-то надо, у другой это что-то есть. При установлении соединения и приложение (программа-клиент), и служба (программа-сервер) используют механизм сокетов, описанный в лекции 11, однако ведут себя по-разному.
Служба, запускаясь на сервере, создает сетевой сокет и прикрепляет его к определенному порту сервера с помощью системного вызова bind(). Затем она регистрируется в качестве обработчика запросов (listener), приходящих на этот порт. Служба ждет запросов, и когда они поступают, предпринимает какие-нибудь действия, например, считывает пришедшие данные и анализирует их в соответствии со своим протоколом, отсылает какие-то данные абоненту, пославшему запрос и т. п.
Приложение, запускаясь на клиенте, также создает сокет и присоединяется с его помощью к тому же порту на сервере, где запущена служба, используя системный вызов connect(). Затем оно, как и служба, посылает и получает данные. Разницы между обменом данными по сетевому сокету и по сокету в файловой системе нет. Очередность обмена данными определяется прикладным протоколом.
Как приложение узнает, к какому именно порту необходимо подключиться? За большинством прикладных протоколов закреплен постоянный номер порта. Постоянные номера портов и названия соответствующих протоколов хранятся в файле /etc/services:
Пример 14.6. Постоянные номера портов для некоторых протоколов (html, txt)
Этот файл – не догма, а руководство к действию: каждый может организовать, допустим, сервис HTTP по 25-му порту. Только как об этом узнают другие клиенты и что подумают почтовые программы, ожидая по этому порту встретить сервис SMTP (пересылка почты)? Вывести список установленных соединений, а также служб-обработчиков можно командой netstat:
[root@localhost root]# netstat - anA inet Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 192.168.102.125:22 192.168.102.1:33208 ESTABLISHED udp 0 0 0.0.0.0:11 0.0.0.0:*
Пример 14.7. Просмотр установленных соединений и служб (html, txt)
Здесь видно, что на компьютере зарегистрировано два TCP-обработчика (на портах 111 и 22), один UDP-обработчик по 11-му порту (понятие Listener, то есть обработчик соединения для UDP не имеет смысла), а также установлено одно соединение с компьютера 192.168.102.1, исходящий порт 33208, к 22-му порту (это порт службы Secure Shell, предоставляющей удаленный терминальный доступ... видимо, Гуревич работает?). В более сложных случаях, когда номер порта заранее неизвестен, а известно только название и версия сервиса, используется служба portmap, которая раздает незанятые порты службам и сообщает приложениям, к какому из них надо обратиться. Порт 111 соответствует именно этой службе.
Маршрутизация
Более сложный вопрос встает, если IP-адрес компьютера-адресата не входит в локальную сеть компьютера-отправителя. Ведь и в этом случае пакет необходимо отослать какому-то абоненту локальной сети, с тем, чтобы тот перенаправил его дальше. Этот абонент, маршрутизатор, подключен к нескольким сетям, и ему вменяется в обязанность пересылать пакеты между ними по определенным правилам. В самом простом случае таких сетей две: "внутренняя", к которой подключены компьютеры, и "внешняя", соединяющая маршрутизатор со всей глобальной сетью. Таблицу, управляющую маршрутизацией пакетов, можно просмотреть с помощью команды netstat -r или route (обе команды имеют ключ "-n", заставляющий их использовать в выдаче IP-адреса, а не имена компьютеров):
[root@localhost root]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.102.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo 0.0.0.0 192.168.102.1 0.0.0.0 UG 0 0 0 eth0
Пример 14.3. Простая таблица маршрутизации (html, txt)
На машине Мефодия в таблице маршрутизации всего три записи: одна – про сеть 192.168.102.0/24, доступную по интерфейсу eth0, другая – про сеть 127.0.0.0/8, доступную через заглушку, и последняя – про сеть 0.0.0.0/0, доступную через маршрутизатор (gateway) с адресом 192.168.102.1. Сеть 0.0.0.0/0 – это и есть "весь Internet", потому что ей принадлежат любые IP-адреса (ни одного бита на сетевую маску), такая запись в таблице называется "маршрут по умолчанию". Если маршрут не задан, попытка связаться с удаленным компьютером может завершиться с ошибкой "No route to host": система не сможет определить, кому пересылать пакет.
На маршрутизаторе таблица выглядит сложнее:
[root@fuji root]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 83.237.29.1 0.0.0.0 255.255.255.255 UH 0 0 0 ppp0 192.168.102.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1 10.13.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo 0.0.0.0 83.237.29.1 0.0.0.0 UG 0 0 0 ppp0 [root@fuji root]# ifconfig ppp0 ppp0 Link encap:Point-to-Point Protocol inet addr:83.237.29.51 P-t-P:83.237.29.1 Mask:255.255.255.255 UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1492 Metric:1 RX packets:17104 errors:0 dropped:0 overruns:0 frame:0 TX packets:23839 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:3 RX bytes:5879278 (5.6 Mb) TX bytes:1750644 (1.6 Mb)
Пример 14.4. Сложная таблица маршрутизации (html, txt)
Начать с того, что вдобавок к сетевым интерфейсом eth0 и eth1 тут наличествует интерфейс типа "точка-точка" – ppp0. Это виртуальный интерфейс: он не соответствует никакому сетевому устройству, а организуется по инициативе демона pppd, работающего в соответствии с протоколом PPP (Point to Point Protocol). PPP-соединение позволяет организовать "сеть", состоящую всего из двух абонентов, связанных любой средой передачи данных: двумя модемами и телефоном, тремя проводами, Ethernet и т. п.1)
Получив IP-пакет, система начинает "примерять" его поочередно ко всем записям таблицы маршрутизации, отсортированным в порядке убывания размера сетевой маски (в том же порядке выдает их команда route). Если сеть адресата совпадает с сетью из таблицы, пакет нужно пересылать по адресу, указанному в поле "Gateway". Этот адрес используется вместо поля адресата, и поиск возобновляется с начала таблицы. Если поле "Gateway" – нулевое, значит, речь идет об абоненте локальной сети, и пакет надо передать на уровень ниже (eth при этом может обновить ARP-таблицу, ppp – действовать как-то еще). Если ни одна сеть не подходит, выдается сообщение об ошибке. В примере все пакеты, не предназначенные сетям 192.168.102.0/24, 10.13.0.0/15 и 127.0.0.0/8, отправляются на маршрутизатор по умолчанию с адресом 83.237.29.1. Первая же запись рассказывает, как добраться до этого маршрутизатора (точнее, до сети 83.237.29.1/32, что эквивалентно единственному абоненту 83.237.29.1).
Относительно IP-адресов на маршрутизаторе Гуревич как-то заметил, что только один из них – 83.237.29.1 – "настоящий". Он имел в виду стандарт RFC1918, описывающий, какие диапазоны IP-адресов можно использовать в любой внутренней сети. Задача системного администратора – сделать так, чтобы при работе с сетью Internet ни в одном пакете не стояло такого внутреннего адреса отправителя: например, подменять внутренние адреса на единственный внешний ("настоящий"). Задача эта решается с помощью межсетевого экрана (firewall), который в Linux называется iptables, но когда Мефодий попросил Гуревича рассказать поподробнее, тот только рукой махнул: для этого надо хорошо знать TCP/IP.
Обслуживание прикладного уровня в Linux
Самый простой способ проверить, предоставляет ли некий сервер услуги по некоему TCP-порту – это подключиться к нему. Если под рукой нет приложения, работающего по соответствующему протоколу, не беда: подойдет утилита telnet. В качестве первого параметра следует указать адрес компьютера, к которому нужно подключиться, а в качестве второго (необязательного) – номер порта. Когда-то эта утилита использовалась в качестве клиента к терминальной службе, однако от нее пришлось отказаться: пароль пользователя передавался по сети незашифрованным. Но в качестве клиента других служб, многие из которых используют текстовые протоколы, telnet используется и поныне. Если даже протокол не текстовый, можно выйти в командный режим telnet, нажав "^[", и подать команду close, которая закроет соединение:
[root@localhost root]# telnet 192.168.102.1 112 Trying 192.168.102.1... telnet: connect to address 192.168.102.1: Connection refused [root@localhost root]# telnet 192.168.102.1 111 Trying 192.168.102.1... Connected to 192.168.102.1. Escape character is '^]'. ^[ telnet> close Connection closed.
Пример 14.8. Использование telnet (html, txt)
В сценариях вместо интерактивной утилиты telnet стоит использовать netcat, которая работает как cat в указанный сокет или из него. Как уже говорилось, интерпретацией прикладных протоколов занимаются разнообразные программы. Прикладной протокол можно представить как обмен сообщениями, часто текстовыми, между клиентом и сервером. Было бы естественно оформлять такие программы в виде фильтров, чтобы пользоваться простейшими функциями ввода-вывода. Однако механизм сокетов предусматривает асинхронную передачу данных, для чего используются другие функции. Программа, желающая обслуживать сетевые соединения по определенному порту, должна удовлетворять четырем требованиям:
Быть демоном, то есть постоянно находиться в памяти;Создавать сокет, прикреплять его к порту;Регистрироваться как обработчик по этому сокету и принимать соединения (возможно, придется обрабатывать несколько соединений одновременно);Анализировать прикладной протокол и действовать по результатам анализа.
Нетрудно заметить, что первые три свойства – общие для большинства сервисов. В Linux есть метадемон inetd, который берет на себя всю общую сетевую часть работы, а программам предоставляет разбираться в прикладном протоколе. Организовать свой сетевой сервис с помощью inetd становится очень просто: пользователь программирует фильтр, задача которого – обмениваться командами прикладного протокола с помощью стандартного ввода и стандартного вывода. Этот фильтр регистрируется в настройках inetd с указанием порта, с которого будут приниматься запросы. После чего сам inted становится обработчиком запросов по всем указанным портам, сам открывает соединение, запуская соответствующий фильтр, а данные из сокета пересылает туда и обратно по двум
каналам. При этом фильтр-обработчик даже не должен быть демоном: это обычная программа, которая завершается, когда это предусмотрено прикладным протоколом, или когда закрывается входной поток.
Мефодий минут за пять написал службу, которая в ответ на подключение передает календарь на текущий месяц. В его системе используется модернизированная версия inetd – xinetd, обученная чтению конфигурационных файлов по схеме ".d":
[root@localhost root]# grep quake /etc/services quake 26000/tcp quake 26000/udp [root@localhost root]# cat /etc/xinetd.d/calendar service quake { socket_type = stream protocol = tcp wait = no user = nobody server = /usr/bin/cal disable = no }
Пример 14.9. Настройка cal в качестве сетевой службы (html, txt)
Вместо номера порта можно использовать название протокола из /etc/services. Мефодий воспользовался портом 26000 (чем мог создать некоторые трудности любителям одной компьютерной игры). Осталось только перезагрузить xinetd, чтобы он нашел новый конфигурационный файл, и подключиться к порту 26000:
[root@localhost root]# service xinetd restart Stopping xinetd service: [ DONE ] Starting xinetd service: [ DONE ] [root@localhost root]# telnet localhost quake Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. December 2004 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
Пример 14.10. Подключение к самодельной службе "календарь" (html, txt)
Прикладной уровень
Как бы ни был надежен протокол TCP, он не имеет никакого понятия о том, что же, собственно, за данные с его помощью передаются. Да и не должен: принцип разделения уровней не позволяет заглядывать "внутрь" передаваемого пакета, и способов наверняка распознать используемый в нем прикладной протокол нет. Прикладной уровень, в отличие от транспортного, предусматривает сколько угодно протоколов передачи данных. Интерпретация данных, в конце концов, дело уже не ядра, а какой-нибудь программы ("приложения", как правило, демона). Для того чтобы можно было предположить, какой протокол используется при передаче данных, а также для того, чтобы система могла передать эти данные соответствующей программе, еще на транспортном уровне было введено понятие порта.
Limited output. Warning: cannot open
| methody@localhost:~ $ ifconfig -bash: ifconfig: command not found methody@localhost:~ $ /sbin/ifconfig Warning: cannot open /proc/net/dev (Permission denied). Limited output. Warning: cannot open /proc/net/dev (Permission denied). Limited output. eth0 Link encap:Ethernet HWaddr 00:0C:29:56:C1:36 inet addr:192.168.102.125 Bcast:192.168.102.255 Mask:255.255.255.0 UP BROADCAST NOTRAILERS RUNNING MULTICAST MTU:1500 Metric:1 Warning: cannot open /proc/net/dev (Permission denied). Limited output. lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:16436 Metric:1 |
| Пример 14.1. Запуск ifconfig |
| Закрыть окно |
| [root@localhost root]# arp -a fuji.nipponman.ru (192.168.102.1) at 00:50:56:C0:00:01 [ether] on eth0 edoh.nipponman.ru (192.168.102.7) at 00:50:56:C3:11:a2 [ether] on eth0 [root@localhost root]# sleep 60 [root@localhost root]# arp -a [root@localhost root]# ping -c1 192.168.102.1 PING 192.168.102.1 (192.168.102.1) 56(84) bytes of data. 64 bytes from 192.168.102.1: icmp_seq=1 ttl=64 time=0.217 ms --- 192.168.102.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.217/0.217/0.217/0.000 ms [root@localhost root]# arp -a fuji.nipponman.ru (192.168.102.1) at 00:50:56:C0:00:01 [ether] on eth0 |
| Пример 14.2. Просмотр таблицы ARP |
| Закрыть окно |
| [root@localhost root]# route - n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.102.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo 0.0.0.0 192.168.102.1 0.0.0.0 UG 0 0 0 eth0 |
| Пример 14.3. Простая таблица маршрутизации |
| Закрыть окно |
| [root@fuji root]# route - n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 83.237.29.1 0.0.0.0 255.255.255.255 UH 0 0 0 ppp0 192.168.102.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1 10.13.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo 0.0.0.0 83.237.29.1 0.0.0.0 UG 0 0 0 ppp0 [root@fuji root]# ifconfig ppp0 ppp0 Link encap:Point-to-Point Protocol inet addr:83.237.29.51 P-t-P:83.237.29.1 Mask:255.255.255.255 UP POINTOPOINT RUNNING NOARP MULTICAST MTU:1492 Metric:1 RX packets:17104 errors:0 dropped:0 overruns:0 frame:0 TX packets:23839 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:3 RX bytes:5879278 (5.6 Mb) TX bytes:1750644 (1.6 Mb) |
| Пример 14.4. Сложная таблица маршрутизации |
| Закрыть окно |
| [root@localhost root]# traceroute www.ru -n traceroute to www.ru (194.87.0.50), 30 hops max, 38 byte packets 1 192.168.102.1 0.223 ms 0.089 ms 0.105 ms 2 83.237.29.1 25.599 ms 21.390 ms 21.812 ms 3 195.34.53.53 24.111 ms 21.213 ms 25.778 ms 4 195.34.53.53 23.614 ms 33.172 ms 22.238 ms 5 195.34.53.10 43.552 ms 48.731 ms 44.402 ms 6 195.34.53.81 26.805 ms 21.307 ms 22.138 ms 7 213.248.67.93 41.737 ms 41.565 ms 42.265 ms 8 213.248.66.9 50.239 ms 47.081 ms 64.781 ms 9 213.248.65.42 99.002 ms 81.968 ms 62.771 ms 10 213.248.78.170 62.768 ms 63.751 ms 78.959 ms 11 194.87.0.66 101.865 ms 88.289 ms 66.340 ms 12 194.87.0.50 70.881 ms 67.340 ms 63.791 ms |
| Пример 14.5. Определения маршрута пакета |
| Закрыть окно |
| [root@localhost root]# wc /etc/services 553 2794 19869 /etc/services [root@localhost root]# egrep "^(ftp|http|smtp|ssh).*tcp" /etc/services ftp 21/tcp # File Transfer [Control] ssh 22/tcp # SSH Remote Login Protocol smtp 25/tcp mail # Simple Mail Transfer Protocol http 80/tcp www www-http # World Wide Web HTTP |
| Пример 14.6. Постоянные номера портов для некоторых протоколов |
| Закрыть окно |
| [root@localhost root]# netstat - anA inet Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 192.168.102.125:22 192.168.102.1:33208 ESTABLISHED udp 0 0 0.0.0.0:11 0.0.0.0:* |
| Пример 14.7. Просмотр установленных соединений и служб |
| Закрыть окно |
| [root@localhost root]# telnet 192.168.102. 1 112 Trying 192.168.102.1... telnet: connect to address 192.168.102.1: Connection refused [root@localhost root]# telnet 192.168.102.1 111 Trying 192.168.102.1... Connected to 192.168.102.1. Escape character is '^]'. ^[ telnet> close Connection closed. |
| Пример 14.8. Использование telnet |
| Закрыть окно |
| [root@localhost root]# grep quake /etc/services quake 26000/tcp quake 26000/udp [root@localhost root]# cat /etc/xinetd.d/ calendar service quake { socket_type = stream protocol = tcp wait = no user = nobody server = /usr/bin/cal disable = no } |
| Пример 14.9. Настройка cal в качестве сетевой службы |
| Закрыть окно |
| [root@localhost root]# service xinetd restart Stopping xinetd service: [ DONE ] Starting xinetd service: [ DONE ] [root@localhost root]# telnet localhost quake Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. December 2004 Su Mo Tu We Th Fr Sa 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
| Пример 14.10. Подключение к самодельной службе "календарь" |
| Закрыть окно |
| order hosts,bind multi on [root@localhost root]# cat /etc/resolv.conf domain nipponman.ru nameserver 192.168.102.1 [root@localhost root]# traceroute -q1 www.ru traceroute to www.ru (194.87.0.50), 30 hops max, 38 byte packets 1 fuji.nipponman.ru (192.168.102.1) 1.378 ms 2 ppp83-237-29-1.pppoe.mtu-net.ru (83.237.29.1) 41.155 ms 3 195.34.53.53 (195.34.53.53) 48.503 ms 4 195.34.53.53 (195.34.53.53) 24.033 ms 5 M9-cr01-A197-cr01.core.mtu.ru (195.34.53.10) 33.414 ms 6 M9-gw2-M9-cr01.core.mtu.ru (195.34.53.81) 26.259 ms 7 s-b3-pos0-0.telia.net (213.248.67.93) 59.791 ms 8 s-bb1-pos5-0-0.telia.net (213.248.66.1) 67.011 ms 9 mow-b1-pos1-0.telia.net (213.248.101.10) 76.138 ms 10 demos-101566-mow-okt-i1.c.telia.net (213.248.78.170) 78.591 ms 11 m9-3-GE4-0-0-vl10.Demos.net (194.87.0.66) 69.813 ms 12 www.ru (194.87.0.50) 70.583 ms |
| Пример 14.11. Работа DNS-клиента, встроенного в traceroute |
| Закрыть окно |
| methody@localhost:~ $ host www.ru www.ru has address 194.87.0.50 methody@localhost:~ $ host 194.87.0.51 51.0.87.194.in-addr.arpa domain name pointer www.demos-internet.ru. methody@localhost:~ $ host -t ns www.ru www.ru name server ns.demos.su. www.ru name server ns1.demos.net. methody@localhost:~ $ host -t mx www.ru www. ru mail is handled by 5 hq.demos.ru. |
| Пример 14.12. Утилита host |
| Закрыть окно |
| methody@localhost:~ $ dig www.us any ; <<>> DiG 9.2.4rc5 <<>> www.us any ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 6451 ;; flags: qr rd ra; QUERY: 1, ANSWER: 10, AUTHORITY: 0, ADDITIONAL: 4 ;; QUESTION SECTION: ;www.us. IN ANY ;; ANSWER SECTION: www.us. 1766 IN A 209.173.57.26 www.us. 1766 IN A 209.173.53.26 www.us. 1767 IN NS pine.neustar.com. www.us. 1767 IN NS willow.neustar.com. www.us. 1767 IN NS cypress.neustar.com. www.us. 1767 IN NS oak.neustar.com. www.us. 1771 IN MX 20 pine.neustar.com. www.us. 1771 IN MX 5 oak.neustar.com. www.us. 1771 IN MX 5 willow.neustar.com. www.us. 1771 IN MX 10 cypress.neustar.com. ;; ADDITIONAL SECTION: pine.neustar.com. 135024 IN A 209.173.57.70 willow.neustar.com. 135024 IN A 209.173.53.84 cypress.neustar.com. 135024 IN A 209.173.57.84 oak.neustar.com. 135024 IN A 209.173.53.70 ;; Query time: 932 msec ;; SERVER: 192.168.102.1#53(192.168.102.1) ;; WHEN: Wed Dec 22 22:01:24 2004 ;; MSG SIZE rcvd: 281 |
| Пример 14.13. Утилита dig |
| Закрыть окно |
Сетевой уровень
Создатели первых сетей, объединяющих несколько сред передачи данных, для идентификации абонента таких сетей пытались использовать те же аппаратные адреса. Это оказалось делом неблагодарным: если в Ethernet аппаратный адрес уникален всегда, то в других сетях аппаратные адреса могут быть уникальны только в рамках одной среды (например, все устройства нумеруются, начиная с 0) или даже могут выдаваться динамически, да и форматы аппаратных адресов в разных средах различны. Возникла необходимость присвоить каждому сетевому интерфейсу некоторый единственный на всю глобальную сеть адрес, который бы не зависел от среды передачи данных и всегда имел один и тот же формат.
Сетевые протоколы. Семейство протоколов TCP/IP
Так случилось, что Мефодий мало что знал о компьютерных сетях до знакомства с Linux. Если пользоваться только web-броузером и почтовой программой, сведений вроде "у каждого компьютера Internet есть имя, на компьютерах бывает почта и WWW" обычно вполне достаточно. Строго говоря, если сеть настроена, почтовые клиенты или броузеры Linux не требуют большего объема знаний. Однако Linux хорош именно тем, что позволяет проследить работу сети от процедур самого низкого уровня, вроде поведения сетевых карт, до приложений высокого уровня и их протоколов.
В разговоре о сетях передачи данных понятие "уровень" возникает неспроста. Дело в том, что передача данных между компьютерами – сложный процесс, в котором решается сразу несколько разноплановых задач. Если представить себе весь процесс организации сети "на пустом месте", как если бы никаких сетевых разработок доныне не было, все эти задачи встают одна за другой.
Итак, если бы Мефодий получил задание "придумать Internet" на пару с Гуревичем, какие бы вопросы перед ними встали?
Среда передачи данных. Посредством чего передавать данные? Как именно представляется передаваемая информация?Устройство передачи данных (раз уж известно, как передаются данные). Как подключаться к среде? Как отличить данные от не-данных (т. е. определить, идет ли передача)? Как определить очередность работы нескольких устройств, подключенных к одной среде передачи данных? Как определить, кому предназначаются данные, передаваемые в общей среде?Топология неоднородной сети (раз уж известно, как подключить компьютер к одной или нескольким средам передачи данных). Если в сеть объединены несколько сред передачи данных, как определить адресата (и отправителя тоже)? Как обеспечить пересылку данных из одной среды в другую? Как выстроить непрерывный маршрут пересылок от отправителя к адресату?Доставка данных (раз уж есть механизм передачи данных от любого абонента сети к любому). Как обеспечить целостность и надежность передачи данных (и нужно ли)? Как управлять самим каналом передачи данных (например, чтобы не отправлять данных больше, чем принимающая сторона в состоянии принять)? Как разделять несколько каналов передачи данных (например, когда от одного компьютера к другому одновременно передаются два файла)?Интерпретация данных (раз уж возможна надежная и без искажений доставка). Что делать с полученными данными? Какие части операционной системы отвечают за их обработку, и откуда про это знает абонент с другой стороны соединения?
Ответы на эти вопросы в формализованном виде носят название протоколов: в них пунктуально описывается, как именно предлагается решать ту или иную задачу, какая для этого необходима дополнительная информация, какова должна быть логика поведения передающей и принимающей стороны и т. п.
В приведенном делении на этапы (уровни) примечательна их относительная независимость: если группа задач, связанная с некоторым уровнем, решена, на следующем уровне можно забыть, как именно решались эти задачи. Так, устройство передачи данных типа "Ethernet" с точки зрения компьютера всегда одно и то же, какой бы носитель при этом не использовался: коаксиальный кабель или кабель типа "витая пара", хотя с физической и даже топологической точки зрения эти среды сильно различаются1). Точно так же обстоят дела при переходе со второго уровня на третий: во время получения данных уже совершенно неважно, какие среды передачи были при этом задействованы (ethernet, три провода, голубиная почта 2)...). Переход с третьего уровня на четвертый и с четвертого на пятый тоже обладает этим свойством.
По всей видимости, именно с этими задачами сталкивались и разработчики из института ARPA (Advanced Research Projects Agency, "Агентство перспективных исследовательских проектов"; в процессе работы оно было переименовано в DARPA, где "D" означало Defence). По крайней мере, предложенное ими в середине семидесятых семейство протоколов TCP/IP также подразделялось на пять уровней: аппаратный, интерфейсный, сетевой, транспортный и прикладной. Впоследствии аппаратный уровень стали смешивать с интерфейсным, так как с точки зрения операционной системы они неразличимы3). Именно разделение на независимые друг от друга уровни позволило со временем объединить большинство разнородных локальных сетей в единое сетевое пространство – глобальную сеть Internet.
В TCP/IP вопрос о том, как обеспечить нескольким абонентам сети возможность передавать данные, не мешая друг другу, решен с помощью разделения пакетов данных. разделение пакетов предполагает, что данные передаются не единым блоком, а по частям, пакетами. Алгоритмы, определяющие, когда абоненту разрешено посылать следующий пакет, могут быть разными, но результат всегда один: в сети передаются попеременно фрагменты всех сеансов передачи данных. В сильно загруженном состоянии такая сеть может просто не принять очередной пакет от абонента-отправителя, и тому придется ждать удобного случая, чтобы все-таки "пропихнуть" его в переполненную другими пакетами среду. Таким образом, обеспечить гарантированное время передачи одного пакета в сетях с разделением пакетов бывает довольно сложно, хотя существуют алгоритмы, позволяющие это сделать.
Противоположность метода разделения пакетов – метод разделения каналов, который предполагает, что в сети имеется определенное число каналов передачи данных, которые абоненты сети арендуют на все время передачи. По такому принципу построены, например, телефонные линии: дозвонившись, мы арендуем канал связи между двумя телефонными аппаратами, и до тех пор, пока этот канал занят, невозможно ни воспользоваться им кому-то другому, ни организовать параллельно передачу данных откуда-нибудь еще. Главное достоинство сетей с разделеним каналов – постоянная (за вычетом помех на линии) скорость передачи данных. Основной недостаток – ограниченное количество каналов передачи. Проектировать среду передачи так, чтобы каждый абонент был связан с каждым отдельным каналом, имеет смысл только тогда, когда абонентов очень мало: количество каналов будет пропорционально квадрату количества абонентов. Количество каналов в большой сети будет существенно меньшим, и ровно столько сеансов передачи данных можно будет в этой сети установить. Попытка соединиться с абонентом, когда все каналы уже заняты, окончится неудачей. Мефодий припомнил своего знакомого, дозвониться которому тяжело, хотя телефон тот занимает нечасто и не подолгу. По всей видимости, каналов между какими-то двумя АТС, через которые Мефодий связывается с приятелем, хронически недостает (так бывает, когда отдаленный район быстро застраивается и наполняется телефонами).
Если вернуться к сети с разделением пакетов, то можно заметить, что на каждом уровне под пакетом понимается разное. С точки зрения интерфейсного уровня пакет – это ограниченный возможностями среды передачи данных фрагмент, в котором необходимо дополнительно указать, какое устройство из числа подключенных к среде передачи данных его отправило и какому устройству он предназначен. С точки зрения сетевого уровня размер пакета определяется удобством его обработки, а дополнительно в нем надо указать уникальные для всей сети адреса отправителя и получателя (а также тип протокола и многое другое). С точки зрения транспортного уровня размер пакета определяется качеством связи (чем меньше пакет, тем ниже вероятность порчи, но тем больше теряется на дополнительной информации: идентификатор сеанса, тип, специальные поля, описывающие логику связи и т.п.). Наконец, если на прикладном уровне определено понятие "пакет", то его размер и содержимое определяются протоколом прикладного уровня.
Таким образом, процесс передачи данных выглядит так: порция данных прикладного уровня нарезается на части, соответствующие размеру пакета транспортного уровня (фрагментируется), к каждому фрагменту приписывается транспортная служебная информация, и получаются пакеты транспортного уровня. Каждый пакет транспортного уровня может быть опять-таки фрагментирован для передачи по сети, к каждому получившемуся фрагменту добавляется служебная информация сетевого уровня, что дает последовательность сетевых пакетов. Каждый из сетевых пакетов тоже может быть фрагментирован до размера, "пролезающего" через конкретное сетевое устройство, – из него формируются пакеты интерфейсного уровня (фреймы). Наконец, к каждому фрейму само устройство (по крайне мере, так это сделано в Ethernet) приписывает некоторый ключ, по которому принимающее устройство распознает Содержание фрейма. В таком виде данные передадутся по проводам. Процесс "заворачивания" пакетов более высокого уровня в пакеты более низкого уровня называется инкапсуляцией.
Компьютер, получивший фрейм, выполняет процедуры, обратные инкапсуляции и фрагментации: пакеты низкого уровня освобождаются от служебной информации и накапливаются до тех пор, пока не сформируется пакет более высокого уровня. Затем этот пакет отсылается на уровень выше и все повторяется до тех пор, пока освобожденные от всей дополнительной информации и заново собранные воедино данные не попадут к пользователю (или к программе, которая их обрабатывает).
Сетевой пакет. Единица передачи информации в компьютерной сети. Помимо передаваемых данных содержит служебную информацию, в частности, идентификаторы отправителя и адресата, контрольную сумму, поля используемого протокола. Наибольший размер пакета определяется чаще всего не объемом передаваемых данных, а требованиями протокола и необходимостью разделять сеть передачи данных между несколькими абонентами.
Ответы на эти вопросы в формализованном виде носят название протоколов: в них пунктуально описывается, как именно предлагается решать ту или иную задачу, какая для этого необходима дополнительная информация, какова должна быть логика поведения передающей и принимающей стороны и т. п.
В приведенном делении на этапы (уровни) примечательна их относительная независимость: если группа задач, связанная с некоторым уровнем, решена, на следующем уровне можно забыть, как именно решались эти задачи. Так, устройство передачи данных типа "Ethernet" с точки зрения компьютера всегда одно и то же, какой бы носитель при этом не использовался: коаксиальный кабель или кабель типа "витая пара", хотя с физической и даже топологической точки зрения эти среды сильно различаются1). Точно так же обстоят дела при переходе со второго уровня на третий: во время получения данных уже совершенно неважно, какие среды передачи были при этом задействованы (ethernet, три провода, голубиная почта 2)...). Переход с третьего уровня на четвертый и с четвертого на пятый тоже обладает этим свойством.
По всей видимости, именно с этими задачами сталкивались и разработчики из института ARPA (Advanced Research Projects Agency, "Агентство перспективных исследовательских проектов"; в процессе работы оно было переименовано в DARPA, где "D" означало Defence). По крайней мере, предложенное ими в середине семидесятых семейство протоколов TCP/IP также подразделялось на пять уровней: аппаратный, интерфейсный, сетевой, транспортный и прикладной. Впоследствии аппаратный уровень стали смешивать с интерфейсным, так как с точки зрения операционной системы они неразличимы3). Именно разделение на независимые друг от друга уровни позволило со временем объединить большинство разнородных локальных сетей в единое сетевое пространство – глобальную сеть Internet.
В TCP/IP вопрос о том, как обеспечить нескольким абонентам сети возможность передавать данные, не мешая друг другу, решен с помощью разделения пакетов данных. разделение пакетов предполагает, что данные передаются не единым блоком, а по частям, пакетами. Алгоритмы, определяющие, когда абоненту разрешено посылать следующий пакет, могут быть разными, но результат всегда один: в сети передаются попеременно фрагменты всех сеансов передачи данных. В сильно загруженном состоянии такая сеть может просто не принять очередной пакет от абонента-отправителя, и тому придется ждать удобного случая, чтобы все-таки "пропихнуть" его в переполненную другими пакетами среду. Таким образом, обеспечить гарантированное время передачи одного пакета в сетях с разделением пакетов бывает довольно сложно, хотя существуют алгоритмы, позволяющие это сделать.
Противоположность метода разделения пакетов – метод разделения каналов, который предполагает, что в сети имеется определенное число каналов передачи данных, которые абоненты сети арендуют на все время передачи. По такому принципу построены, например, телефонные линии: дозвонившись, мы арендуем канал связи между двумя телефонными аппаратами, и до тех пор, пока этот канал занят, невозможно ни воспользоваться им кому-то другому, ни организовать параллельно передачу данных откуда-нибудь еще. Главное достоинство сетей с разделеним каналов – постоянная (за вычетом помех на линии) скорость передачи данных. Основной недостаток – ограниченное количество каналов передачи. Проектировать среду передачи так, чтобы каждый абонент был связан с каждым отдельным каналом, имеет смысл только тогда, когда абонентов очень мало: количество каналов будет пропорционально квадрату количества абонентов. Количество каналов в большой сети будет существенно меньшим, и ровно столько сеансов передачи данных можно будет в этой сети установить. Попытка соединиться с абонентом, когда все каналы уже заняты, окончится неудачей. Мефодий припомнил своего знакомого, дозвониться которому тяжело, хотя телефон тот занимает нечасто и не подолгу. По всей видимости, каналов между какими-то двумя АТС, через которые Мефодий связывается с приятелем, хронически недостает (так бывает, когда отдаленный район быстро застраивается и наполняется телефонами).
Если вернуться к сети с разделением пакетов, то можно заметить, что на каждом уровне под пакетом понимается разное. С точки зрения интерфейсного уровня пакет – это ограниченный возможностями среды передачи данных фрагмент, в котором необходимо дополнительно указать, какое устройство из числа подключенных к среде передачи данных его отправило и какому устройству он предназначен. С точки зрения сетевого уровня размер пакета определяется удобством его обработки, а дополнительно в нем надо указать уникальные для всей сети адреса отправителя и получателя (а также тип протокола и многое другое). С точки зрения транспортного уровня размер пакета определяется качеством связи (чем меньше пакет, тем ниже вероятность порчи, но тем больше теряется на дополнительной информации: идентификатор сеанса, тип, специальные поля, описывающие логику связи и т.п.). Наконец, если на прикладном уровне определено понятие "пакет", то его размер и содержимое определяются протоколом прикладного уровня.
Таким образом, процесс передачи данных выглядит так: порция данных прикладного уровня нарезается на части, соответствующие размеру пакета транспортного уровня (фрагментируется), к каждому фрагменту приписывается транспортная служебная информация, и получаются пакеты транспортного уровня. Каждый пакет транспортного уровня может быть опять-таки фрагментирован для передачи по сети, к каждому получившемуся фрагменту добавляется служебная информация сетевого уровня, что дает последовательность сетевых пакетов. Каждый из сетевых пакетов тоже может быть фрагментирован до размера, "пролезающего" через конкретное сетевое устройство, – из него формируются пакеты интерфейсного уровня (фреймы). Наконец, к каждому фрейму само устройство (по крайне мере, так это сделано в Ethernet) приписывает некоторый ключ, по которому принимающее устройство распознает Содержание фрейма. В таком виде данные передадутся по проводам. Процесс "заворачивания" пакетов более высокого уровня в пакеты более низкого уровня называется инкапсуляцией.
Компьютер, получивший фрейм, выполняет процедуры, обратные инкапсуляции и фрагментации: пакеты низкого уровня освобождаются от служебной информации и накапливаются до тех пор, пока не сформируется пакет более высокого уровня. Затем этот пакет отсылается на уровень выше и все повторяется до тех пор, пока освобожденные от всей дополнительной информации и заново собранные воедино данные не попадут к пользователю (или к программе, которая их обрабатывает).
Сетевой пакет. Единица передачи информации в компьютерной сети. Помимо передаваемых данных содержит служебную информацию, в частности, идентификаторы отправителя и адресата, контрольную сумму, поля используемого протокола. Наибольший размер пакета определяется чаще всего не объемом передаваемых данных, а требованиями протокола и необходимостью разделять сеть передачи данных между несколькими абонентами.
Служба доменных имен
В предыдущих примерах Мефодий использовал ключ "-n" многих сетевых утилит, чтобы избежать путаницы между IP-адресами и доменными именами компьютеров. С другой стороны, доменные имена – несколько слов (часто осмысленных) —запоминать гораздо удобнее, чем адреса (четыре числа).
Когда-то имена всех компьютеров в сети, соответствующие IP-адресам, хранились в файле /etc/hosts. Пока абоненты Internet были наперечет, поддерживать правильность его содержимого не составляло труда. Как только сеть начала расширяться, неувязок стало больше. Трудность была не только в том, что содержимое hosts быстро менялось, но и в том, что за соответствие имен адресам в различных сетях отвечали разные люди и разные организации. Появилась необходимость структурировать глобальную сеть не только топологически (с помощью IP и сетевых масок), но и административно, с указанием, за какие группы адресов кто отвечает.
Проще всего было структурировать сами имена компьютеров. Вся сеть была поделена на домены – зоны ответственности отдельных государств ("us", "uk", "ru", "it" и т. п.) или независимые зоны ответственности ("com", "org", "net", "edu" и т. п.). Для каждого из таких доменов первого уровня должно присутствовать подразделение, выдающее всем абонентам имена, заканчивающиеся на ".домен" Подразделение обязано организовать и поддерживать службу, заменяющую файл hosts: любой желающий имеет право узнать, какой IP-адрес соответствует имени компьютера в этом домене или какому доменному имени соответствует определенный IP-адрес.
Такая служба называется DNS (Domain Name Service, служба доменных имен). Она имеет иерархическую структуру. Если за какую-то группу абонентов домена отвечают не хозяева домена, а кто-то другой, ему выделяется поддомен (или домен второго уровня), и он сам распоряжается именами вида "имя_компьютера.поддомен.домен". Например, за компьютеры в домене ".ru", принадлежащие корпорации "Dry Bugs", отвечают сотрудники соответствующего подразделения этой корпорации. Корпорация владеет поддоменом dbugs.ru. В домене ru не обязаны знать, какие именно адреса есть в поддомене, но обязаны предоставить информацию о том, как обратиться к серверу имен поддомена dbugs.ru.Сами сотрудники "Dry Bugs" тоже отвечают только за несколько собственных компьютеров, а всю ответственность за компьютеры в подразделениях перекладывают на сетевых администраторов этих подразделений, выделив им поддомены третьего уровня – pr.dbugs.ru, cook.dbugs.ru и warehouse.dbugs.ru. Таким образом, получается нечто вроде распределенной сетевой базы данных, хранящей короткие записи о соответствии доменных имен IP-адресам.
Доменное имя. Имя абонента Internet, имеющее текстовый формат и используемое вместо IP-адреса. Состоит из собственного имени абонента в домене и имени домена, определяющего административную принадлежность абонента. В отличие от IP-адреса, доменное имя не задается самим абонентом сети, а устанавливается службой доменных имен.
Все программы, работающие с доменными именами, оказываются клиентами какого-нибудь сервера доменных имен (DNS-сервера). Для этого они обращаются к функциям из библиотеки libresolv (или им подобным), а те уже определяют, как превратить доменное имя в адрес. Функции используют файл /etc/host.conf, описывающий, какими способами они должны выполнять преобразование доменных имен в адреса и обратно, а также формат выдачи данных в различных случаях. Обычно сначала проверяется файл /etc/hosts, а если там соответствий не найдено – /etc/resolv.conf. В resolv.conf указан домен по умолчанию (он приписывается в конец имени, если другим способом имя никак не удается преобразовать в адрес) и один-два адреса DNS-серверов, к которым и обращаются функции. В роли таких клиентов выступили утилиты ping и traceroute в предыдущих примерах, преобразуя имя www.ru в адрес 194.87.0.50. Если утилите traceroute не указывать ключ "-n", она подаст несколько DNS-запросов, по одному на каждый маршрутизатор, на обратное преобразование – из IP-адреса в доменное имя:
Пример 14.11. Работа DNS-клиента, встроенного в traceroute (html, txt)
Как видно из примера, обратное преобразование в современной сети работает не всегда. Отсутствие обратной зоны не поощряется сообществом, но и не считается преступлением. Мефодий заметил, что компьютер, не имеющий обратного преобразования адреса, вообще какой-то странный: один раз он передал пакет сам себе (здесь Мефодий не совсем прав: на самом деле этот маршрутизатор отчего-то уменьшает TTL пакета на 2, поэтому-то и на третьем, и на четвертом шаге именно он возвращает ICMP-сообщение). Кстати сказать, именно по причине того, что DNS- запрос невелик, зато даже один абонент сети может выдать их множество, основным транспортным протоколом для DNS выбран UDP, а не TCP (это не касается протоколов обмена целыми зонами между DNS-серверами – там, конечно, господствует TCP).
Если вся задача пользователя – это послать DNS-запрос, то лучше воспользоваться утилитой host, специально для этого предназначенной:
Пример 14.12. Утилита host (html, txt)
Довольно необычен формат, в котором хранятся таблицы обратного преобразования адресов. Оказывается, IP-адрес представлен в такой таблице как имя в домене in-addr.arpa, причем это имя совпадает с адресом, записанным задом наперед. Такой формат идет от иерархической структуры DNS. Если некоторая организация получает во владение сеть, допустим, 194.0.0.0/8, она должна обслуживать DNS-запросы к домену 194.in-addr.arpa. Если при этом сеть 194.87.0.0/16 передана другой организации, ей же передается обязанность обслуживать DNS-запросы к поддомену этого домена – 87.194.in-addr.arpa, и так вплоть до собственно IP-адресов. Вместо host можно использовать утилиту dig, которая выводит больше информации о том, как проходил сам
запрос.
Помимо записей типа "адрес" (A, прямое преобразование) и "указатель на имя" (PTR, обратное преобразование), в системе DNS может храниться и другая информация. Таблица (зона) некоторого домена должна содержать адреса доменных серверов всех его поддоменов (записи типа NS). Кроме того, в домене должно быть определено имя почтового пересыльщика (запись типа MX). Если почтовый пересыльщик домена не указан, электронная почта направляется почтовому пересыльщику родительского домена.
В зоне DNS есть даже запись типа "просто текст", TXT: при желании можно самому определить интерпретацию полей этой записи и организовать поверх DNS предназначенную для каких угодно целей базу данных по IP-адресам или доменным именам1). В отличие от dig, которой для запроса к обратной зоне требуется ключ "-x", утилита host различает запросы к прямой и обратной зонам по тому, задан ли в качестве параметра адрес или доменное имя. Для указания конкретного типа искомой записи обеим утилитам требуется этот тип передать явно. Тип any означает поиск всех записей с указанным именем:
Пример 14.13. Утилита dig (html, txt)
Пример 14.12. Утилита host
Довольно необычен формат, в котором хранятся таблицы обратного преобразования адресов. Оказывается, IP-адрес представлен в такой таблице как имя в домене in-addr.arpa, причем это имя совпадает с адресом, записанным задом наперед. Такой формат идет от иерархической структуры DNS. Если некоторая организация получает во владение сеть, допустим, 194.0.0.0/8, она должна обслуживать DNS-запросы к домену 194.in-addr.arpa. Если при этом сеть 194.87.0.0/16 передана другой организации, ей же передается обязанность обслуживать DNS-запросы к поддомену этого домена – 87.194.in-addr.arpa, и так вплоть до собственно IP-адресов. Вместо host можно использовать утилиту dig, которая выводит больше информации о том, как проходил сам
запрос.
Помимо записей типа "адрес" (A, прямое преобразование) и "указатель на имя" (PTR, обратное преобразование), в системе DNS может храниться и другая информация. Таблица (зона) некоторого домена должна содержать адреса доменных серверов всех его поддоменов (записи типа NS). Кроме того, в домене должно быть определено имя почтового пересыльщика (запись типа MX). Если почтовый пересыльщик домена не указан, электронная почта направляется почтовому пересыльщику родительского домена.
В зоне DNS есть даже запись типа "просто текст", TXT: при желании можно самому определить интерпретацию полей этой записи и организовать поверх DNS предназначенную для каких угодно целей базу данных по IP-адресам или доменным именам8). В отличие от dig, которой для запроса к обратной зоне требуется ключ "-x", утилита host различает запросы к прямой и обратной зонам по тому, задан ли в качестве параметра адрес или доменное имя. Для указания конкретного типа искомой записи обеим утилитам требуется этот тип передать явно. Тип any означает поиск всех записей с указанным именем:
methody@localhost:~ $ dig www.us any ; <<>> DiG 9.2.4rc5 <<>> www.us any ;; global options: printcmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 6451 ;; flags: qr rd ra; QUERY: 1, ANSWER: 10, AUTHORITY: 0, ADDITIONAL: 4 ;; QUESTION SECTION: ;www.us. IN ANY ;; ANSWER SECTION: www.us. 1766 IN A 209.173.57.26 www.us. 1766 IN A 209.173.53.26 www.us. 1767 IN NS pine.neustar.com. www.us. 1767 IN NS willow.neustar.com. www.us. 1767 IN NS cypress.neustar.com. www.us. 1767 IN NS oak.neustar.com. www.us. 1771 IN MX 20 pine.neustar.com. www.us. 1771 IN MX 5 oak.neustar.com. www.us. 1771 IN MX 5 willow.neustar.com. www.us. 1771 IN MX 10 cypress.neustar.com. ;; ADDITIONAL SECTION: pine.neustar.com. 135024 IN A 209.173.57.70 willow.neustar.com. 135024 IN A 209.173.53.84 cypress.neustar.com. 135024 IN A 209.173.57.84 oak.neustar.com. 135024 IN A 209.173.53.70 ;; Query time: 932 msec ;; SERVER: 192.168.102.1#53(192.168.102.1) ;; WHEN: Wed Dec 22 22:01:24 2004 ;; MSG SIZE rcvd: 281
Пример 14.13. Утилита dig
 |
|
|
Ethernet с коаксиальным кабелем имеет топологию "общая шина": все абоненты подключаются к единому кабелю, "врезая" в него Т-образный отводок; Ethernet с витой парой имеет топологию "звезда": от каждого абонента идет собственный кабель к центральному устройству-концентратору.
2)
Организация TCP/IP с помощью почтовых голубей описана в RFC1149.
3)
Поэтому, если в книге написано, что TPC/IP имеет четыре уровня, это тоже будет правдой — с учетом двойственности самого нижнего.
4)
Время ожидания не удваивается, а выбирается – опять-таки случайно, но из другого временного диапазона.
5)
Применяется побитовая операция "И".
6)
Значение "MTU:1492" наводит на мысль о том, что в качестве среды передачи данных был использован именно Ethernet (с MTU 1500), так как еще восемь байтов отводится для служебной информации самого PPP.
7)
Обратная ситуация, когда клиент хочет передать что-то серверу, сути дела не меняет: сервер предоставляет услугу клиенту, на этот раз – по приему данных.
8)
Так поступают, например, при создании "черных списков" абонентов сети, от которых почтовый сервер не принимает писем.
| © 2003-2007 INTUIT.ru. Все права защищены. |
Служебный протокол ICMP
Есть такие протоколы уровня IP, действие которых этим уровнем и ограничивается. Например, служебный протокол ICMP (Internet Control Message Protocol), предназначенный для передачи служебных сообщений. С одним примером применения ICMP Мефодий уже знаком: это утилита ping. Другое применение ICMP – сообщать отправителю, почему его пакет невозможно доставить адресату, или передавать информацию об изменении маршрута, о возможности фрагментации и т. п. Протоколом ICMP пользуется утилита traceroute, позволяющая приблизительно определять маршрут следования пакета (ключ "-n", как и в команде route, означает, что преобразовывать IP-адреса в доменные имена не надо):
[root@localhost root]# traceroute www.ru -n traceroute to www.ru (194.87.0.50), 30 hops max, 38 byte packets 1 192.168.102.1 0.223 ms 0.089 ms 0.105 ms 2 83.237.29.1 25.599 ms 21.390 ms 21.812 ms 3 195.34.53.53 24.111 ms 21.213 ms 25.778 ms 4 195.34.53.53 23.614 ms 33.172 ms 22.238 ms 5 195.34.53.10 43.552 ms 48.731 ms 44.402 ms 6 195.34.53.81 26.805 ms 21.307 ms 22.138 ms 7 213.248.67.93 41.737 ms 41.565 ms 42.265 ms 8 213.248.66.9 50.239 ms 47.081 ms 64.781 ms 9 213.248.65.42 99.002 ms 81.968 ms 62.771 ms 10 213.248.78.170 62.768 ms 63.751 ms 78.959 ms 11 194.87.0.66 101.865 ms 88.289 ms 66.340 ms 12 194.87.0.50 70.881 ms 67.340 ms 63.791 ms
Пример 14.5. Определения маршрута пакета (html, txt)
Утилита traceroute показывает список абонентов, через которых проходит пакет по пути к адресату, и потраченное на это время. Однако список этот приблизительный. Дело в том, что первому пакету (точнее, первым трем, так как по умолчанию traceroute шлет пакеты по три) в специальное поле TTL (Time To Live, время жизни) выставляется значение "1". Каждый маршрутизатор должен уменьшать это значение на 1, и если оно обнулилось, передавать отправителю ICMP-пакет о том, что время жизни закончилось, а адресат так и не найден. Так что на первую серию пакетов отреагирует первый же маршрутизатор, и traceroute выдаст первую строку маршрута. Второй пакет посылается с TTL=2, и, если за две пересылки адресат не достигнут, об этом рапортует второй маршрутизатор. Процесс продолжается до тех пор, пока очередной пакет не "доживет" до места назначения. Строго говоря, неизвестно, каким маршрутом шла очередная группа пакетов, потому что с тех пор, как посылалась предыдущая группа, какой-нибудь из промежуточных маршрутизаторов мог передумать и послать новые пакеты другим путем.
Транспортный уровень
Транспортных протоколов в TCP/IP два – это TCP (Transmission Control Protocol, протокол управления соединением) и UDP (User Datagram Protocol). UDP устроен просто. Пользовательские данные помещаются в единственный транспортный пакет-датаграмму, которой приписываются обычные для транспортного уровня данные: адреса и порты отправителя и получателя, после чего пакет уходит в сеть искать адресата. Проверять, был ли адресат способен этот пакет принять, дошел ли пакет до него и не испортился ли по дороге, предоставляется следующему – прикладному – уровню.
Иное дело – TCP. Этот протокол очень заботится о том, чтобы передаваемые данные дошли до адресата в целости и сохранности. Для этого предпринимаются следующие действия:
Устанавливается соединение
Перед тем, как начать передавать данные, TCP проверяет, способен ли адресат их принимать. Если адресат отвечает согласием на открытие соединения, устанавливается двусторонняя связь между ним и отправителем. Помимо адресов отправителя и адресата и номеров портов на отправителе и адресате, в TCP-соединении участвуют два номера последовательности (SEQuential Number, SEQN), с помощью которых каждая сторона проверяет, не потерялись ли пакеты по пути, не перепутались ли.
Обрабатываются подтверждения
Двусторонняя связь нужна еще и потому, что на каждый TCP-пакет с любой стороны требуется подтверждение того, что этот пакет принят. Упрощенно можно представить дело так, что отправитель и адресат по очереди обмениваются пакетами, каждый из которых содержит подтверждение только что принятого, и, возможно, полезные данные. Если происходит какая-то ошибка, она возвращается вместо подтверждения и отправитель обрабатывает ее (например, поcылает пакет еще раз).
Отслеживаются состояния абонентов
С первым же подтверждением каждый из абонентов передает размер т. н. скользящего окна (sliding window). Этот размер показывает, сколько еще данных готов принять адресат. Отправитель посылает сразу несколько пакетов суммарным размером с это окно, а после ждет подтверждения об их принятии. Когда приходит подтверждение первого из пакетов в окне, окно "скользит" вперед: теперь оно начинается со второго пакета, и в него попадает один или несколько еще не посланных пакетов. Если адресат может принять больше данных, он сообщает о большем размере окна, а если данные перерабатываться не успевают – о меньшем.
Кажется, что TCP – протокол во всех отношениях более удобный, чем UDP. Однако в тех случаях, когда пользовательские данные всегда помещаются в один пакет, зато самих пакетов идет очень много, посылать всего одну датаграмму намного выгоднее, чем всякий раз устанавливать соединение, пересылать данные и закрывать соединение (что требует, как минимум, по три пакета в каждую сторону). Очень трудно использовать TCP для широковещательных передач, когда число абонентов-адресатов весьма велико или вовсе неизвестно. Посмотреть параметры всех передаваемых через сетевой интерфейс пакетов можно с помощью команды tcpdump -pi интерфейс, хотя Мефодию не хватило поверхностного знания TCP/IP для того, чтобы понять выдачу этой команды.
Автоматическая настройка
Программа-настройщик регулярно предлагала Мефодию "настроить сеть автоматически". В режиме автоматической настройки практически не запрашиваются данные у пользователя. Это значит, что данные система должна брать откуда-то еще, видимо, со специального сервера в локальной сети.
Запрашивать сетевые настройки с сервера вместо того, чтобы хранить их на каждом компьютере, довольно удобно. В самом деле: один сервер, один администратор, один файл с общими настройками. Более того, можно вообще не хранить персональных настроек для каждого компьютера в сети, а ограничиться настройками групповыми – лишь бы IP-адреса внутри группы различались. Одним из первых был разработан протокол RARP (reverse ARP), который, как следует из названия, занимается преобразованием, обратным ARP: по интерфейсному адресу компьютер узнает у сервера сетевой адрес. В Ethernet-сетях для этого посылается широковещательный Ethernet-фрейм типа "RARP-запрос", который означает: "Вот мой MAC-адрес. Кто-нибудь, дайте мне IP!". На что специальная программа-сервер дает RARP-ответ: "Вот тебе IP!" – фреймом, содержащим IP-адрес, который сервер нашел в своей таблице. Если в сети нет ни одного RARP-сервера или ни в одном из них не зарегистрирован интерфейсный адрес компьютера-клиента, тот останется без IP. Похожую схему использует и протокол BOOTP, применяющийся для сетевой загрузки компьютеров. Предполагается, что, получив IP-адрес, клиент заберет с сервера (по протоколу TFTP, trivial FTP) некий файл, загрузит его в память и передаст управление. Поэтому в BOOTP передается не только IP-адрес клиента, но и IP-адреса TFTP-сервера и маршрутизатора по умолчанию и имя файла-загрузчика.
В современных сетях чаще всего используется протокол DHCP (Dynamic Host Configure Protocol, протокол динамической настройки сетевых абонентов). Он имеет очень широкие возможности: с сервера можно получить IP-адрес, сетевую маску и широковещательный адрес, имя домена, адреса маршрутизатора и серверов доменных имен, а также великое множество других параметров, вплоть до не предусмотренных в DHCP явно, так что их тип задается обычным числом, а интерпретация значения целиком определяется клиентом. Урезанную часть DHCP поддерживают "умные" сетевые устройства (те, что снабжены BootROM, т. е. ПЗУ с загрузочной программой). Но полностью обрабатывать все поля DHCP умеет специальный демон-клиент. В Linux этот демон называется dhcpcd (DHCP client daemon). В его ведении находится, как минимум, настройка сетевого интерфейса, маршрута по умолчанию и resolv.conf.
Так что все, что Мефодий делал вручную или вписывал в настроечный файл, можно получить "за просто так", если в сети работает DHCP-сервер:
[root@sakura root]# ifconfig lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 . . . [root@sakura root]# cat /etc/resolv.conf [root@sakura root]# /sbin/dhcpcd -h sakura -N eth0 dhcpcd.exe: interface eth0 has been configured with new IP=192.168.102.124 [root@sakura root]# ps gax | grep "dhcpcd" 1011 ? S 0:00 /sbin/dhcpcd -h sakura -N eth0 [root@sakura root]# cat /etc/resolv.conf nameserver 192.168.102.1 search nipponman.ru [root@sakura root]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:56:C1:36 inet addr:192.168.102.124 Bcast:192.168.102.255 Mask:255.255.255.0 . . .
Пример 15.9. Использование dhcpcd (html, txt)
Протокол DHCP позволяет передавать серверу желаемое имя и адрес компьютера. Впрочем, выдача IP-адреса привязана, как правило, к MAC-адресу. Здесь есть особая хитрость. DHCP может неплохо работать, когда IP-адресов не хватает на всех: компьютеров с разными MAC-адресами в сети больше, чем выделенных IP, но эти компьютеры никогда не включаются все одновременно. Компьютер, определяемый в DHCP по MAC-адресу, не "присваивает" выданный IP навсегда: адрес сдается в "аренду" (lease) на некоторое время. Если до истечения срока аренды бывший владелец не подтвердил желание пользоваться адресом и дальше (не послал повторный DHCP-запрос), адрес считается незанятым. Но когда компьютер подключается к сети после долгого перерыва, сервер DHCP сначала просматривает "арендную историю" на предмет того, какой IP этому абоненту уже выдавался. Если этот IP не занят, то будет выдан именно он. И только когда к сети подключится совсем новый абонент (а все адреса уже когда-нибудь кому-то выдавались) среди них будет выбран и отдан в аренду новичку тот, что дольше всех оставался невостребованным.
Наконец, чтобы избавиться и от этой ручной работы, можно перенастроить ifcfg-eth0 на использование DHCPD:
[root@sakura root]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 BOOTPROTO=dhcp NETMASK=255.255.255.0 ONBOOT=yes
Пример 15.10.. Настройка интерфейса на DHCP по умолчанию (html, txt)
Доступ к почтовым ящикам
Электронная почта нужна далеко не только тем, кто имеет терминальный доступ к Linux-машине. Доступ к почтовому ящику на сервере не должен зависеть от того, есть ли у данного пользователя право запускать на этом сервере какие-то программы. Для этого необходимо организовать специальную службу, предоставляющую пользователю только возможность манипулировать сообщениями в своем ящике с помощью программы-клиента. Самые популярные протоколы доступа к ящикам – POP3 (Post Office Protocol версии 3) и IMAP4 (Internet Message Access Protocol версии 4).
POP3 – довольно простой протокол, в нем определен единственный почтовый ящик пользователя, где тот может посмотреть список заголовков сообщений, прочитать (скачать) и удалить некоторые из них. Такой протокол удобен, когда пользователь хранит всю переписку на своем компьютере, а удаленный почтовый ящик служит исключительно для приема входящей почты. Протокол IMAP4 гораздо сложнее: в нем разрешено заводить несколько ящиков на сервере, в том числе и вложенных подобно каталогам. Каждый из этих ящиков может обладать особыми свойствами: может быть входящим (тогда пользователь уведомляется о новых поступлениях в этот ящик), мусорной корзиной (сообщения из которой удаляются после того, как устареют), и даже быть исходящим (в такой ящик пользователь складывает новые письма, а сервер их через некоторое время отсылает, удаляя оттуда). IMAP4 подходит для ситуации, когда пользователь не имеет возможности хранить свою переписку и/или обрабатывать ее с одного и того же компьютера, поэтому хранит ее в ящиках на сервере. IMAP4 используют и в качестве "движка" WEB-почты, этого заменителя почтовых клиентов для особо торопливых пользователей.
В большинстве случаев с помощью одного и того же почтового клиента можно и просматривать электронные письма в ящиках, и создавать новые письма, и отсылать их. Это сделано для удобства пользователя, однако стоит понимать, что общее у этих трех действий – только формат сообщения. Строго говоря, при доступе к почтовому ящику совершенно неважно, каким путем там оказалось письмо, а при пересылке почты никак не определяется, каким способом пользователь будет ее читать. Что касается написания письма – чье же это дело, как не текстового редактора?
Как водится, в Linux есть несколько IMAP/POP-серверов. Наиболее мощный из них – Cyrus (его авторы участвовали в разработке протокола IMAP4). В нем поддерживается больше всего дополнений и расширений IMAP, которые бывает удобно использовать, наиболее простой – UWIMAP, разрабатываемый в университете штата Вашингтон. UW-IMAP вообще не имеет конфигурационного файла: пользователи, пароли, входящие почтовые ящики и домашние каталоги для личных почтовых ящиков берутся системные (при этом вместо командного интерпретатора почтовому пользователю можно выдать /sbin/nologin или /usr/bin/passwd). Сервер Binc можно рекомендовать для применения на системах, использующих QMail, интеграция с которым других IMAP-серверов имеет некоторые шероховатости, а сервер Dovecot – тем, кто, как и его авторы, в первую очередь озабочен надежностью работы сервиса1).
Протоколы POP3 и IMAP4, как и многие другие,являются текстовыми. Как и в большинстве других протоколов, это порождает проблему передачи пароля в открытом виде. Решается она так же, как и для других протоколов – "заворачиванием" всего сеанса в SSL (порту 110–POP3 соответствует порт 995–POP3S, а порту 143–IMAP4 – 993–IMAPS), либо использованием внутрисеансового шифрования с помощью TLS. Кроме того, в протоколе POP3 есть и собственное расширение, APOP, решающее ту же задачу. Здесь Мефодий опять вспомнил своего незадачливого приятеля: чтобы не сильно задумываться, тот всегда использовал один и тот же пароль, в том числе и для доступа к почте по протоколу POP3 без всяких SSL/TLS/APOP... Увы, эта беззаботность ему даром не прошла: однажды его учетной записью кто-то воспользовался для отправки почты с помощью SMTPAUTH – конечно же, это оказался спам.
Фильтрация
Мефодий озаботился судьбой изобретенного им "календарного сервера", показанного в примере на прошлой лекции. Как уже было замечено, он запустил этот сервис на порту 26000, используемом популярной сетевой компьютерной игрой, что может помешать игрокам. Поэтому Мефодий решил запретить обращение к 26000-му порту отовсюду, кроме самой машины, то есть со всех интерфейсов, кроме lo. С этой задачей справлялась настройка only_from = 127.0.0.1 метадемона, но ее пришлось выключить, так как она автоматически запрещала доступ из сети ко всем сервисам компьютера:
Пример 15.13. Фильтрация TCP-запросов из сети (html, txt)
Команды iptables получаются довольно длинными: нужно аккуратно описать свойства каждого фильтруемого пакета. В примере Мефодий добавил два правила в таблицу filter цепочки INPUT (таблица filter выбирается по умолчанию, если не указан ключ "-t таблица"). Первое правило разрешает принимать TCP-пакеты, адресуемые на порт 26000, если они пришли из интерфейса lo. Проверка таких пакетов не дойдет до второго правила: по действию ACCEPT они немедленно отправятся дольше по конвейеру. Второе правило не просто уничтожает пакет, пришедший на 26000 порт, но и, как предписывает действие REJECT, посылает отправителю ICMP-пакет, сообщающий о том, что такие запросы не обслуживаются (при обычном действии DROP клиент некоторое время дожидается подтверждения). Из примера видно, что полнословные ключи iptables можно заменять однобуквенными. Кроме того, пример показывает, что стартовый сценарий iptables (в этом дистрибутиве) обрабатывает параметр save, который делает изменения, внесенные вручную, постоянными (service iptables start, выполняемый при загрузке системы, использует /etc/sysconfig/iptables).
FTP
В Linux существует несколько вариантов службы, предоставляющей доступ к файлам по протоколу FTP (File Transfer Protocol). Как правило, они отличаются друг от друга сложностью настроек, ориентированных на разные категории абонентов, подключающихся к серверу. Если выбор предоставляемых в открытый доступ данных велик, будет велик и наплыв желающих эти данные получить ("скачать"), так что возникает естественное желание этот наплыв ограничить. При этом, допустим, компьютеры из локальной сети могут неограниченно пользоваться файловыми ресурсами сервера, соединений из того же города или в пределах страны должно быть не более двух десятков одновременно, а соединений из-за границы – не более пяти. Такие ухищрения бывают нужны нечасто, но и они поддерживаются большинством FTP-демонов, вроде vsftpd, proftpd, pure-ftpd или wu-ftpd.
FTP – по-своему очень удобный протокол: он разделяет поток команд и поток собственно данных. Дело в том, что команды FTP обычно очень короткие, и серверу выгоднее обрабатывать их как можно быстрее, чтобы подолгу не держать ради них (часто – ради одной команды) открытое TCP-соединение. А вот файлы, передаваемые с помощью FTP, обычно большие, поэтому задержка при передаче в несколько долей секунды, и даже в пару секунд, не так существенна, зато играет роль пропускная способность канала. Было бы удобно, если бы для передачи команд использовался "быстрый, но тонкий" канал (т. е. среда передачи данных с малым временем отклика и небольшой пропускной способностью, например, наземное оптоволокно), а для передачи данных – "медленный, но толстый" (например, спутниковая магистраль).
Для того чтобы эти каналы было проще различить, данные в FTP пересылаются по инициативе сервера, то есть именно сервер подключается к клиенту, а не наоборот. Делается это так: клиент подключается к 20-му порту сервера (управляющий порт FTP) и передает ему команду: "Хочу такой-то файл. Буду ждать твоего ответа на таком-то (временно выделенном) порту". Сервер подключается со своего 21-го порта (порт данных FTP) к порту на клиенте, указанном в команде, и пересылает содержимое запрошенного файла, после чего связь по данным разрывается и клиент перестает обрабатывать подключения к порту.
Трудности начинаются, когда FTP-клиент находится за межсетевым экраном. Далеко не каждый администратор согласится открывать доступ из любого места Internet к любому абоненту внутренней сети по любому порту (пускай даже и с порта 21)! Да это и не всегда просто, учитывая подмену адресов. Для того чтобы FTP работал через межсетевой экран, придумали протокол Passive FTP. В нем оба сеанса связи – и по командам, и по данным – устанавливает клиент. При этом происходит такой диалог. Клиент: "Хочу такой-то файл. Но пассивно". Сервер: "А. Тогда забирай его у меня с такого-то порта". Клиент подключается к порту сервера и получает оттуда содержимое файла. Если со стороны сервера тоже находится бдительный администратор, он может не разрешить подключаться любому абоненту Internet к любому порту сервера. Тогда не будет работать как раз Passive FTP. Если и со стороны клиента, и со стороны сервера имеется по бдительному системному администратору, никакой вариант FTP не поможет.
Еще один недостаток протокола FTP: в силу двухканальной природы его трудно "затолкать" в SSL-соединение. Поэтому идентификация пользователя, если таковой имеется, в большинстве случаев идет открытым текстом. Мефодий тут же вспомнил про своего приятеля, который сначала завел себе где-то в Сети бесплатную WWW-страницу, файлы на которую надо было передавать по FTP, а потом отказался от этой затеи: кто-то с утомительным постоянством под завязку набивал эту страничку сомнительного вида архивами и программами. Несмотря на то, что для FTP подходит другой механизм шифрования, называемый TLS, далеко не все FTP-клиенты его поддерживают, и он оказывается не востребован на серверах. Поэтому рекомендуется задействовать службу FTP только для организации архивов публичного доступа.
HTTP
Эта часть лекции – обзорная, поскольку толковое и последовательное объяснение устройства многочисленных сетевых служб Linux требует, с одной стороны, отдельного курса лекций, а с другой стороны – хорошей теоретической и практической подготовки слушателя. Так что придется ограничиться поверхностным описанием наиболее востребованных для личного или домашнего пользования сервисов. Стоит заранее отметить, что описываемые задачи, как правило, могут решаться несколькими путями с помощью различных демонов или утилит, по-разному выполняющих одну и ту же работу. У администратора Linux всегда есть свобода выбора!
Мефодий, конечно, знает, что Internet как глобальная сеть компьютеров служит хранилищем глобальной сети документов под общим название WWW (World Wide Web, "Всемирная Паутина"). Связь между документами в Паутине обеспечивается за счет особого – гипертекстового – формата этих документов. Большинство из них написаны на специальном языке гипертекстовой разметки, HTML (Hyper Text Markup Language) или его диалектах и расширениях. Гипертекст может содержать ссылки на любые другие документы в Паутине. Формат такой ссылки описывается стандартом URL (Universal Resource Locator, всеобщий указатель ресурсов). Всемирность сети HTML-документов образовалась за счет удобства доступа к ним: огромное число абонентов Internet предоставляют возможность просмотра этих документов по специальному протоколу HTTP (Hyper Text Transfer Protocol), и еще большее число (фактически, каждый компьютер) запускают клиентские программы-навигаторы (или "броузеры", от англ. "browse", "просматривать"), позволяющие легко "переходить по ссылке", т. е. начинать просмотр документа, на который в выбранном месте ссылался исходный. Сами документы при этом принято называть WWW-страницами, или просто страницами.
Apache – HTTP-сервер, обладающий самым большим набором возможностей. Учитывая организованный в нем механизм подключаемых модулей (plug-ins), создавать которые может любой грамотный программист, описать умения Apache полностью, видимо, невозможно. Документация по одним только стандартным его возможностям занимает более 50 тысяч строк. Конфигурационные файлы Apache хранятся в /etc/httpd/conf (или, в зависимости от дистрибутива, /etc/apache). Главный конфигурационный файл – httpd.conf. Этот файл неплохо самодокументирован: вместе с комментариями в нем больше тысячи строк, что позволяет не изучать руководство, если администратор запамятовал синтаксис той или иной настройки, но, конечно, не позволяет вовсе не изучать его:
DirectoryIndex index.html index.htm index.shtml index.cgi AccessFileName .htaccess DocumentRoot "/var/www/html" Options Indexes Includes FollowSymLinks MultiViews AllowOverride None Order allow,deny Allow from all ScriptAlias /cgi-bin/ "/var/www/cgi-bin/" AllowOverride None Options ExecCGI Order deny,allow Deny from all Allow from 127.0.0.1 localhost
Пример 15.16. Отрывок конфигурационного файла apache (html, txt)
Пользователь, набравший в броузере "http://доменное_имя_сервера", увидит содержимое каталога, указанного настройкой DocumentRoot (в примере – /var/www/html). Каждый каталог, содержащий WWW-страницы, должен быть описан группой настроек, включающей права доступа к страницам этого каталога, настройки особенностей просмотра этих страниц и т. п. В частности, настройка DirectoryIndex описывает, какие файлы в каталоге считаются индексными – если такой файл есть в каталоге, он будет показан вместо содержимого этого каталога. Если в настройке каталога Options не указано значение Indexes, просмотр каталога будет вообще невозможен. Значение Includes этой настройки позволяет WWW-страницам включать в себя текст из других файлов, FollowSymLinks позволяет серверу работать с каталогами и файлами, на которые указывают символьные ссылки (это может вывести точку доступа за пределы DocumentRoot!), а MultiViews позволяет серверу для разных запросов на одну и ту же страницу выдавать содержимое различных файлов – сообразно языку, указанному в запросе.
Если настройку каталога AllowOverride установить в All, в любом его подкаталоге можно создать дополнительный конфигурационный файл, изменяющий общие свойства каталога. Имя этого файла задает настройка AccessFileName (в примере – ".htaccess"). Доступом к страницам в каталоге управляют настройки Order, Deny и Allow. Так, доступ к каталогу /var/www/html разрешен отовсюду, а к каталогу /var/www/cgi-bin – только с самого сервера.
Важное свойство WWW-серверов – поддержка так называемых динамических WWW-страниц. Динамическая WWW-страница не хранится на диске в том виде, в котором ее получает пользователь. Она создается – возможно, на основании какого-то шаблона – непосредственно после запроса со стороны броузера. Никаких особенных расширений протокола HTTP при этом можно не вводить – просто сервер получает запрос на WWW-страницу, которой не соответствует ни один файл. Зато HTTP-адрес (точнее говоря, URL) этой страницы распознается сервером как динамический и передается на обработку выделенной для этого программе. Программа генерирует текст в формате HTML, который и передается пользователю в качестве запрошенной страницы. В примере для этого используется каталог /var/www/cgi-bin, группа настроек которого имеет единственный параметр Options – ExecCGI. Для того чтобы этот каталог, в действительности не входящий в /var/www/html, был доступен броузеру как подкаталог /cgi-bin всего дерева, необходимо прикрепить его к DocumentRoot с помощью ScriptAlias; эта настройка говорит также и о том, что файлы в этом каталоге – сценарии, и их надо запускать, а не показывать1).
Как и многие другие прикладные протоколы, HTTP был и остается текстовым. При желании можно выучить команды HTTP и получать странички с серверов с помощью telnet вручную. Это означает, что любая система идентификации, основанная на одном только HTTP, будет небезопасна: если передавать учетные данные непосредственно по HTTP, любой абонент сети на протяжении всего маршрута пакета от броузера к серверу сможет подглядеть внутрь этого пакета и узнать пароль. Более или менее безопасно можно чувствовать себя, только зашифровав весь канал передачи данных. Для этого неплохо подходит алгоритм шифрования с открытым ключом, описанный в разделе "Терминальный доступ". Универсальный способ шифрования большинства текстовых прикладных протоколов называется SSL (Secure Socket Layer (уровень надежных сокетов)). Идея этого способа в том, что шифрованием данных занимается не само приложение, а специальная библиотека работы с сокетами, то есть шифрование происходит на стыке прикладного и транспортного уровней. Конечно, и клиент, и сервер должны включать в себя поддержку SSL, поэтому для служб, защищенных таким способом, обычно отводятся другие номера портов (например, 80 – для HTTP, и 443 – для HTTPS). В Apache этим занимается специальный модуль – mod_ssl, его настройки и способ организации защищенной службы можно найти в документации.
Несмотря на то, что Apache решает практически любые задачи, связанные с организацией WWW-страниц, есть, конечно, и области, где его применение нежелательно или невозможно. Если, например, задача WWW-сервера – отдавать десяток-другой статически оформленных страниц небольшому числу клиентов, запускать для этого Apache – все равно что стрелять из пушки по воробьям. Лучше воспользоваться сервером thttpd, специально для таких задач предназначенным: он займет намного меньше ресурсов системы. Особая ситуация возникает, если самый важный параметр сервера – его быстродействие. Например сервер, раздающий так называемые "баннеры" (banners, небольшие картинки рекламного характера), приносит тем больше дохода, чем быстрее работает, а значит, может обслуживать больше клиентов. Способ радикально уменьшить время отклика такого сервера на HTTP-запрос – оформить его не в виде демона, а в виде модуля ядра. Такой сервер существует в виде дополнений к ядру Linux под общим названием tux.
Межсетевой экран
В Linux существует мощный механизм анализа сетевых и транспортных пакетов, позволяющий избавляться от нежелательной сетевой активности, манипулировать потоками данных и даже преобразовывать служебную информацию в них. Обычно такие средства носят название "firewall" ("fire wall" – противопожарная стена, брандмауэр), общепринятый русский термин – межсетевой экран. В более старых версиях межсетевого экрана Linux использовался вариант межсетевого экрана ipchains, который впоследствии был заменен на более мощный, iptables.
Суть iptables в следующем. Обработка сетевого пакета системой представляется как его конвейерная обработка. Пакет нужно получить из сетевого интерфейса или от системного процесса, затем следует выяснить предполагаемый маршрут этого пакета, после чего отослать его через сетевой интерфейс либо отдать какому-нибудь процессу, если пакет предназначался нашему компьютеру. Налицо три конвейера обработки пакетов: "получить – маршрутизировать – отослать" (действие маршрутизатора), "получить – маршрутизировать – отдать" (действие при получении пакета процессом) и "взять – маршрутизировать – отослать" (действие при отсылке пакета процессом).
Между каждыми из этих действий системы помещается модуль межсетевого экрана, именуемый цепочкой. Цепочка обрабатывает пакет, исследуя, изменяя и даже, возможно, уничтожая его. Если пакет уцелел, она передает его дальше по конвейеру. В этой стройной схеме есть два исключения. Во-первых, ядро Linux дает доступ к исходящему пакету только после принятия решения о его маршрутизации, поэтому связка "взять – маршрутизировать" остается необработанной, а цепочка, обрабатывающая исходящие пакеты (она называется OUTPUT) вставляется после маршрутизации. Во-вторых, ограничения на "чужие" пакеты, исходящие не от нас и не для нас предназначенные, существенно отличаются от ограничений на пакеты "свои", поэтому после маршрутизации транзитные пакеты обрабатываются еще одной цепочкой (она называется FORWARD). Цепочка, обслуживающая связку "получить – маршрутизировать", называется PREROUTING, цепочка, обслуживающая связку "маршрутизировать – отдать" – INPUT, а цепочка, стоящая непосредственно перед отсылкой пакета – POSTROUTING:
В варианте ipchains каждая цепочка представляла собой таблицу правил. В правиле задаются свойства пакета и действие, которое нужно выполнять со всеми пакетами, обладающими указанными свойствами. Когда пакет попадает в таблицу, к нему начинают последовательно применяться правила.
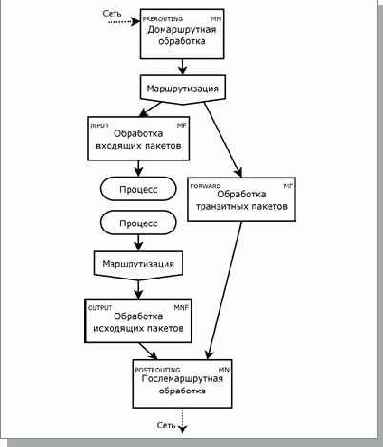
Рис. 15.1. Обработка пакетов цепочками iptables
Если пакет не имеет свойств, требуемых первым правилом, к нему применяется второе, если второе также не подходит – третье, и так вплоть до последнего, правила по умолчанию, которое применяется к любому пакету. Если свойства пакета удовлетворяют правилу, над ним совершается действие. Действие DROP уничтожает пакет, а действие ACCEPT немедленно выпускает его из таблицы, после чего пакет движется дальше по конвейеру. Некоторые действия, например LOG, никак не влияют на судьбу пакета, после их выполнения он остается в таблице: к нему применяется следующее правило, и т. д. до ACCEPT или DROP.
Из сказанного выше следует, что действия ACCEPT или DROP в каждой таблице могут применяться к пакету лишь однократно. Для большей гибкости цепочки iptables состоят из нескольких (двух-трех) таблиц. Выходя "живым" из одной таблицы, пакет попадает в следующую, а уж последняя передает его, если завершается действием ACCEPT, на конвейер. Хотя таблицы функционально одинаковы, принято использовать их по разному назначению. Таблицу mangle используют для внесения исправлений в служебную информацию пакета, таблицу filter – для определения того, не стоит ли пакет уничтожить, а таблицу nat – для подмены сетевых адресов. В приведенной выше диаграмме буквами M, N и F отмечено, какие именно таблицы есть в цепочках и в каком порядке их проходит пакет.
Для просмотра правил во всех таблицах всех цепочек iptables можно воспользоваться командой iptables-save:
[root@sakura root]# iptables-save # Generated by iptables-save v1.2.11 on Fri Dec 24 21:06:12 2004 *nat :PREROUTING ACCEPT [1:261] :POSTROUTING ACCEPT [3:220] :OUTPUT ACCEPT [3:220] COMMIT # Completed on Fri Dec 24 21:06:12 2004 # Generated by iptables-save v1.2.11 on Fri Dec 24 21:06:12 2004 *filter :INPUT ACCEPT [7:1077] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [5:355] COMMIT # Completed on Fri Dec 24 21:06:12 2004 # Generated by iptables-save v1.2.11 on Fri Dec 24 21:06:12 2004 *mangle :PREROUTING ACCEPT [7:1077] :INPUT ACCEPT [7:1077] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [5:355] :POSTROUTING ACCEPT [5:355] COMMIT # Completed on Fri Dec 24 21:06:12 2004
Пример 15.12. Пустые цепочки iptables (html, txt)
Команда группирует одинаковые таблицы каждой цепочки. В пустой таблице присутствует только правило по умолчанию (policy), в этом примере все умолчания равны ACCEPT (пропускать пакет).
Настройка при установке или загрузке системы
Мефодий очень обрадовался заработавшей сети и немедленно принялся сочинять простейший стартовый сценарий, который выполнял бы все нужные команды автоматически. Выяснилось, что такой сценарий уже есть в любом дистрибутиве Linux, хотя называться он может по-разному – как правило, /etc/init.d/network или networking. Как и полагается стартовому сценарию, с параметром start он настраивает сеть, а с параметром stop – "выключает" сетевые настройки.
Безусловно, ни список сетевых интерфейсов, ни параметры их настройки не указаны в самом стартовом сценарии, как хотел сделать Мефодий. Всевозможные сетевые настройки хранятся в /etc отдельно, как правило, в специальном подкаталоге. В разных дистрибутивах Linux применяются различные схемы размещения настроек. Система, установленная на компьютере Мефодия, использует общий подкаталог /etc/sysconfig для хранения большинства настроек, используемых не службами, а самими стартовыми сценариями, в том числе и network:
[root@sakura root]# ls -F /etc/sysconfig/ acpi framebuffer init network-scripts/ vlan apmd harddisk/ keyboard* nfs xfs autologin* harddisks keyboard.rpmnew pcmcia* xinetd bootsplash hotplug klogd rawdevices xinitrc clock* hwconf kudzu syslogd console/ i18n* mouse* system* consolefont* i18n.rpmnew network* usb
Пример 15.4. Каталог /etc/sysconfig (html, txt)
Как видно из примера, в этом каталоге содержатся и конфигурационные файлы, и дополнительные сценарии, и вложенные подкаталоги для отдельных видов настроек.
За сеть непосредственно отвечают файл /etc/sysconfig/network и содержимое подкаталога /etc/sysconfig/network-scripts:
[root@sakura root]# cat /etc/sysconfig/network NETWORKING=yes HOSTNAME=sakura.nipponman.ru DOMAINNAME=nipponman.ru GATEWAY=192.168.102.1
Пример 15.5. Настройка сети по умолчанию (html, txt)
Файл network оказался очень простым: в нем в формате shell определяются основные настройки сети: имя компьютера и домена, а также маршрутизатор по умолчанию. По-видимому, этот файл "втягивается" командой "." из самого сценария network:
[root@sakura root]# ls -F /etc/sysconfig/network-scripts/ README@ ifdown-ppp* ifup-ipv6* ifup-sl* ifcfg-eth0* ifdown-pre* ifup-ipx* net_cnx_pg* ifcfg-lo* ifdown-sit* ifup-plip* net_prog.default* ifdown@ ifdown-sl* ifup-plusb* net_resolv.default ifdown-aliases* ifup@ ifup-post* network-functions* ifdown-iptun* ifup-aliases* ifup-ppp* network-functions-ipv6* ifdown-ipv6* ifup-ctc* ifup-routes* ifdown-post* ifup-iptun* ifup-sit*
Пример 15.6. Каталог network-scripts
Каталог network- scripts содержит множество сценариев на все случаи сетевой жизни. В файле README описано, для чего какой сценарий нужен и что означают поля в каждом из них (часто этот файл хранится в /usr/share/doc/net-scripts, а не в /etc):
[root@sakura root]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 BOOTPROTO=static IPADDR=192.168.102.125 NETMASK=255.255.255.0 NETWORK=192.168.102.0 BROADCAST=192.168.102.255 ONBOOT=yes
Пример 15.7. Настройка интерфейса по умолчанию
А вот и настройки интерфейса eth0, которые Мефодию приходилось применять вручную. Таким образом, стоит только подать команду service network stop, как все сетевые интерфейсы "пропадут" (деактивизируются), а после service network start – снова появятся.
Как правило, пользователю вообще не обязательно редактировать эти файлы. С каждым дистрибутивом поставляется программа-конфигуратор, которая позволяет "настроить сеть", не вспоминая, какие данные, в каком формате и куда их нужно записывать. Обычно такая программа оформляется в стиле мастера, "кудесника", задающего только вопросы по существу, с ее помощью и формируются более или менее подходящие конфигурационные файлы. Результатов работы мастера в большинстве случаев бывает достаточно, а в тех случаях, когда искусственный интеллект пасует, администратор применяет свой естественный интеллект и текстовый редактор Vi. С другой стороны, изменить несколько значений в трех конфигурационных файлах не так уж сложно. Когда настройщик действительно необходим, так это во время установки системы на компьютер или непосредственно после нее. В этот момент настраивать приходится сразу все, так что любая экономия времени при этом существенна.
В некоторых дистрибутивах используется схема ifupdown, основанная на технологии ".d":
debian!shogun$ ls -F /etc/network if-down.d/ if-pre-up.d/ ifstate.hotplug interfaces if-post-down.d/ ifstate if-up.d/ options
Пример 15.8. Настройка сети с применением схемы ".d"
Настройка сетевых интерфейсов и маршрутизатора по умолчанию хранится в одном файле (считается, что редактировать его автоматически – просто). Тонкая настройка сети – в файле options. Каталоги if-preup.d, if-up.d, if-down.d и if-post-down.d предназначены для служб, которые хотят производить какие-то действия, соответственно, перед тем, как сетевой интерфейс будет активизирован ("поднят"), после успешной активизации интерфейса, перед тем как сетевой интерфейс будет деактивизирован ("опущен") и после этого.
Настройка сети
Итак, с работой сети в Linux Мефодий немного ознакомился, однако как эту сеть использовать для личных нужд, понятнее не стало. Прежде всего: как приучить имеющийся компьютер пользоваться имеющейся локальной сетью?
Настройка соединений "точка–точка"
Если компьютер стоит дома, далеко не всегда есть возможность подключиться к локальной сети, непосредственно граничащей с Internet. Для передачи небольших сообщений чаще всего используется временное подключение посредством телефонной линии. На обеих сторонах линии устанавливается модем – устройство, преобразующее один формат сигнала в другой. На российских телефонных линиях обычно используются аналоговые модемы, способные обмениваться данными по довольно низкокачественным линиям с большой долей помех и относительно неискаженной передачей сигнала только в диапазоне слышимых звуковых частот. За низкое качество канала приходится расплачиваться низкой скоростью передачи данных: на таких модемах она до сих пор не превышает (после отбрасывания служебной информации, ошибок и прочего) трех-четырех килобайтов в секунду, а в действительности бывает раза в два меньше.
Соединение между двумя устройствами, вообще говоря, не сетевыми, а только способными передавать данные, описывается несколькими протоколами. Самый распространенный из них – PPP (Point-to-Point Protocol, протокол "точка–точка") – решает задачи, возникающие в силу особенностей соединений "точка–точка".
Во-первых, само участвующее в соединении устройство почти никогда не бывает представлено в виде сетевого интерфейса, потому что не обладает нужными для организации сети свойствами. Это значит, что какая-то часть системы (скорее всего, демон) будет разговаривать с устройством на понятном ему языке, а с пользовательскими утилитами взаимодействовать посредством специально организованного виртуального сетевого интерфейса.
Во-вторых, нет необходимости поддерживать часть интерфейсного протокола: на среде передачи данных два абонента , никакой идентификации не требуется, потому что каждый может отличить себя от не-себя. Так, виртуальный сетевой интерфейс ppp0, соответствующий устройству, обменивающемуся данными по протоколу PPP, не обладает MAC-адресом.
В-третьих, оттого, что соединение не постоянное, а среда за время, пока абоненты не были связаны, могла измениться до неузнаваемости, обеим сторонам приходится при каждом дозвоне идентифицировать себя. Обычно идентифицируется только сторона, которой предоставляется доступ в сеть, но проверять, до нужного ли места мы дозвонились, тоже не мешает. При установлении соединения "точка–точка" процедуры идентификации проходят после того, как появляется возможность передавать данные, но до всякой сетевой настройки. Мало того, данные по настройке сети (аналогичные тем, что используются в DHCP) также передаются на этом этапе взаимодействия по протоколу PPP.
В силу того, что дозвон нужен пользователям самого разного уровня знаний, для PPP написано множество программ-"звонилок", использующих графическую подсистему, со звуками и прочими не относящимися к делу украшениями. Пример такой программы – kppp, утилита модемного доступа для рабочего стола KDE. Все, что требуется от пользователя – это указать модем, список телефонов, по которому надо звонить и тип идентификации. Впрочем, и здесь пользователь не освобождается от "тяжелой" мыслительной работы: некоторые провайдеры (организации, предоставляющие выход в Internet) после дозвона требуют идентификацию не по протоколу PPP, а открытым текстом, на манер "login–password" в Linux. Иногда это и есть самый настоящий login: пользователю предоставляется терминальный доступ, а дальше пускай делает, что хочет. В этом случае приходится писать сценарий-диалог (chat script) в стиле "Дождаться строки "login:" – ввести входное имя. Дождаться строки "Password:" – ввести пароль. Дождаться подсказки командного интерпретатора – ввести "pppd" с параметрами".
Что совсем уже просто для пользователя, так это утилита wvdial, описанная в лекции 12. Она и модем сама определяет, и тип идентификации, и pppd настраивает и запускает тоже сама. В действительности же сетью занимается демон pppd, чьи конфигурационные файлы находятся в каталоге /etc/ppp:
[root@sakura root]# ls /etc/ppp callback-client chap-secrets ip-up options.dialin peers callback-server ip-down ip-up.d options.dialout callback-users ip-down.d options pap-secrets [root@sakura root]# ls -l /etc/ppp/*secrets -rw------- 1 root root 78 Jun 23 1995 /etc/ppp/chap-secrets -rw------- 1 root root 77 Jun 23 1995 /etc/ppp/pap-secrets
Пример 15.11. Каталог с настройками PPP (html, txt)
Большинство из этих файлов по умолчанию не используется. Следует помнить, что идентификационная информация, используемая в PPP (в зависимости от особенностей соединения и пристрастий провайдера могут применяться протоколы идентификации PAP или CHAP), хранится в файлах pap-secrets и chap-secrets в текстовом виде. Хранить не пароль, а ключ, как это сделано в /etc/shadow, нельзя, так что остается либо надеяться на права доступа к этим файлам, либо запускать pppd вручную (или с помощью тех же wvdial и kppp) и каждый раз этот пароль вводить.
Установить PPP-соединение можно поверх любой среды передачи данных, в том числе и поверх локальной сети. В этом случае pppd обменивается данными (посредством псевдотерминальной пары pty – tty или ptmx – pts/, описанной в лекции 11) с демоном pppoe, который играет роль "модема". При этом передаваемые данные можно сжимать или шифровать, а главное, связь "точка–точка" устанавливается с конкретным пользователем, который ввел одному ему известный пароль, поэтому часто выход в Internet, требующий строгого учета трафика, осуществляется именно с помощью пары pppd/pppoe. Наконец, в сети может быть настоящий модем, преобразующий эти данные в формат, пригодный для передачи по цифровым телефонным линиям (DSL). Кстати сказать, такой модем легко собирается из маленького компьютера с низким энергопотреблением, ядра Linux и доработанного стартового виртуального диска. Некоторые современные DSL-модемы устроены именно так, причем ядро и initrd записываются в перепрограммируемое ПЗУ.
Настройка вручную
Первая мысль – настроить сетевые интерфейсы вручную. Это довольно просто, если знать полагающиеся при настройке данные: IP-адрес самого компьютера, IP-адрес маршрутизатора по умолчанию и адрес сервера доменных имен.
Задать IP-адреса интерфейсам eth0 и lo можно уже известной командой ifconfig:
Пример 15.1. Настройка сетевых интерфейсов (html, txt)
Заметим, что вместе с IP-адресом необходимо указывать и сетевую маску, и широковещательный адрес сети. Теперь пакеты доходят до любого абонента локальной сети, но не дальше, поскольку не задан ни один маршрутизатор. Добавить маршрутизатор можно командой route add:
[root@sakura root]# route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.102.0 * 255.255.255.0 U 0 0 0 eth0 127.0.0.0 * 255.0.0.0 U 0 0 0 lo [root@sakura root]# ping 209.173.53.26 connect: Network is unreachable [root@sakura root]# route add default gw 192.168.102.1 [root@sakura root]# route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.102.0 * 255.255.255.0 U 0 0 0 eth0 127.0.0.0 * 255.0.0.0 U 0 0 0 lo default 192.168.102.1 0.0.0.0 UG 0 0 0 eth0 [root@sakura root]# ping 209.173.53.26 64 bytes from 209.173.53.26: icmp_seq=1 ttl=114 time=166 ms . . .
Пример 15.2. Добавление маршрутизатора по умолчанию (html, txt)
Мефодий заметил, что две записи уже были в таблице маршрутизации до выполнения команды route add: относительно локальных сетей 192.168.102.0/24 и 127.0.0.0/8. Эти записи появились там в результате настройки сетевых интерфейсов: для пополнения таблицы достаточно было адреса и сетевой маски. Не хватало только явного указания маршрутизатора. Ключевое слово default заменило параметр -net 0.0.0.0 (из предыдущей лекции известно, что сети 0.0.0.0/0 в таблице маршрутизации принадлежит любой адрес), а параметр gw означает "gateway", т. е. маршрутизатор.
Тем не менее, служба доменных имен пока не работает: необходимо заполнить файл /etc/resolv.conf:
[root@sakura root]# ping www.ru ping: unknown host www.ru [root@sakura root]# cat /etc/resolv.conf [root@sakura root]# cat > /etc/resolv.conf domain nipponman.ru nameserver 192.168.102.1 [root@sakura root]# ping www.ru PING www.ru (194.87.0.50) 56(84) bytes of data. 64 bytes from www.ru (194.87.0.50): icmp_seq=1 ttl=55 time=84.3 ms . . . [root@sakura root]# update_chrooted conf
Пример 15.3. Определение домена и DNS-сервера (html, txt)
Последнюю команду присоветовал Гуревич. Дело в том, что подсистему, работающую с DNS, нередко "сажают в песочницу", то есть переносят в отдельный каталог, в котором выполняется chroot. Как сказано в лекции 12, в такой "песочнице" должны быть все нужные для работы файлы – и уж конечно процедурам DNS необходим свой файл-копия /etc/resolv.conf. Информация о том, кому и что нужно копировать при изменении профиля системы, обычно хранится централизованно и управляется несложными сценариями. В данном дистрибутиве команда update_chrooted conf как раз и копирует все изменившиеся конфигурационные файлы по "песочницам".
Пример 15.2. Добавление маршрутизатора по умолчанию
Мефодий заметил, что две записи уже были в таблице маршрутизации до выполнения команды route add: относительно локальных сетей 192.168.102.0/24 и 127.0.0.0/8. Эти записи появились там в результате настройки сетевых интерфейсов: для пополнения таблицы достаточно было адреса и сетевой маски. Не хватало только явного указания маршрутизатора. Ключевое слово default заменило параметр -net 0.0.0.0 (из предыдущей лекции известно, что сети 0.0.0.0/0 в таблице маршрутизации принадлежит любой адрес), а параметр gw означает "gateway", т. е. маршрутизатор.
Тем не менее, служба доменных имен пока не работает: необходимо заполнить файл /etc/resolv.conf:
[root@sakura root]# ping www.ru ping: unknown host www.ru [root@sakura root]# cat /etc/resolv.conf [root@sakura root]# cat > /etc/resolv.conf domain nipponman.ru nameserver 192.168.102.1 [root@sakura root]# ping www.ru PING www.ru (194.87.0.50) 56(84) bytes of data. 64 bytes from www.ru (194.87.0.50): icmp_seq=1 ttl=55 time=84.3 ms . . . [root@sakura root]# update_chrooted conf
Пример 15.3. Определение домена и DNS-сервера
Последнюю команду присоветовал Гуревич. Дело в том, что подсистему, работающую с DNS, нередко "сажают в песочницу", то есть переносят в отдельный каталог, в котором выполняется chroot. Как сказано в лекции 12, в такой "песочнице" должны быть все нужные для работы файлы – и уж конечно процедурам DNS необходим свой файл-копия /etc/resolv.conf. Информация о том, кому и что нужно копировать при изменении профиля системы, обычно хранится централизованно и управляется несложными сценариями. В данном дистрибутиве команда update_chrooted conf как раз и копирует все изменившиеся конфигурационные файлы по "песочницам".
Пересылка почты
Еще один немаловажный сервис, отлично поддерживаемый в Linux, – пересылка электронной почты. Протокол SMTP (Simple Mail Transfer Protocol), задающий порядок пересылки почты, впервые был описан и помещен в RFC в самом начале 80-х годов. С тех пор он неоднократно модифицировался, однако в основе своей остался прежним: SMTP – это протокол передачи текстовых сообщений, снабженных вспомогательными заголовками, часть из которых предназначена для почтового сервера, передающего сообщения, а часть – для почтового клиента, с помощью которого пользователь просматривает эти сообщения.
RFC, Request For Comments, рабочее предложение - постоянно пополняемое собрание рабочих материалов (технических отчетов, проектов и описаний стандартов протоколов), используемых разработчиками и пользователями Internet.
В качестве адреса в электронном письме обычно используется сочетание пользователь@доменное_имя. Изначально поле пользователь совпадало с входным именем пользователя в UNIX-системе, а доменное_имя – с именем компьютера. Пользователь – удаленно или через "настоящий" терминал – подключался к системе и просматривал почту, скажем, утилитой mail. Когда компьютеров в сети стало больше, выяснилось, что, имея учетные записи на многих машинах, почту все-таки удобнее хранить и читать на одной машине, предназначенной только для почты, а значит, доменное_имя в почтовом адресе может не совпадать с доменным именем персонального компьютера адресата. Для удобства решили ввести один уровень косвенности: прежде чем соединяться с компьютером "доменное_имя", почтовый сервер проверяет, нет ли в DNS записи вида доменное_имя ... MX ... сервер. Эта запись означает, что почту, адресованную на пользователь@доменное_имя, необходимо посылать компьютеру "сервер" – а уж тот разберется, что делать дальше.
Иногда необходимо, чтобы сервер принимал письма, не предназначенные для зарегистрированных на нем пользователей. Эти письма немедленно помещаются в очередь на отправку, и пересылаются дальше. Такой режим работы сервера называется "relay" (пересыльщик). Когда-то все почтовые серверы работали в режиме "open relay", т. е. соглашались пересылать почту откуда угодно и куда угодно. К сожалению, этим немедленно стали пользоваться желающие подзаработать массовой рассылкой рекламы (т. е. "спамом"). Поэтому открытые пересыльщики сегодня запрещены RFC. Однако как минимум в трех случаях сервер имеет право работать пересыльщиком: если он пересылает почту от абонента обслуживаемой сети, если письмо адресовано в обслуживаемый домен или его поддомен, и если письмо исходит непосредственно от почтового клиента пользователя, который предварительно каким-нибудь способом идентифицировался в системе (например, с помощью разработанного для этого расширения SMTPAUTH). Во всех трех случаях ответственность за возможные злоупотребления почтовым сервисом возлагается на администратора сервера, так как он имеет возможность отыскать провинившегося пользователя.
В Linux существует несколько различных почтовых серверов. Во-первых, Sendmail, корифей почтового дела, возникший одновременно с SMTP. Возможности этого сервера весьма велики, однако воспользоваться ими в полной мере можно только после того, как научишься понимать и исправлять содержимое конфигурационного файла sendmail.cf, который уже более двадцати лет служит примером самого непонятного и заумного способа настройки. Впрочем, на сегодня для sendmail.cf на языке препроцессора m4 написано несметное, на все случаи жизни, число макросов, так что sendmail.cf редактировать не приходится. Вместо него из этих макросов составляется файл sendmail.mc, небольшой и вполне читаемый, а он, с помощью утилиты m4, транслируется в sendmail.cf, который не читает никто, кроме самого Sendmail. К сожалению, упростить исходный текст этой программы невозможно, поэтому специалисты по компьютерной безопасности не любят давать относительно нее гарантии: редко, но все же находится в sendmail какое-нибудь уязвимое место.
Другой вариант почтового сервера, Postfix, весьма гибок в настройке, прекрасно подходит для почтовых серверов масштаба предприятия, и, в отличие от Sendmail, более прозрачно спроектирован и написан. Он поддерживает все хитрости, необходимые современной почтовой службе: виртуальных пользователей, виртуальные домены, подключаемые антивирусы, средства борьбы со спамом и т. п. Настройка его хорошо документирована, в том числе с помощью комментариев в конфигурационном файле (как правило, /etc/postfix/main.cf), и с помощью файлов-примеров.
Стоит упомянуть еще как минимум три почтовых службы: QMail – по мнению многих, этот демон наиболее защищен и от атак извне, и от возможных ошибок в собственных исходных текстах; Exim – как наиболее гибкий в настройках (в том числе и пока не реализованных); и ZMailer, предназначенный для работы на больших и очень больших серверах, выполняющих, в основном, работу по пересылке.
Подмена адресов
Если в некоторой сети используются адреса из описанного стандартом RFC1918 внутреннего диапазона (например, из сети 10.0.0.0/8), то без дополнительных действий абоненты этой сети доступа к Internet иметь не будут. Пакеты с такими адресами запрещено передавать в Internet, а даже если они туда просочатся через маршрутизатор, соединяющий "внутреннюю" и "внешнюю" сети, следующий же маршрутизатор откажется их пересылать. Простая, казалось бы, мысль научить межсетевой экран, установленный на маршрутизаторе, подменять IP-адреса в пакетах, приходящих из внутренней сети, своим внешним IP-адресом, наталкивается на серьезное препятствие.
Допустим, абоненты с адресом 10.0.0.3 и 10.0.0.7 устанавливают TCP-соединение с адресом в Internet (скажем, 209.173.53.26). Специально обученный маршрутизатор подменяет 10.0.0.3 и 10.0.0.7 на адрес своего сетевого интерфейса, подключенного к внешней сети (допустим, 194.87.0.50). Пакеты уходят адресату, как если бы и тот, и другой были отправлены самим маршрутизатором. 209.173.53.26 отвечает на два запроса двумя пакетами, оба – на адрес 194.87.0.50. Что делать дальше? Как отличить пакет, предназначенный для 10.0.0.3 от такого же для 10.0.0.7?
На помощь приходит знание TCP. Как известно, TCP-соединение идентифицируется шестью параметрами: IP-адресами отправителя и получателя, портами на отправителе и получателе и номерами последовательности (SEQN) входящего и исходящего потока данных. В нашей схеме межсетевой экран обязательно заменяет IP-адреса одним, поэтому у двух принятых пакетов они совпадают. А вот с четырьмя оставшимися параметрами он волен поступать, как заблагорассудится: в любом случае каждому из сеансов должны соответствовать разные SEQN и разные номера исходящих портов. Осталось только держать в памяти таблицу соответствия TCP-соединений из внутренней сети TCP-соединениям во внешнюю сеть.
Этот механизм носит название "преобразование сетевых адресов" (Network Adress Translation, NAT). Следует помнить, что чем больше транспортных соединений отслеживается межсетевым экраном, тем больше требуется оперативной памяти ядру Linux и тем медленнее работает процедура сопоставления проходящих пакетов таблице. Впрочем, мощность современных компьютеров позволяет без каких-либо затруднений обслуживать преобразование адресов для сети с пропускной способностью 100Мбит/с и даже выше. В iptables есть специальный модуль для NAT и соответствующие действия в правиле. Такие правила принято помещать в таблицы типа nat:
[root@fuji root]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 83.237.29.1 0.0.0.0 255.255.255.255 UH 0 0 0 ppp0 192.168.102.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1 10.13.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo 0.0.0.0 83.237.29.1 0.0.0.0 UG 0 0 0 ppp0 [root@fuji root]# iptables-save # Generated by iptables-save v1.2.11 on Sat Dec 25 14:02:44 2004 *nat :PREROUTING ACCEPT [216:12356] :POSTROUTING ACCEPT [242:27148] :OUTPUT ACCEPT [1428:91596] -A POSTROUTING -o ppp+ -j MASQUERADE COMMIT . . .
Пример 15.14. Использование простейшего преобразования адресов (html, txt)
На том самом маршрутизаторе, где, по словам Гуревича, "всего один настоящий адрес, да и тот – PPP", как раз и настроено преобразование адресов. Делается это всего одним правилом, добавленным в таблицу nat цепочки POSTROUTING. Действие MASQUERADE отличается от действия SNAT (Source NAT) только тем, что может быть использовано на интерфейсах с изменяемым IP-адресом, таких как ppp или настраиваемый по DHCP eth. Если в процессе работы IP-адрес интерфейса поменяется, правило SNAT продолжит менять адреса на старый, заданный во время настройки iptables. Зато MASQUERADE вынуждено спрашивать у системы IP-адрес указанного интерфейса для каждого преобразуемого пакета, что может быть неудобно на очень медленных или очень загруженных разнообразными службами компьютерах.
Преобразование адресов работает не только для TCP-соединений, но и для многих других протоколов, где возможно отследить либо настоящего адресата на внутренней сети, либо идентификатор сеанса связи. Например, ICMP-пакет команды ping содержит уникальный идентификатор, который используется в ответе на него, поэтому не составляет труда отследить, на чей именно ping пришел ICMP-ответ. Таблица отслеживаемых соединений отражается в файле net/ip_conntrack виртуальной файловой системы /proc:
Пример 15.15. Просмотр таблицы подменяемых адресов (html, txt)
Так и есть: во-первых, Мефодий (скорее всего) что-то рассматривает на сайте www.ru (он же 194.87.0.50), а во-вторых, он зачем-то запустил ping www.us: команда cat подана как раз между ICMP-запросом по ад- ресу 209.173.53.26 и ответом на него. Левая часть таблицы описывает соединение до подмены адресов, а правая – после. Точно так же можно "ловить" и UDP-запросы к службе доменных имен, и многое другое.
Конечно, фильтрацией и маскарадом функции iptables не исчерпываются. Можно, например, задать статическую таблицу подмены адресов, тогда появится возможность принимать из Internet соединения, предназначенные для внутренних серверов. Того же можно добиться, используя подмену адреса только для соединений по определенным портам и т. д.
Настройка сетевых интерфейсов
| [root@sakura root]# ifconfig [root@sakura root]# ifconfig eth0 inet 192.168.102.125 netmask 255.255.255.0\ broadcast 192.168.102.255 [root@sakura root]# ifconfig lo inet 127.0.0.1 netmask 255.0.0.0\ broadcast 127.255.255.255 [root@sakura root]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:56:C1:36 inet addr:192.168.102.125 Bcast:192.168.102.255 Mask:255.255.255. 0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:34 errors:0 dropped:0 overruns:0 frame:0 TX packets:32 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:6765 (6.6 Kb) TX bytes:8753 (8.5 Kb) Interrupt:17 Base address:0x1080 lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 UP LOOPBACK RUNNING MTU:16436 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:0 (0.0 b) TX bytes:0 (0.0 b) [root@sakura root]# ping -c1 192.168.102.1 PING 192.168.102.1 (192.168.102.1) 56(84) bytes of data. 64 bytes from 192.168.102.1: icmp_seq=1 ttl=64 time=0.613 ms --- 192.168.102.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.613/0.613/0.613/0.000 ms |
| Пример 15.1. Настройка сетевых интерфейсов |
| Закрыть окно |
| [root@sakura root]# route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.102.0 * 255.255.255.0 U 0 0 0 eth0 127.0.0.0 * 255.0.0.0 U 0 0 0 lo [root@sakura root]# ping 209.173.53.26 connect: Network is unreachable [root@sakura root]# route add default gw 192.168.102.1 [root@sakura root]# route Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 192.168.102.0 * 255.255.255.0 U 0 0 0 eth0 127.0.0.0 * 255.0.0.0 U 0 0 0 lo default 192.168.102.1 0.0.0.0 UG 0 0 0 eth0 [root@sakura root]# ping 209.173.53.26 64 bytes from 209.173.53.26: icmp_seq=1 ttl=114 time=166 ms . . . |
| Пример 15.2. Добавление маршрутизатора по умолчанию |
| Закрыть окно |
| [root@sakura root]# ping www.ru ping: unknown host www.ru [root@sakura root]# cat /etc/resolv.conf [root@sakura root]# cat > /etc/resolv.conf domain nipponman.ru nameserver 192.168.102.1 [root@sakura root]# ping www.ru PING www.ru (194.87.0.50) 56(84) bytes of data. 64 bytes from www.ru (194.87.0.50): icmp_seq=1 ttl=55 time=84.3 ms . . . [root@sakura root]# update_chrooted conf |
| Пример 15.3. Определение домена и DNS-сервера |
| Закрыть окно |
| [root@sakura root]# ls -F /etc/sysconfig/ acpi framebuffer init network-scripts/ vlan apmd harddisk/ keyboard* nfs xfs autologin* harddisks keyboard.rpmnew pcmcia* xinetd bootsplash hotplug klogd rawdevices xinitrc clock* hwconf kudzu syslogd console/ i18n* mouse* system* consolefont* i18n.rpmnew network* usb |
| Пример 15.4. Каталог /etc/sysconfig |
| Закрыть окно |
| [root@sakura root]# cat /etc/sysconfig/network NETWORKING=yes HOSTNAME=sakura.nipponman.ru DOMAINNAME=nipponman.ru GATEWAY=192.168.102.1 |
| Пример 15.5. Настройка сети по умолчанию |
| Закрыть окно |
| [root@sakura root]# ls -F /etc/sysconfig/network- scripts/ README@ ifdown-ppp* ifup-ipv6* ifup-sl* ifcfg-eth0* ifdown-pre* ifup-ipx* net_cnx_pg* ifcfg-lo* ifdown-sit* ifup-plip* net_prog.default* ifdown@ ifdown-sl* ifup-plusb* net_resolv.default ifdown-aliases* ifup@ ifup-post* network-functions* ifdown-iptun* ifup-aliases* ifup-ppp* network-functions-ipv6* ifdown-ipv6* ifup-ctc* ifup-routes* ifdown-post* ifup-iptun* ifup-sit* |
| Пример 15.6. Каталог network-scripts |
| Закрыть окно |
| [root@sakura root]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 BOOTPROTO=static IPADDR=192.168.102.125 NETMASK=255.255.255.0 NETWORK=192.168.102.0 BROADCAST=192.168.102.255 ONBOOT=yes |
| Пример 15.7. Настройка интерфейса по умолчанию |
| Закрыть окно |
| debian!shogun$ ls -F /etc/network if-down.d/ if-pre-up.d/ ifstate.hotplug interfaces if-post-down.d/ ifstate if-up.d/ options |
| Пример 15.8. Настройка сети с применением схемы ".d" |
| Закрыть окно |
| [root@sakura root]# ifconfig lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 . . . [root@sakura root]# cat /etc/resolv.conf [root@sakura root]# /sbin/dhcpcd -h sakura -N eth0 dhcpcd.exe: interface eth0 has been configured with new IP=192.168.102.124 [root@sakura root]# ps gax | grep "dhcpcd" 1011 ? S 0:00 /sbin/dhcpcd -h sakura -N eth0 [root@sakura root]# cat /etc/resolv.conf nameserver 192.168.102.1 search nipponman.ru [root@sakura root]# ifconfig eth0 Link encap:Ethernet HWaddr 00:0C:29:56:C1:36 inet addr:192.168.102.124 Bcast:192.168.102.255 Mask:255.255.255.0 . . . |
| Пример 15.9. Использование dhcpcd |
| Закрыть окно |
| [root@sakura root]# cat /etc/sysconfig/network-scripts/ifcfg-eth0 DEVICE=eth0 BOOTPROTO=dhcp NETMASK=255.255.255.0 ONBOOT=yes |
| Пример 15.10.. Настройка интерфейса на DHCP по умолчанию |
| Закрыть окно |
| [root@sakura root]# ls /etc/ppp callback-client chap-secrets ip-up options.dialin peers callback-server ip-down ip-up.d options.dialout callback-users ip-down.d options pap-secrets [root@sakura root]# ls -l /etc/ppp/*secrets -rw------- 1 root root 78 Jun 23 1995 /etc/ppp/chap-secrets -rw------- 1 root root 77 Jun 23 1995 /etc/ppp/pap-secrets |
| Пример 15.11. Каталог с настройками PPP |
| Закрыть окно |
| [root@sakura root]# iptables-save # Generated by iptables-save v1.2. 11 on Fri Dec 24 21:06:12 2004 *nat :PREROUTING ACCEPT [1:261] :POSTROUTING ACCEPT [3:220] :OUTPUT ACCEPT [3:220] COMMIT # Completed on Fri Dec 24 21:06:12 2004 # Generated by iptables-save v1.2.11 on Fri Dec 24 21:06:12 2004 *filter :INPUT ACCEPT [7:1077] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [5:355] COMMIT # Completed on Fri Dec 24 21:06:12 2004 # Generated by iptables-save v1.2.11 on Fri Dec 24 21:06:12 2004 *mangle :PREROUTING ACCEPT [7:1077] :INPUT ACCEPT [7:1077] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [5:355] :POSTROUTING ACCEPT [5:355] COMMIT # Completed on Fri Dec 24 21:06:12 2004 |
| Пример 15.12. Пустые цепочки iptables |
| Закрыть окно |
| [root@sakura root]# iptables --append INPUT --in-interface lo --protocol tcp --destination-port quake --jump ACCEPT [root@sakura root]# iptables --append INPUT --protocol tcp --destination-port quake --jump REJECT [root@sakura root]# iptables-save . . . *filter :INPUT ACCEPT [1030:72984] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [730:69581] -A INPUT -i lo -p tcp -m tcp --dport 26000 -j ACCEPT -A INPUT -p tcp -m tcp --dport 26000 -j REJECT --reject-with icmp-port-unreachable COMMIT . . . [root@sakura root]# service iptables save saving current rules to /etc/sysconfig/iptables: [ DONE ] |
| Пример 15.13. Фильтрация TCP-запросов из сети |
| Закрыть окно |
| [root@fuji root]# route - n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 83.237.29.1 0.0.0.0 255.255.255.255 UH 0 0 0 ppp0 192.168.102.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1 10.13.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 127.0.0.0 0.0.0.0 255.0.0.0 U 0 0 0 lo 0.0.0.0 83.237.29.1 0.0.0.0 UG 0 0 0 ppp0 [root@fuji root]# iptables-save # Generated by iptables-save v1.2.11 on Sat Dec 25 14:02:44 2004 *nat :PREROUTING ACCEPT [216:12356] :POSTROUTING ACCEPT [242:27148] :OUTPUT ACCEPT [1428:91596] -A POSTROUTING -o ppp+ -j MASQUERADE COMMIT . . . |
| Пример 15.14. Использование простейшего преобразования адресов |
| Закрыть окно |
| [root@fuji root]# cat /proc/net/ip_conntrack . . . icmp 1 30 src=192.168.102.125 dst=209.173.53.26 type=8 code=0 id=50179 [UNREPLIED] src=209.173.53.26 dst=83.237.29.65 type=0 code=0 id=50179 use=1 tcp 6 431981 ESTABLISHED src=192.168.102.125 dst=194.87.0.50 sport=1027 dport=80 src=194.87.0.50 dst=83.237.29.65 sport=80 dport=1027 [ASSURED] use=1 |
| Пример 15.15. Просмотр таблицы подменяемых адресов |
| Закрыть окно |
| DirectoryIndex index.html index.htm index.shtml index.cgi AccessFileName .htaccess DocumentRoot "/var/www/html" Options Indexes Includes FollowSymLinks MultiViews AllowOverride None Order allow,deny Allow from all ScriptAlias /cgi-bin/ "/var/www/cgi-bin/" AllowOverride None Options ExecCGI Order deny,allow Deny from all Allow from 127.0.0.1 localhost |
| Пример 15.16. Отрывок конфигурационного файла apache |
| Закрыть окно |
Терминальный доступ
Текстовый интерфейс позволяет пользователю Linux работать на компьютере удаленно с помощью терминального клиента. Весьма удобно, находясь далеко от компьютера, управлять им самым естественным способом, с помощью командной строки. Препятствий этому немного: объем передаваемых по сети данных крайне невелик, ко времени отклика, занимающего полсекунды, вполне можно привыкнуть, а если оно меньше десятой доли секунды, то задержка и вовсе не мешает. Что необходимо соблюдать строго, так это шифрование учетных записей при подключении к удаленному компьютеру, а на самом деле, и самого сеанса терминальной связи, так как в нем вполне может "засветиться" пароль: например, пользователь заходит на удаленный компьютер и выполняет команду passwd.
Как уже говорилось в предыдущих лекциях, сначала для терминального доступа использовался протокол TELNET и соответствующая пара клиент-сервер telnet-telnetd. От них пришлось отказаться в силу их вопиющей небезопасности. На смену TELNET пришла служба Secure Shell ("Надежная оболочка"), также состоящая из пары клиент-сервер – ssh и sshd. Шифрование данных в Secure Shell организовано по принципу "асимметричных ключей", который позволяет более гибко шифровать или идентифицировать данные, чем более распространенный и привычный принцип "симметричных ключей". Симметричный ключ – это пароль, которым данные можно зашифровать, и с помощью него же потом расшифровать.
Упрощенно метод "асимметричных ключей" можно описать так. Используется алгоритм, при котором специальным образом выбранный пароль для шифрования данных не совпадает с соответствующим ему паролем для их расшифровки. Более того, зная любой из этих паролей, никак нельзя предугадать другой. Некто, желая, чтобы передаваемые ему данные нельзя было подсмотреть, раздает всем желающим шифрующий пароль со словами: "будете писать мне – шифруйте этим", т. е. делает этот пароль открытым. Дешифрующий пароль он хранит в строгой тайне, никому не открывая. В результате зашифровать данные его паролем может любой, а расшифровать (что и значит – подглядеть) – может только он. Цель достигнута.
Тот же принцип используется для создания так называемой электронной подписи, помогающей идентифицировать данные, то есть определить их автора. На этот раз открытым делается дешифрующий ключ (конечно, не тот, о котором только что шла речь, а еще один). Тогда любой, получив письмо и расшифровав его, может быть уверен, что письмо написал этот автор – потому что шифрующим ключом не владеет больше никто.
Здесь уместно сделать два замечания. Во-первых, алгоритмы шифрования с асимметричными ключами весьма ресурсоемки, поэтому в Secure Shell (и упомянутом ранее SSL) они используются только на начальном этапе установления соединения. Обмен данными шифруется симметричным ключом, но, поскольку сам этот ключ был защищен асимметричным, соединение считается надежным. Во-вторых этот кажущийся надежным алгоритм имеет серьезный изъян, с которым, впрочем, нетрудно справиться. Опасность таится в самом начале: как, получив от товарища открытый ключ, убедиться, что этот ключ действительно ему принадлежит? А вдруг по пути ключ был перехвачен злоумышленником, и до нас дошел уже его, злоумышленника, открытый ключ? Мы легкомысленно шифруем наши данные этим ключом, злоумышленник перехватывает их на обратном пути, просматривает их (только он и может это сделать, так как подсунул нам свой шифрующий пароль), и обманывает таким же манером товарища, притворяясь на этот раз нами.
Такая уязвимость называется "man-in-the-middle" (дословно "человек посередине"), своего рода "испорченный телефон". Существует два способа борьбы с ней. Первый: не доверять никаким открытым ключам, кроме тех, которые получил лично от товарища. Если с товарищем вы незнакомы, можете попросить у него удостоверение личности: а вдруг он все-таки злоумышленник? Второй способ: получить от товарища открытый ключ несколькими независимыми путями. В этом случае подойдет так называемый "отпечаток пальца" (fingerprint) – получаемая из ключа контрольная сумма такого размера, что подделать ее еще невозможно, но уже нетрудно сравнить с этой же контрольной суммой, размещенной на WWW-странице или присланной по электронной почте.